129. 滑动窗口最大值 题目 给你一个整数数组 nums ,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7 示例 2: 输入:nums = [1], k = 1
输出:[1] 提示: 1 <= nums.length...
Generative Model
2026-01-18

2022年中旬,以扩散模型为核心的图像生成模型将AI绘画带入了大众的视野。实际上,在更早的一年之前,就有了一个能根据文字生成高清图片的模型——VQGAN。VQGAN不仅本身具有强大的图像生成能力,更是传承了前作VQVAE把图像压缩成离散编码的思想,推广了「先压缩,再生成」的两阶段图像生成思路,启发了无数后续工作。 VQGAN 核心思想 VQGAN的论文名为 Taming Transformers for High-Resolution Image Synthesis,直译过来是「驯服Transformer模型以实现高清图像合成」。可以看出,该方法是在用Transformer生成图像。可是,为什么这个模型叫做VQGAN,是一个GAN呢?这是因为,VQGAN使用了两阶段的图像生成方法: 训练时,先训练一个图像压缩模型(包括编码器和解码器两个子模型),再训练一个生成压缩图像的模型。 生成时, 先用第二个模型生成出一个压缩图像,再用第一个模型复原成真实图像 。 其中,第一个图像压缩模型叫做VQGAN,第二个压缩图像生成模型是一个基于Transformer的模型。...
Generative Model
2026-01-18
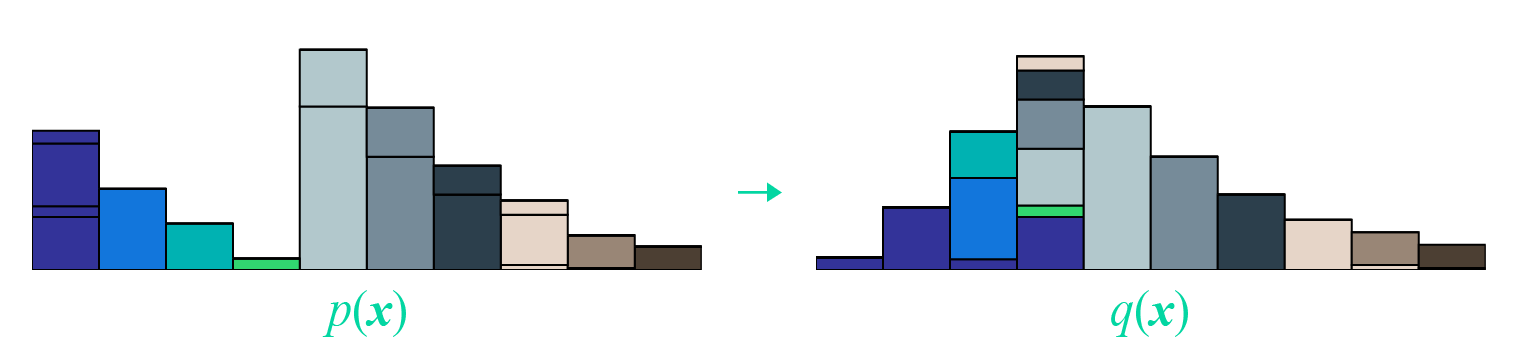
本文受启发于著名的国外博文 《Wasserstein GAN and the Kantorovich-Rubinstein Duality》 ,内容跟它大体上相同,但是删除了一些冗余的部分,对不够充分或者含糊不清的地方作了补充。 Wasserstein距离 显然,整篇文章必然围绕着Wasserstein距离( \(\mathcal{W}\) 距离)来展开。假设我们有了两个概率分布 \(p(x),q(x)\) ,那么Wasserstein距离的定义为 \[\mathcal{W}[p,q]=\inf_{\gamma\in \Pi[p,q]} \iint \gamma(\boldsymbol{x},\boldsymbol{y}) d(\boldsymbol{x},\boldsymbol{y}) d\boldsymbol{x}d\boldsymbol{y}\] 事实上,这也算是最优传输理论中最核心的定义了。 成本函数 首先 \(d(x,y)\) ,它不一定是距离,其准确含义应该是一个成本函数,代表着从 \(x\) 运输到 \(y\) 的成本。常用的 \(d\) 是基于 \(l\)...

