Large Model
2026-03-18
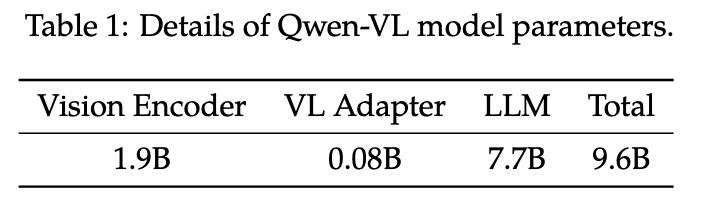
Qwen-VL 模型框架 Qwen-VL的整体网络架构由三个组件组成: LLM:使用 Qwen-7B 的预训练权重进行初始化。 视觉编码器:Qwen-VL 的可视化编码器使用ViT 架构,使用 Openclip 的 ViT-bigG 的预训练权重进行初始化。在训练和推理过程中,输入图像的大小都会调整为特定分辨率。视觉编码器通过以 14 步幅将图像分割成块来处理图像,生成一组图像特征。 位置感知视觉语言适配器:为了缓解长图像特征序列带来的效率问题,Qwen-VL 引入了一种视觉语言适配器来压缩图像特征。类似QFormer,该适配器包括一个随机初始化的单层交叉注意力模块。使用一组可训练向量(嵌入)作为query,并将视觉编码器中的图像特征作为交叉注意力作的key。该机制将视觉特征序列压缩到固定长度 256。 图像输入 图像不会直接以像素形式喂给语言模型(LLM)。 典型流程是: Visual Encoder :把图片编码成一串视觉特征(embedding/feature sequence)。 Adapter :把视觉特征映射到语言模型可接入的表征空间/维度。 最终得到:...