
Tokenizer 背景与基础 目前的机器学习模型都是数学模型,其对应的输入要求必须是数字形式(number)的,而我们处理的真实场景往往会包含许多非数字形式的输入(有时候即使原始输入是数字形式,我们也需要转换),最典型的就是 NLP 中的文字(string),为了让文字能够作为输入参与到模型的计算中去,我们就需要构建一个映射关系(mapping):将对应的文字映射到一个数字形式上去,而其对应的数字就是 token。而对应的这个映射关系,就是我们的 tokenizer:他可以将文字映射到其对应的数字上去(encode),也可以将数字映射回对应的文字上(decode)。 诸如GPT-3/4以及LlaMA/LlaMA2大语言模型都采用了token的作为模型的输入输出,其输入是文本,然后将文本转为token(正整数),然后从一串token(对应于文本)预测下一个token。 进入OpenAI官网提供的tokenizer可以看到GPT-3tokenizer采用的方法。这里以Hello World为例说明。...
Generative Model
2026-04-15

2022年中旬,以扩散模型为核心的图像生成模型将AI绘画带入了大众的视野。实际上,在更早的一年之前,就有了一个能根据文字生成高清图片的模型——VQGAN。VQGAN不仅本身具有强大的图像生成能力,更是传承了前作VQVAE把图像压缩成离散编码的思想,推广了「先压缩,再生成」的两阶段图像生成思路,启发了无数后续工作。 VQGAN 核心思想 VQGAN的论文名为 Taming Transformers for High-Resolution Image Synthesis,直译过来是「驯服Transformer模型以实现高清图像合成」。可以看出,该方法是在用Transformer生成图像。可是,为什么这个模型叫做VQGAN,是一个GAN呢?这是因为,VQGAN使用了两阶段的图像生成方法: 训练时,先训练一个图像压缩模型(包括编码器和解码器两个子模型),再训练一个生成压缩图像的模型。 生成时, 先用第二个模型生成出一个压缩图像,再用第一个模型复原成真实图像 。 其中,第一个图像压缩模型叫做VQGAN,第二个压缩图像生成模型是一个基于Transformer的模型。...
Generative Model
2026-04-15
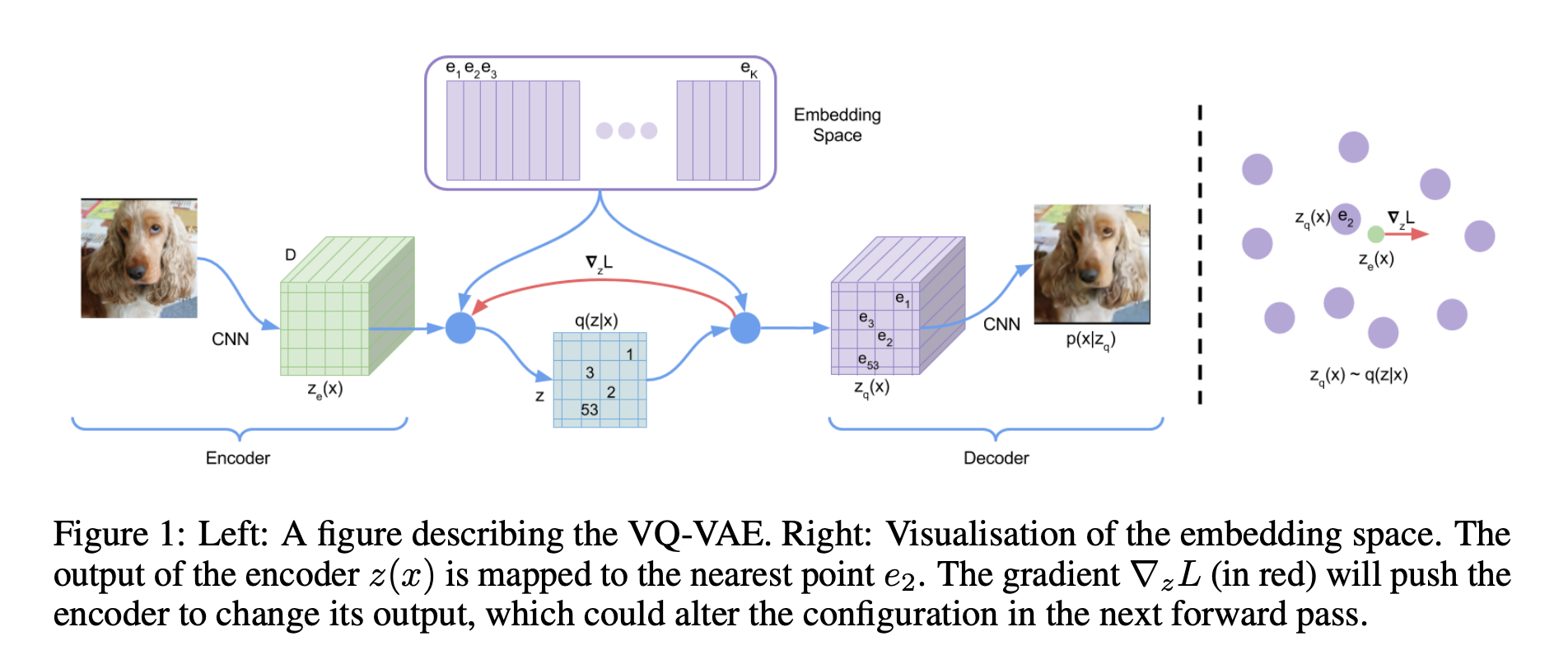
简介 作为一个自编码器,VQ-VAE的一个明显特征是它编码出的编码向量是离散的,换句话说, 它最后得到的编码向量的每个元素都是一个整数 ,这也就是“Quantised”的含义,我们可以称之为“量子化”(跟量子力学的“量子”一样,都包含离散化的意思)。 明明整个模型都是连续的、可导的,但最终得到的编码向量却是离散的,并且重构效果看起来还很清晰(如文章开头的图),这至少意味着VQ-VAE会包含一些有意思、有价值的技巧,值得我们学习一番。 首先, VQ-VAE其实就是一个AE(自编码器)而不是VAE(变分自编码器) ,我不知道作者出于什么目的非得用概率的语言来沾VAE的边,这明显加大了读懂这篇论文的难度。其次,VQ-VAE的核心步骤之一是Straight-Through Estimator,这是将引变量离散化后的优化技巧,在原论文中没有稍微详细的讲解,以至于必须看源码才能更好地知道它说啥。最后,论文的核心思想也没有很好地交代清楚,给人的感觉是纯粹在介绍模型本身而没有介绍模型思想。 PixelCNN...
Deep Learning
2026-04-15