简介 生成对抗网络 ( Generative Adversarial Network, GAN ) 是由 Goodfellow 于 2014 年提出的一种对抗网络。这个网络框架包含两个部分,一个生成模型 (generative model) 和一个判别模型 (discriminative model)。其中,生成模型可以理解为一个伪造者,试图通过构造假的数据骗过判别模型的甄别;判别模型可以理解为一个警察,尽可能甄别数据是来自于真实样本还是伪造者构造的假数据。两个模型都通过不断的学习提高自己的能力,即生成模型希望生成更真的假数据骗过判别模型,而判别模型希望能学习如何更准确的识别生成模型的假数据。 网络框架 GAN 由两部分构成,一个 生成器 ( Generator ) 和一个 判别器 ( Discriminator )。对于生成器,我们需要学习关于数据 \(x\) 的一个分布 \(p_g\) ,首先定义一个输入数据的先验分布 \(p_z(z)\) ,其次定义一个映射 \(G \left(\boldsymbol{z}; \theta_g\right): \boldsymbol{z}...
Computer Vision
2026-01-11

在正式介绍之前,先简单回顾一下现有的两大类方法。第一大类,也是从非Deep时代,乃至CV初期就被就被广泛使用的方法叫做image pyramid。在image pyramid中,我们直接对图像进行不同尺度的缩放,然后将这些图像直接输入到detector中去进行检测。虽然这样的方法十分简单,但其效果仍然是最佳,也后续启发了SNIP这一系列的工作。单论性能而言,multiscale training/testing仍然是一个不可缺少的组件。然而其缺点也是很明显的,测试时间大幅度提高,对于实际使用并不友好。 另外一大类方法,也是Deep方法所独有的,也就是feature pyramid。最具代表性的工作便是经典的FPN了。这一类方法的思想是直接在feature层面上来近似image pyramid...
Computer Vision
2026-01-11
在深度学习目标检测中,特别是人脸检测中,由于分辨率低、图像模糊、信息少、噪声多,小目标和小人脸的检测一直是一个实用和常见的难点问题。然而,在过去几年的发展中,也出现了一些提高小目标检测性能的解决方案。本文将对这些方法进行分析、整理和总结。 图像金字塔和多尺度滑动窗口检测 一开始,在深学习方法成为流行之前,对于不同尺度的目标,通常是从原始图像开始,使用不同的分辨率构建图像金字塔,然后使用分类器对金字塔的每一层进行滑动窗口的目标检测。 在著名的人脸检测器MTCNN中,使用图像金字塔法检测不同分辨率的人脸目标。然而,这种方法通常是缓慢的,虽然构建图像金字塔可以使用卷积核分离加速或简单粗暴地缩放,但仍需要做多个特征提取,后来有人借其想法想出一个特征金字塔网络FPN,在不同层融合特征,只需要一次正向计...
