Large Model
2026-04-15
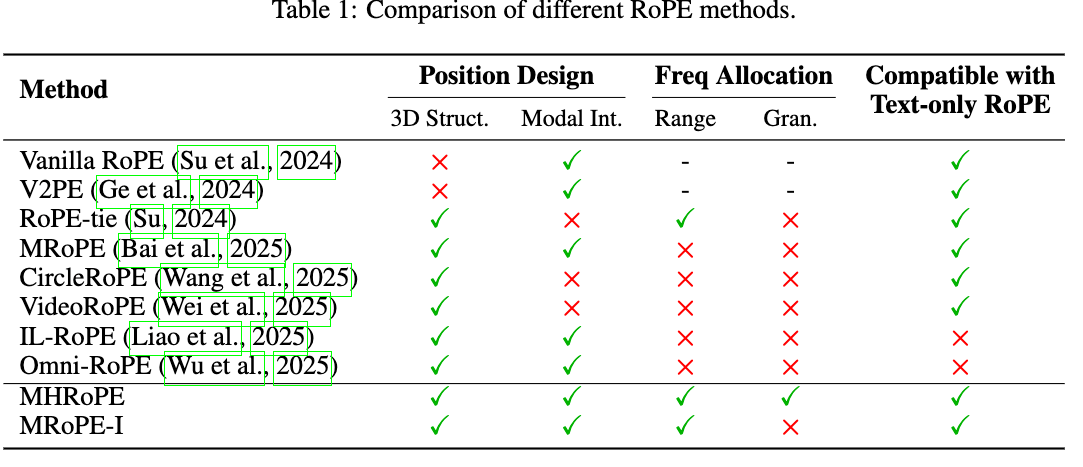
简介 论文: 《REVISITING MULTIMODAL POSITIONAL ENCODING IN VISION–LANGUAGE MODELS》 通过对多模态旋转位置嵌入(RoPE)的两个核心组件——位置设计和频率分配进行综合分析。通过实验,确定了三个关键指南:位置一致性、频率全利用和保留文本先验。基于这些见解,提出了多头RoPE(MHRoPE)和MRoPE-Interleave(MRoPE-I),这两种简单且即插即用的变体不需要任何架构更改。 为了构建更稳健的多模态位置编码,作者在MRoPE的基础上,系统地探索了三个未充分研究的方案: 位置设计——如何为文本和视觉标记分配无歧义、分离良好的坐标; 频率分配——如何将旋转频率分配到每个位置轴的嵌入维度; 与纯文本RoPE的兼容性——确保设计默认为标准RoPE,以便进行有效的迁移学习。 Vanilla RoPE RoPE与加性位置嵌入不同,RoPE对query和key向量应用旋转变换,从而将相对位置依赖直接纳入自注意力机制。给定位置 \(m\) 的查询向量 \(q\) 和位置 \(n\) 的键向量 \(k\) ,注意力分数...