
泊松分布 日常生活中,大量事件是有固定频率的。 某医院平均每小时出生3个婴儿 某公司平均每10分钟接到1个电话 某超市平均每天销售4包xx牌奶粉 某网站平均每分钟有2次访问 它们的特点就是,我们可以预估这些事件的总数,但是没法知道具体的发生时间。已知平均每小时出生3个婴儿,请问下一个小时,会出生几个? 有可能一下子出生6个,也有可能一个都不出生。这是我们没法知道的。 泊松分布就是描述某段时间内,事件具体的发生概率。 \[P(N(t)=n)=\frac{(\lambda t)^n e^{-\lambda t}}{n!}\] 上面就是泊松分布的公式。等号的左边, \(P\) 表示概率, \(N\) 表示某种函数关系, \(t\) 表示时间, \(n\) 表示数量,1小时内出生3个婴儿的概率,就表示为 \(P(N(1) = 3)\) 。等号的右边,参数λ是单位时间(或单位面积)内随机事件的平均发生率。 接下来两个小时,一个婴儿都不出生的概率是0.25%,基本不可能发生。 \[P(N(2) = 0) = \frac{(3 \times 2)^0 e^{-3 \times 2}}{0!}...
基本概念 方向导数:是一个数;反映的是 \(f(x,y)\) 在 \(P_0\) 点沿方向 \(v\) 的变化率。 偏导数:是多个数(每元有一个);是指多元函数沿坐标轴方向的 方向导数 ,因此二元函数就有两个偏导数。 偏导函数:是一个函数;是一个关于点的偏导数的函数。 梯度:是一个向量;每个元素为函数对一元变量的偏导数;它既有大小(其大小为最大方向导数),也有方向。 方向导数 反映的是 \(f(x,y)\) 在 \(P_0\) 点沿方向 \(v\) 的变化率。 例子如下: 题目 设二元函数 \( f(x, y) = x^2 + y^2\) ,分别计算此函数在点 \((1, 2)\) 沿方向 \(w=\{3, -4\}\) 与方向 \(u=\{1, 0\}\) 的方向导数。 解: 由于 \(w\) 不是单位向量,因此首先应对其进行单位化: \[v = w^0 = \frac{w}{|w|} = \left\{ \frac{3}{5}, -\frac{4}{5} \right\}\] 计算函数增量: \[\begin{aligned}
\therefore f(x_0 + tv_1,...
问题表示 有很多概率问题,尤其是独立重复实验问题,如果用生成函数的方法来做,会显得特别方便。本文要讲的“随机游走”问题便是其中一例,它又被形象地叫做“醉汉问题”,其本质上是一个二项分布,但是由于取了极限,出现了很多新的性质和应用。我们先考虑如下问题: 考虑实数轴上的一个粒子,在 \(t=0\) 时刻它位于原点,每过一秒,它要不向前移动一格( \(+1\) ),要不就向后移动一格( \(-1\) ),问 \(n\) 秒后它所处位置的概率分布。 不难发现,这个问题跟二项分布是雷同的。如果把这个粒子形象比喻成一个“喝醉酒的人”,那么上面的走法就类似于一个完全不省人事的醉汉走路问题了。(当然,醉汉是在三维空间走路的,这里简单起见,只描述了一维的。)这是一个独立重复实验,每秒的行走可用函数描述为 \(\frac{1}{2}(z+z^{-1})\) ,于是 \(n\) 秒后的运动分布情况可以用 \[\frac{1}{2^n}(z+z^{-1})^n\] 来描述, \(z^i(i=-n,-n+1,\dots,n-1,n)\) 的系数表示粒子位于 \(i\) 的概率。 💡...
Math
2026-04-15