Computer Vision
2026-01-11
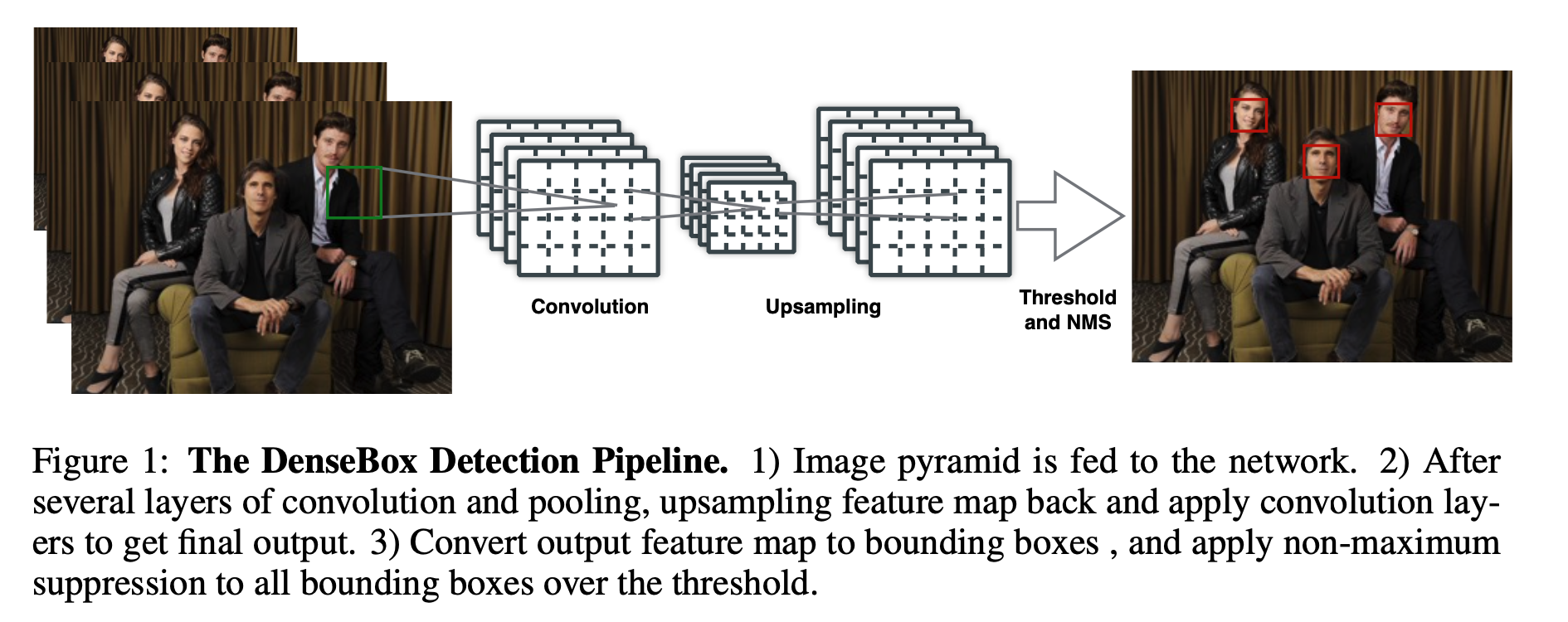
简介 "Anchorfree"(无锚点)是一种目标检测方法,与传统的使用锚框(anchor boxes)的方法(例如Faster RCNN)不同。在传统方法中,锚框是预先定义的、具有不同尺寸和长宽比的矩形区域,用于捕捉不同尺寸和形状的目标。而在"anchorfree"方法中,不再使用锚框,而是直接预测目标的位置和形状,通常使用网络输出的热图和偏移信息。 以下是对"anchorfree"方法的一些关键理解点: 无需预定义锚框: 在传统目标检测方法中,需要事先定义和生成一组锚框,这可能需要大量的人工工作。而在"anchorfree"方法中,不再需要锚框,模型可以自动学习目标的位置和形状。 直接位置和形状回归: "anchorfree"方法通过输出的热图来表示目标的存在概率,并使用偏移信息来定位目...
