76. 最小覆盖子串 题目 给定两个字符串 s 和 t ,长度分别是 m 和 n ,返回 s 中的 最短窗口 子串 ,使得该子串包含 t 中的每一个字符( 包括重复字符 )。如果没有这样的子串,返回空字符串 "" 。 测试用例保证答案唯一。 示例 1: 输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。 示例 2: 输入:s = "a", t = "a"
输出:"a"
解释:整个字符串 s 是最小覆盖子串。 示例 3: 输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。 提示: m == s.length n == t.length 1 <= m, n <= 10 5 s 和 t 由英文字母组成 题解 这是一个经典的 滑动窗口 (Sliding Window) 问题 我们需要维护一个动态的窗口 [left, right] : 右移扩大 :不断移动...
128. 最长连续序列 题目 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 示例 1: 输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。 示例 2: 输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9 示例 3: 输入:nums = [1,0,1,2]
输出:3 提示: 0 <= nums.length <= 10 5 -10 9 <= nums[i] <= 10 9 题解 我们需要在 \(O(1)\) 的时间内查找某个数是否存在。因此,首先将数组中的所有元素放入一个 HashSet 中。这不仅能去重,还能支持快速查找。 避免冗余计算 (关键优化) 如果我们对集合中的每一个数都尝试去向后计数(例如,对于 x ,尝试找 x+1 , x+2 ...),最坏情况下的时间复杂度会退化到 \(O(n^2)\) 。 优化策略 : 我们 只从序列的起点开始计数 。...
3D Model
2026-04-15

三维深度学习简介 多视角(multi-view):通过多视角二维图片组合为三维物体,此方法将传统CNN应用于多张二维视角的图片,特征被view pooling procedure聚合起来形成三维物体; 体素(volumetric):通过将物体表现为空间中的体素进行类似于二维的三维卷积(例如,卷积核大小为5x5x5),是规律化的并且易于类比二维的,但同时因为多了一个维度出来,时间和空间复杂度都非常高,目前已经不是主流的方法了; 点云(point clouds):直接将三维点云抛入网络进行训练,数据量小。主要任务有分类、分割以及大场景下语义分割; 非欧式(manifold,graph):在流形或图的结构上进行卷积,三维点云可以表现为mesh结构,可以通过点对之间临接关系表现为图的结构。 点云的特性 无序性...

概括 这篇文章将卷积比较自然地拓展到点云的情形,思路很赞! 文章的主要创新点:“weight function”和“density function”,并能实现translation-invariance和permutation-invariance,可以实现层级化特征提取,而且能自然推广到其deconvolution的情形实现分割,在二维CIFAR-10图像分类任务中精度堪比CNN(表明能够充分近似卷积网络),达到了SOTA的性能。 缺点:每个kernel都需要由“kernel function”生成,而“kernel function”实质上是一个CNN网络,计算量比较大。 思想 察觉到:二维卷积中pixel的相对centroid位置与kernel vector的生成方式有关。 以二维卷积为例说明一下如何将卷积拓展到点云。这里只考虑使用一个kernel在一个location的一次卷积操作。 对于二维图像,我们可以将图像的pixels看作是一个点,那么图像就是整齐排列的点阵。每个point都有维度为 \(C_{in}\)...