文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。 基本概念 重参数(Reparameterization) 实际上是处理如下期望形式的目标函数的一种技巧: \[L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\tag{1}\] 这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现( \(f(z)\) 对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于 \(z\) 的连续性,它对应不同的形式: \[\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\tag{2}\] 当然,离散情况下我们更喜欢将记号 \(z\) 换成 \(y\) 或者 \(c\) 。 为了最小化...
Reinforcement Learning
2026-04-15

引言 DDPG同样使用了Actor-Critic的结构,Deterministic的确定性策略是和随机策略相对而言的,对于某一些动作集合来说,它可能是连续值,或者非常高维的离散值,这样动作的空间维度极大。如果我们使用随机策略,即像DQN一样研究它所有的可能动作的概率,并计算各个可能的动作的价值的话,那需要的样本量是非常大才可行的。于是有人就想出使用确定性策略来简化这个问题。 作为随机策略,在相同的策略,在同一个状态 \(s\) 处,采用的动作 \(\pi_\theta(a|s)\) 是基于一个概率分布的,即是不确定的。而确定性策略则决定简单点,虽然在同一个状态处,采用的动作概率不同,但是最大概率只有一个,如果我们只取最大概率的动作,去掉这个概率分布,那么就简单多了。即作为确定性策略,相同的策略,在同一个状态处,动作是唯一确定的,即策略变成 \[a = \mu(s, \theta)\] 所以DDPG基于确定性策略梯度(DPG)算法,结合了DQN的成功经验。 使用回放缓冲区中的样本进行离策略训练,以减少样本之间的相关性 使用目标Q网络在时序差分更新过程中提供一致的目标...
Generative Model
2026-04-15

简介 如果以概率的视角看待世界的生成模型。 在这样的世界观中,我们可以将任何类型的观察数据(例如 \(D\) )视为来自底层分布(例如 \( p_{data}\) )的有限样本集。 任何生成模型的目标都是在访问数据集 \(D\) 的情况下近似该数据分布。 如果我们能够学习到一个好的生成模型,我们可以将学习到的模型用于下游推理。 我们主要对数据分布的参数近似感兴趣,在一组有限的参数中,它总结了关于数据集 \(D\) 的所有信息。 与非参数模型相比,参数模型在处理大型数据集时能够更有效地扩展,但受限于可以表示的分布族。 在参数的设置中,我们可以将学习生成模型的任务视为在模型分布族中挑选参数,以最小化模型分布和数据分布之间的距离。 如上图,给定一个狗的图像数据集,我们的目标是学习模型族 \(M\) 中生成模型 θ 的参数,使得模型分布 \(p_θ\) 接近 \(p_{data}\) 上的数据分布。 在数学上,我们可以将我们的目标指定为以下优化问题: \[\mathop{min}\limits_{\theta\in M}d(p_\theta,p_{data})\] 其中, \(d()\)...
Large Model
2026-04-15

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
Generative Model
2026-04-15