Computer Vision
2026-01-11
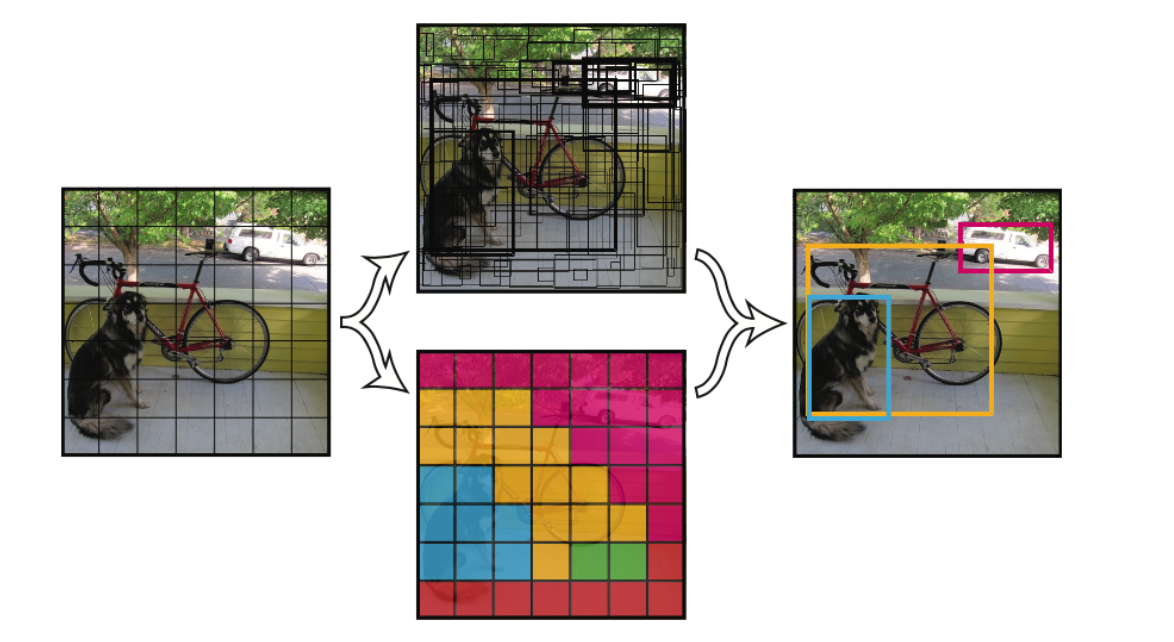
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。 faster RCNN中也直接用整张图作为输入,但是fasterRCNN整体还是采用了RCNN那种 proposal+classifier的思想,只不过是将提取proposal的步骤放在CNN中实现了,而YOLO则采用直接回归的思路。 YOLO v1 将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。 每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。 这个confidence代表了所预测的b...
Computer Vision
2026-01-11
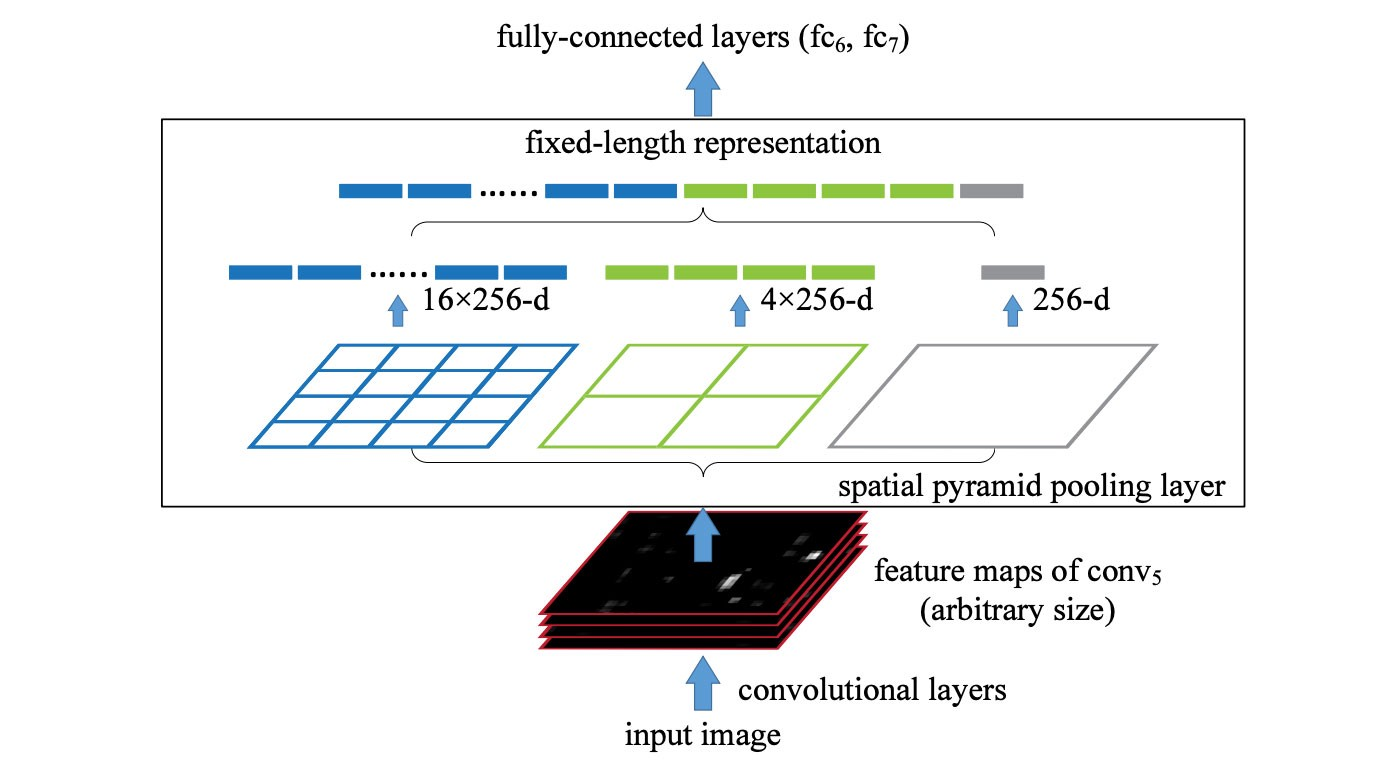
SPP (spatial pyramid pooling layer) SPP applies a slightly different strategy in detecting objects of different scales. It replaces the last pooling layer (after the last convolutional layer) with a spatial pyramid pooling layer. The feature maps are spatially divided into m×m bins with m, say, equals 1, 2, and 4 respectively. Then a maximum pool i...
Computer Vision
2026-01-11

