Self-Supervised
2026-04-20
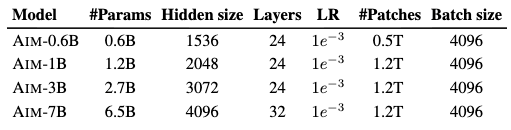
AIM v1 论文名称:Scalable Pre-training of Large Autoregressive Image Models (Arxiv 24.01) 论文地址: arxiv.org/pdf/2401.08541.pdf 代码地址: github.com/apple/ml-aim 简介 自回归预训练的大视觉模型会不会像 LLM 一样有缩放性质? 大语言模型 (LLM) 的革命性发展使得与任务无关的预训练成为自然语言处理任务的主流。大语言模型可以解决复杂的推理任务,遵从人类的指令,并且成为人工智能助手。LLM 成功的一个非常关键的因素是:随着模型容量和数据量的扩增,带来的模型能力的持续提升。 为什么大语言模型具有缩放性质?作者提出以下2点原因: 即使这些模型只使用最简单的目标函数进行 Next Token Prediction 的自回归预训练,它们也可以在复杂的上下文中学习到复杂的范式。 大语言模型的缩放性质是一些工作在 Transformer 架构中发现的,这也暗示了自回归预训练与 Transformer 架构之间的协同关系。 本文探索的目标是: 自回归预训练和...