Hough Voting 本文的标题是Deep Hough Voting,先来说一下Hough Voting。 用Hough变换检测直线大家想必都听过:对于一条直线,可以使用 \((r,θ)\) 两个参数进行描述,那么对于图像中的一点,过这个点的直线有很多条,可以生成一系列的 \((r,θ)\) ,在参数平面内就是一条曲线,也就是说,一个点对应着参数平面内的一个曲线。那如果有很多个点,则会在参数平面内生成很多曲线。那么,如果这些点是能构成一条直线的,那么这条直线的参数 \((r,θ)\) 就在每条曲线中都存在,所以看起来就像是多条曲线相交在 \((r,θ)\) 。可以用多条曲线投票的方式来看,其他点都是很少的票数,而 \((r,θ)\) 则票数很多,所以直线的参数就是 \((r,θ)\) 。 所以Hough变换的思想就是在于,在参数空间内进行投票,投票得数高的就是要得到的值。 文中提到的Hough Voting如下: A traditional Hough voting 2D detector comprises an offline and an online step....
Reinforcement Learning
2026-04-15
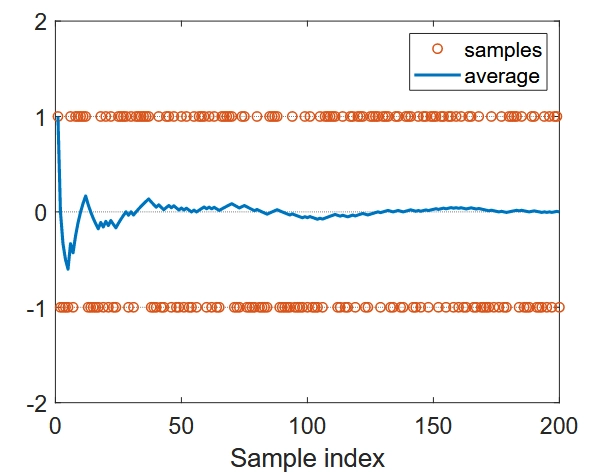
引言与背景 蒙特卡洛方法是强化学习中的重要算法类别,它标志着从基于模型到无模型算法的转变。这类算法不依赖环境模型,而是通过与环境的直接交互获取经验数据来学习最优策略。 蒙特卡洛方法在强化学习算法谱系中处于"无模型"方法的起始位置,是从基于模型的方法(如值迭代和策略迭代)向无模型方法过渡的第一步。 无模型强化学习的核心理念可以简述为: 如果没有模型,我们必须有数据;如果没有数据,我们必须有模型;如果两者都没有,我们就无法找到最优策略。在强化学习中,"数据"通常指智能体与环境交互的经验 。 均值估计问题 在介绍蒙特卡洛强化学习算法之前,我们首先需要理解均值估计问题,这是理解从数据而非模型中学习的基础。 考虑一个可以取有限实数集合 \(X\) 中值的随机变量 \(X\) ,我们的任务是计算 \(X\) 的均值或期望值: \(E[X]\) 有两种方法可以计算 \(E[X]\) : 基于模型的方法 :当已知随机变量的概率分布时,可以直接根据期望值的定义计算: \[E[X] = \sum_{x \in X} p(x) \cdot x\] 其中 \(p(x)\) 是 \(X\) 取值为 \(x\)...
Large Model
2026-04-15

引言 Structured Generation with LLM,是指 让LLM按照预先定义的schema,输出符合schema的结构化结果 。 常见的应用场景有: 数据处理 。主要功能为a -> b,即从源文本中 抽取/生成 符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等; Agent 。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参。 将 LLM 限制为始终生成符合特定模式的、有效的 JSON 或 YAML,是许多应用的关键功能。 Kor Kor ,一个 基于prompt的技术方案 ;Kor比较适合 数据处理 场景,且原理简单、易于理解,适合作为入门, 并且Kor适用于那些不支持function calling的比较旧的模型。 使用Kor进行structured generation的流程如下: 定义schema,包括结构、注释还有例子; Kor用特定的 prompt template ,将用户提供的schema和待处理的raw text,组装成prompt; 将prompt发送给LLM,借助其通用的In...
Reinforcement Learning
2026-04-15

引言 时序差分(Temporal-Difference,TD)方法是强化学习中的一类核心算法,它结合了动态规划与蒙特卡洛方法的优点。TD方法是无模型(model-free)学习方法,不需要环境模型即可学习价值函数和最优策略。 TD方法的核心特点是通过比较不同时间步骤的估计值之间的差异来更新价值函数,这种差异被称为"时序差分误差"(TD error)。TD方法可以被视为解决贝尔曼方程或贝尔曼最优方程的特殊随机逼近算法。 基础TD算法:状态值函数学习 给定策略 \(\pi\) ,基础TD算法用于估计状态值函数 \(v_\pi(s)\) 。假设我们有一些按照策略 \(\pi\) 生成的经验样本 \((s_0, r_1, s_1, ..., s_t, r_{t+1}, s_{t+1}, ...)\) ,TD算法的更新规则为: \[\begin{equation}\begin{aligned}v_{t+1}(s_t) &= v_t(s_t) - \alpha_t(s_t)[v_t(s_t) - (r_{t+1} + \gamma v_t(s_{t+1}))]\\
v_{t+1}(s) &=...
Reinforcement Learning
2026-04-15
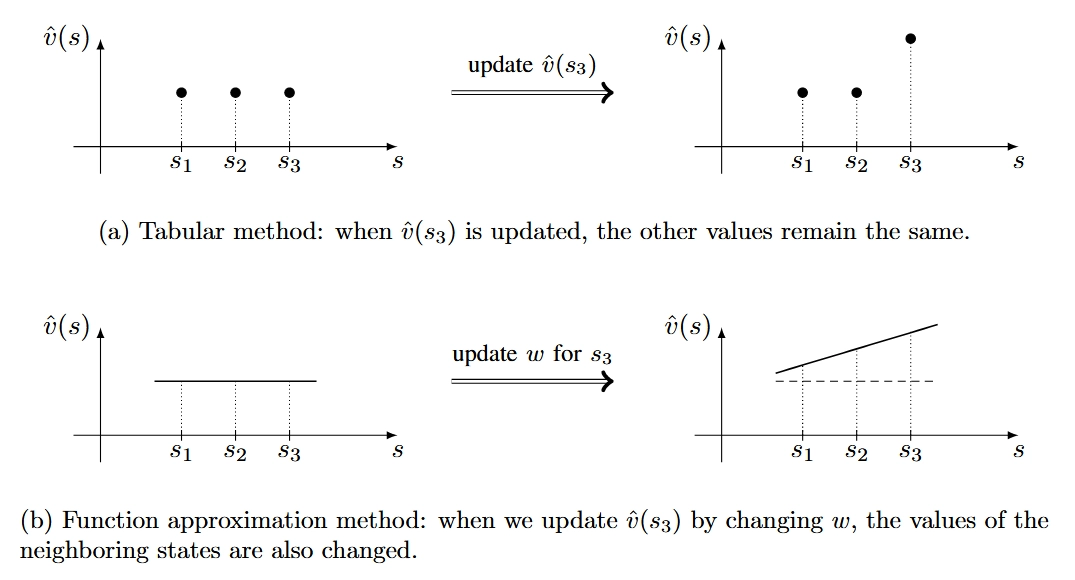
引言与背景 价值函数方法是强化学习中的核心技术,它解决了传统表格方法在处理大型状态或动作空间时的效率问题。本文探讨了从表格表示向函数表示的转变,这是强化学习算法发展的重要里程碑。 在强化学习的发展路径中,价值函数方法位于从基于模型到无模型、从表格表示到函数表示的演进过程中。它结合了时序差分学习的思想,并通过函数近似技术来处理复杂环境。 价值表示:从表格到函数 表格与函数表示的对比 传统的表格方法将状态值存储在一个表格中: 状态 \(s_1\) \(s_2\) \(\cdots\) \(s_n\) 估计值 \(\hat{v}(s_1)\) \(\hat{v}(s_2)\) \(\cdots\) \(\hat{v}(s_n)\) 而函数近似方法则使用参数化函数来表示这些值,例如: \[\hat{v}(s, w) = as + b = [s, 1] \begin{bmatrix} a \\ b \end{bmatrix} = \phi^T(s)w\] 其中 \(\phi(s)\in\mathbb{R}^2\) 称作是状态 \(s\) 的特征向量, \(w\) 是参数向量。...
Large Model
2026-04-15