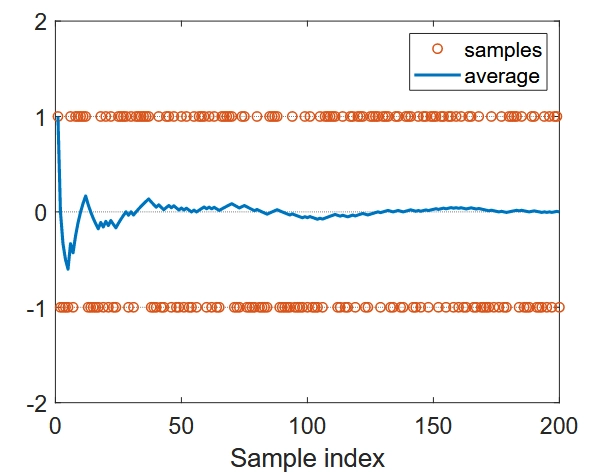
引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 \(X\) ,其取值来自有限集合 \(\mathcal{X}\) 。我们的目标是估计 \(E[X]\) 。假设我们有一个独立同分布的样本序列 \(\{x_i\}_{i=1}^n\) ,那么 \(X\) 的期望值可以近似为: \[E[X] \approx \bar{x} = \frac{1}{n}\sum_{i=1}^n x_i\] 非增量方法与增量方法 非增量方法 :先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法 :定义 \[w_{k+1} = \frac{1}{k}\sum_{i=1}^k x_i, k = 1, 2, ...\] 可以推导出递归公式: \[{w}_{k + 1} =...
Reinforcement Learning
2026-04-15
引言与背景 蒙特卡洛方法是强化学习中的重要算法类别,它标志着从基于模型到无模型算法的转变。这类算法不依赖环境模型,而是通过与环境的直接交互获取经验数据来学习最优策略。 蒙特卡洛方法在强化学习算法谱系中处于"无模型"方法的起始位置,是从基于模型的方法(如值迭代和策略迭代)向无模型方法过渡的第一步。 无模型强化学习的核心理念可以简述为: 如果没有模型,我们必须有数据;如果没有数据,我们必须有模型;如果两者都没有,我们就无法找到最优策略。在强化学习中,"数据"通常指智能体与环境交互的经验 。 均值估计问题 在介绍蒙特卡洛强化学习算法之前,我们首先需要理解均值估计问题,这是理解从数据而非模型中学习的基础。 考虑一个可以取有限实数集合 \(X\) 中值的随机变量 \(X\) ,我们的任务是计算 \(X\) 的均值或期望值: \(E[X]\) 有两种方法可以计算 \(E[X]\) : 基于模型的方法 :当已知随机变量的概率分布时,可以直接根据期望值的定义计算: \[E[X] = \sum_{x \in X} p(x) \cdot x\] 其中 \(p(x)\) 是 \(X\) 取值为 \(x\)...
Reinforcement Learning
2026-04-15

引言 DDPG同样使用了Actor-Critic的结构,Deterministic的确定性策略是和随机策略相对而言的,对于某一些动作集合来说,它可能是连续值,或者非常高维的离散值,这样动作的空间维度极大。如果我们使用随机策略,即像DQN一样研究它所有的可能动作的概率,并计算各个可能的动作的价值的话,那需要的样本量是非常大才可行的。于是有人就想出使用确定性策略来简化这个问题。 作为随机策略,在相同的策略,在同一个状态 \(s\) 处,采用的动作 \(\pi_\theta(a|s)\) 是基于一个概率分布的,即是不确定的。而确定性策略则决定简单点,虽然在同一个状态处,采用的动作概率不同,但是最大概率只有一个,如果我们只取最大概率的动作,去掉这个概率分布,那么就简单多了。即作为确定性策略,相同的策略,在同一个状态处,动作是唯一确定的,即策略变成 \[a = \mu(s, \theta)\] 所以DDPG基于确定性策略梯度(DPG)算法,结合了DQN的成功经验。 使用回放缓冲区中的样本进行离策略训练,以减少样本之间的相关性 使用目标Q网络在时序差分更新过程中提供一致的目标...
Large Model
2026-04-15

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
NLP
2026-04-15
概述 HiPPO(High-order Polynomial Projection Operators)是目前大热的structured state space model (S4)及其后续工作的backbone. State space mode主要是控制学科里的内容,最近被引入深度学习领域来解决长距离依赖问题。长距离依赖建模的核心问题是如何通过有限的memory来尽可能记住之前所有的历史信息。当前的主流序列建模模型(即Transformer和RNN) 存在着普遍的遗忘问题 fixed-size context windows: Transformer的window size通常是有限的,一般来说quadratic的attention最多建模到大约10k的token就到计算极限了 vanishing gradient: RNN通过hidden state来存储历史信息,理论上能记住之前所有内容,但实际上的effective memory大概是<1k个token的level,可能的原因是gradient vanishing HiPPO 通过数学方法分析来得到closed-form...
Large Model
2026-04-15