分布变换 通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量 \(Z\) 生成目标数据 \(X\) 的模型,但是实现上有所不同。更准确地讲,它们是假设了 \(Z\) 服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型 \(X=g(Z)\) ,这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。 生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式 那现在假设 \(Z\) 服从标准的正态分布,那么我就可以从中采样得到若干个 \(Z_1, Z_2, \dots, Z_n\) ,然后对它做变换得到 \(\hat{X}_1 = g(Z_1),\hat{X}_2 = g(Z_2),\dots,\hat{X}_n = g(Z_n)\) ,我们怎么判断这个通过 \(g\)...
Reinforcement Learning
2026-04-15

概述与理论背景 Actor-Critic方法是强化学习中的一类重要算法, 它巧妙地结合了基于策略(policy-based)和基于价值(value-based)的方法 。在这种结构中, "Actor"指策略更新步骤,负责根据策略执行动作;而"Critic"指价值更新步骤,负责评估Actor的表现 。从另一个角度看,Actor-Critic方法本质上仍是策略梯度算法,可以通过扩展策略梯度算法获得。 Actor-Critic方法在强化学习中的位置非常重要,它既保留了策略梯度方法直接优化策略的优势,又利用了值函数方法的效率。这种结合使得Actor-Critic方法成为解决复杂强化学习问题的强大工具。 最简单的Actor-Critic算法(QAC) QAC算法通过扩展策略梯度方法得到。策略梯度方法的核心思想是通过最大化标量度量 \(J(\theta)\) 来搜索最优策略。其梯度上升算法为: \[\begin{equation}\begin{aligned}\theta_{t+1} &= \theta_t + \alpha\nabla_\theta J(\theta_t)\\&=...

引言与背景 策略梯度方法是强化学习中的一种重要方法,它标志着从基于价值的方法向基于策略的方法的重要转变。之前我们主要讨论了基于价值的方法(value-based),而策略梯度方法则直接优化策略函数(policy-based),这是一个重要的进步。 当策略用函数表示时,策略梯度方法的核心思想是 通过优化某些标量指标来获得最优策略 。与传统的表格表示策略不同,策略梯度方法使用参数化函数 \(\pi(a|s, \theta)\) 来表示策略,其中 \(\theta \in \mathbb{R}^m\) 是参数向量。这种表示方法也可以写成其他形式,如 \(\pi_\theta(a|s)\) 、 \(\pi_\theta(a, s)\) 或 \(\pi(a, s, \theta)\) 。 策略梯度方法具有多种优势: 更高效地处理大型状态/动作空间 具有更强的泛化能力 样本使用效率更高 策略表示:从表格到函数 当策略的表示从表格转变为函数时,存在以下几个关键区别: 最优策略的定义 : 表格表示:最优策略是使每个状态值最大化的策略 函数表示:最优策略是使某些标量指标最大化的策略 策略更新方式 :...
Reinforcement Learning
2026-04-15

引言 大语言模型(LLMs)在近年来取得了显著进展,展现出上下文学习、指令跟随和逐步推理等突出特性。然而,由于这些模型是在包含高质量和低质量数据的预训练语料库上训练的,它们可能会表现出编造事实、生成有偏见或有毒文本等意外行为。因此,将LLMs与人类价值观对齐变得至关重要,特别是在帮助性、诚实性和无害性(3H)方面。 基于人类反馈的强化学习(RLHF)已被验证为有效的对齐方法,但训练过程复杂且不稳定。本文深入分析了RLHF框架,特别是PPO算法的内部工作原理,并提出了PPO-max算法,以提高策略模型训练的稳定性和效果。 RLHF的基本框架 RLHF训练过程包括三个主要阶段: 监督微调(SFT) :模型通过模仿人类标注的对话示例来学习一般的人类对话方式, 优化模型的指令跟随能力 奖励模型(RM)训练 :模型学习基于人类反馈比较不同回复的偏好 近端策略优化(PPO) :模型基于奖励模型的反馈进行更新,通过探索和利用来发现优化的策略 奖励建模(Reward Model) 奖励模型使用预训练的基于Transformer的语言模型,...

概念 符号 定义 来源 用途 特点 Reward \(r_t\) 即时奖励 环境 基础信号 局部、即时 Return \(G_t\) \(Σ γ^k·r_{t+k}\) 计算 Value训练目标 实际、高方差 Value \(V(s)\) \(E[G_t|s_t=s]\) 模型 状态评估 预测、期望 Q-Value \(Q(s,a)\) \(E[G_t|s_t=s,a_t=a]\) 模型 动作评估 更细粒度 Advantage \(A(s,a)\) \(Q(s,a) - V(s)\) 计算 Policy更新 相对、低方差 GAE \(GAE(λ)\) 加权Advantage 算法 优势估计 平衡bias-variance 引言 Trust Region Policy Optimization (TRPO) 是2015年的ICML会议上提出的一种强大的基于策略的强化学习算法。TRPO 解决了传统策略梯度方法中的一些关键问题,特别是训练不稳定和步长选择困难的问题。与传统策略梯度算法相比,TRPO 具有更高的稳健性和样本效率,能够在复杂环境中取得更好的性能。 优化基础...