引言与背景 FlashAttention的关键创新在于使用类似于在线Softmax的思想来对自注意力计算进行分块(tiling),从而能够融合整个多头注意力层的计算,而无需访问GPU全局内存来存储中间的logits和注意力分数 在深度学习中,Transformer模型的自注意力机制是计算密集型操作。传统实现需要在GPU全局内存中存储大量中间结果,这导致: 内存瓶颈 :中间矩阵占用大量显存 I/O开销 :频繁的全局内存访问降低效率 扩展性限制 :难以处理超长序列 FlashAttention通过算法创新解决了这些问题。 Self-Atention 自注意力机制的计算可以总结为(为简化说明,忽略头数和批次维度,也省略注意力掩码和缩放因子 \(\frac{1}{\sqrt{D}}\) ): \[O = \text{softmax}(QK^T)V\] 其中: \(Q, K, V, O\) 都是形状为 \((L, D)\) 的二维矩阵 \(L\) 是序列长度 \(D\) 是每个头的维度(头维度) softmax应用于最后一个维度(列) 标准计算流程, 传统方法将自注意力计算分解为几个阶段:...
Large Model
2026-04-15

通常我们训练神经网络模型的时候默认使用的数据类型为单精度FP32。近年来,为了加快训练时间、减少网络训练时候所占用的内存,并且保存训练出来的模型精度持平的条件下,业界提出越来越多的混合精度训练的方法。 这里的混合精度训练是指在训练的过程中,同时使用单精度(FP32)和半精度(FP16) 。 浮点数据类型 浮点数据类型主要分为双精度(FP64)、单精度(FP32)、半精度(FP16)。在神经网络模型的训练过程中,一般默认采用单精度(FP32)浮点数据类型,来表示网络模型权重和其他参数。在了解混合精度训练之前,这里简单了解浮点数据类型。 根据IEEE二进制浮点数算术标准(IEEE 754)的定义,浮点数据类型分为双精度(FP64)、单精度(FP32)、半精度(FP16)三种,其中每一种都有三个不同的位来表示。 FP64表示采用8个字节共64位,来进行的编码存储的一种数据类型; FP32表示采用4个字节共32位来表示; FP16则是采用2字节共16位来表示。 如图所示: 从图中可以看出,与FP32相比,FP16的存储空间是FP32的一半,FP32则是FP16的一半。主要分为三个部分:...
Large Model
2026-04-15

概述 投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 > 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。 下图左侧是自回归解码模型,右侧是投机解码机制。 从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地猜测出模型接下来要输出的token。作为对比,也有一种方案是通过路由的方式组合多个不同规模和性能的模型。路由方式在调用之前已经确定好需要调用哪个模型,直到调用结束。而投机解码在一个 Query 内会反复调用大小模型。 背景 我们都知道,生成式 LLM 大部分是 Decoder-only...