引言 Structured Generation with LLM,是指 让LLM按照预先定义的schema,输出符合schema的结构化结果 。 常见的应用场景有: 数据处理 。主要功能为a -> b,即从源文本中 抽取/生成 符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等; Agent 。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参。 将 LLM 限制为始终生成符合特定模式的、有效的 JSON 或 YAML,是许多应用的关键功能。 Kor Kor ,一个 基于prompt的技术方案 ;Kor比较适合 数据处理 场景,且原理简单、易于理解,适合作为入门, 并且Kor适用于那些不支持function calling的比较旧的模型。 使用Kor进行structured generation的流程如下: 定义schema,包括结构、注释还有例子; Kor用特定的 prompt template ,将用户提供的schema和待处理的raw text,组装成prompt; 将prompt发送给LLM,借助其通用的In...
Reinforcement Learning
2026-04-15

引言 时序差分(Temporal-Difference,TD)方法是强化学习中的一类核心算法,它结合了动态规划与蒙特卡洛方法的优点。TD方法是无模型(model-free)学习方法,不需要环境模型即可学习价值函数和最优策略。 TD方法的核心特点是通过比较不同时间步骤的估计值之间的差异来更新价值函数,这种差异被称为"时序差分误差"(TD error)。TD方法可以被视为解决贝尔曼方程或贝尔曼最优方程的特殊随机逼近算法。 基础TD算法:状态值函数学习 给定策略 \(\pi\) ,基础TD算法用于估计状态值函数 \(v_\pi(s)\) 。假设我们有一些按照策略 \(\pi\) 生成的经验样本 \((s_0, r_1, s_1, ..., s_t, r_{t+1}, s_{t+1}, ...)\) ,TD算法的更新规则为: \[\begin{equation}\begin{aligned}v_{t+1}(s_t) &= v_t(s_t) - \alpha_t(s_t)[v_t(s_t) - (r_{t+1} + \gamma v_t(s_{t+1}))]\\
v_{t+1}(s) &=...
Reinforcement Learning
2026-04-15

概述与理论背景 Actor-Critic方法是强化学习中的一类重要算法, 它巧妙地结合了基于策略(policy-based)和基于价值(value-based)的方法 。在这种结构中, "Actor"指策略更新步骤,负责根据策略执行动作;而"Critic"指价值更新步骤,负责评估Actor的表现 。从另一个角度看,Actor-Critic方法本质上仍是策略梯度算法,可以通过扩展策略梯度算法获得。 Actor-Critic方法在强化学习中的位置非常重要,它既保留了策略梯度方法直接优化策略的优势,又利用了值函数方法的效率。这种结合使得Actor-Critic方法成为解决复杂强化学习问题的强大工具。 最简单的Actor-Critic算法(QAC) QAC算法通过扩展策略梯度方法得到。策略梯度方法的核心思想是通过最大化标量度量 \(J(\theta)\) 来搜索最优策略。其梯度上升算法为: \[\begin{equation}\begin{aligned}\theta_{t+1} &= \theta_t + \alpha\nabla_\theta J(\theta_t)\\&=...

引言与背景 策略梯度方法是强化学习中的一种重要方法,它标志着从基于价值的方法向基于策略的方法的重要转变。之前我们主要讨论了基于价值的方法(value-based),而策略梯度方法则直接优化策略函数(policy-based),这是一个重要的进步。 当策略用函数表示时,策略梯度方法的核心思想是 通过优化某些标量指标来获得最优策略 。与传统的表格表示策略不同,策略梯度方法使用参数化函数 \(\pi(a|s, \theta)\) 来表示策略,其中 \(\theta \in \mathbb{R}^m\) 是参数向量。这种表示方法也可以写成其他形式,如 \(\pi_\theta(a|s)\) 、 \(\pi_\theta(a, s)\) 或 \(\pi(a, s, \theta)\) 。 策略梯度方法具有多种优势: 更高效地处理大型状态/动作空间 具有更强的泛化能力 样本使用效率更高 策略表示:从表格到函数 当策略的表示从表格转变为函数时,存在以下几个关键区别: 最优策略的定义 : 表格表示:最优策略是使每个状态值最大化的策略 函数表示:最优策略是使某些标量指标最大化的策略 策略更新方式 :...