Computer Vision
2026-04-15

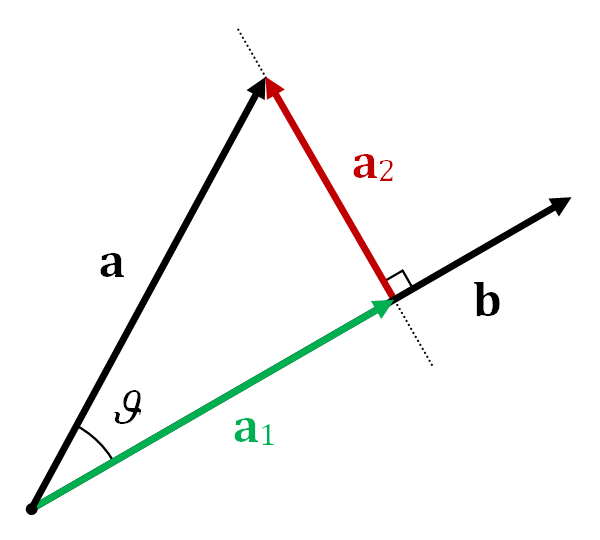
Introduction Inception 在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图: 于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。 Point-wise Conv 为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 \(1\times 1\) 卷积核,这就形成了 Inception V1 的最终网络结构,如下图。 这个 \(1\times1 \) 卷积就是 Pointwise Convolution ,简称 PW。利用它的目的主要是为了减少维度,还用于引入更多的非线性。 我们来简单计算下:假定上一层输出的 feature map 维度为 \(100\times 100 \times 128\) ,经过256个大小为 \(5\times5 \) 的卷积后,输出的 feature map...