原理分析 网络架构: 本文的任务是Object detection,用到的工具是Transformers,特点是Endtoend。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他...
Computer Vision
2026-01-11

一、IOU(Intersection over Union) 1. 特性(优点) IoU就是我们所说的交并比,是目标检测中最常用的指标,在anchorbased的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和groundtruth的距离。 1. 可以说它可以反映预测检测框与真实检测框的检测效果。 1. 还有一个很好的特性就是尺度不变性,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。(满足非负性;同一性;对称性;三角不等性) [代码] 2. 作为损失函数会出现的问题(缺点) 1. 如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重...
Computer Vision
2026-01-11

Introduction 目标检测中NMS需要依据候选检测目标的排序来进行筛选框,如果分类得分较低,但是定位框准确会导致在NMS中将该bbox框被排除掉,因此这个排序的可靠性就非常重要。之前的工作主要采用IOU分支(IOUNet)与Centerness得分(FCOS)来作为大量候选检测的排序依据。 然而,本文认为这些方法可以有效缓解分类得分和物体定位精度之间的不对齐问题。 但是,它们是次优解的,因为将两个不完善的预测相乘可能会导致排名依旧变差,作者经过试验表明,通过这种方法实现的性能上限非常有限。 此外,增加一个额外的网络分支来预测定位分数并不是一个很好的解决方案,并且会带来额外的计算负担。 基于上述分析,作者提出:不采用预测一个额外的定位精确度得分(IOUaware Centerness)...