
泊松分布 日常生活中,大量事件是有固定频率的。 某医院平均每小时出生3个婴儿 某公司平均每10分钟接到1个电话 某超市平均每天销售4包xx牌奶粉 某网站平均每分钟有2次访问 它们的特点就是,我们可以预估这些事件的总数,但是没法知道具体的发生时间。已知平均每小时出生3个婴儿,请问下一个小时,会出生几个? 有可能一下子出生6个,也有可能一个都不出生。这是我们没法知道的。 泊松分布就是描述某段时间内,事件具体的发生概率。 \[P(N(t)=n)=\frac{(\lambda t)^n e^{-\lambda t}}{n!}\] 上面就是泊松分布的公式。等号的左边, \(P\) 表示概率, \(N\) 表示某种函数关系, \(t\) 表示时间, \(n\) 表示数量,1小时内出生3个婴儿的概率,就表示为 \(P(N(1) = 3)\) 。等号的右边,参数λ是单位时间(或单位面积)内随机事件的平均发生率。 接下来两个小时,一个婴儿都不出生的概率是0.25%,基本不可能发生。 \[P(N(2) = 0) = \frac{(3 \times 2)^0 e^{-3 \times 2}}{0!}...
基本概念 方向导数:是一个数;反映的是 \(f(x,y)\) 在 \(P_0\) 点沿方向 \(v\) 的变化率。 偏导数:是多个数(每元有一个);是指多元函数沿坐标轴方向的 方向导数 ,因此二元函数就有两个偏导数。 偏导函数:是一个函数;是一个关于点的偏导数的函数。 梯度:是一个向量;每个元素为函数对一元变量的偏导数;它既有大小(其大小为最大方向导数),也有方向。 方向导数 反映的是 \(f(x,y)\) 在 \(P_0\) 点沿方向 \(v\) 的变化率。 例子如下: 题目 设二元函数 \( f(x, y) = x^2 + y^2\) ,分别计算此函数在点 \((1, 2)\) 沿方向 \(w=\{3, -4\}\) 与方向 \(u=\{1, 0\}\) 的方向导数。 解: 由于 \(w\) 不是单位向量,因此首先应对其进行单位化: \[v = w^0 = \frac{w}{|w|} = \left\{ \frac{3}{5}, -\frac{4}{5} \right\}\] 计算函数增量: \[\begin{aligned}
\therefore f(x_0 + tv_1,...
问题表示 有很多概率问题,尤其是独立重复实验问题,如果用生成函数的方法来做,会显得特别方便。本文要讲的“随机游走”问题便是其中一例,它又被形象地叫做“醉汉问题”,其本质上是一个二项分布,但是由于取了极限,出现了很多新的性质和应用。我们先考虑如下问题: 考虑实数轴上的一个粒子,在 \(t=0\) 时刻它位于原点,每过一秒,它要不向前移动一格( \(+1\) ),要不就向后移动一格( \(-1\) ),问 \(n\) 秒后它所处位置的概率分布。 不难发现,这个问题跟二项分布是雷同的。如果把这个粒子形象比喻成一个“喝醉酒的人”,那么上面的走法就类似于一个完全不省人事的醉汉走路问题了。(当然,醉汉是在三维空间走路的,这里简单起见,只描述了一维的。)这是一个独立重复实验,每秒的行走可用函数描述为 \(\frac{1}{2}(z+z^{-1})\) ,于是 \(n\) 秒后的运动分布情况可以用 \[\frac{1}{2^n}(z+z^{-1})^n\] 来描述, \(z^i(i=-n,-n+1,\dots,n-1,n)\) 的系数表示粒子位于 \(i\) 的概率。 💡...
Reinforcement Learning
2026-04-15

引言 强化学习中,找到最优策略是核心目标。本文详细介绍三种能够找到最优策略的基础算法: 价值迭代、策略迭代和截断策略迭代 。这些算法属于动态规划范畴,需要系统模型,是后续无模型强化学习算法的重要基础。 在强化学习的发展路线中,这些算法处于"基础工具"到"算法/方法"的过渡阶段,是从"有模型"到"无模型"学习的重要桥梁。 价值迭代(Value iteration) 价值迭代算法 基于收缩映射定理求解贝尔曼最优方程 。其核心迭代公式为: \[\begin{equation}v_{k+1} = \max_{\pi \in \Pi} (r_\pi + \gamma P_\pi v_k), k = 0, 1, 2, ...\tag{1}\end{equation}\] 根据收缩映射定理,当 \(k \to \infty\) 时, \(v_k\) 和 \(\pi_k\) 分别收敛到最优状态值和最优策略。 每次迭代包含两个步骤: 策略更新步骤 (policy update step) :找到能解决以下优化问题的策略 \[\pi_{k+1} = \arg\max_\pi (r_\pi +...
Math
2026-04-15

引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 \(X\) ,其取值来自有限集合 \(\mathcal{X}\) 。我们的目标是估计 \(E[X]\) 。假设我们有一个独立同分布的样本序列 \(\{x_i\}_{i=1}^n\) ,那么 \(X\) 的期望值可以近似为: \[E[X] \approx \bar{x} = \frac{1}{n}\sum_{i=1}^n x_i\] 非增量方法与增量方法 非增量方法 :先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法 :定义 \[w_{k+1} = \frac{1}{k}\sum_{i=1}^k x_i, k = 1, 2, ...\] 可以推导出递归公式: \[{w}_{k + 1} =...
Reinforcement Learning
2026-04-15
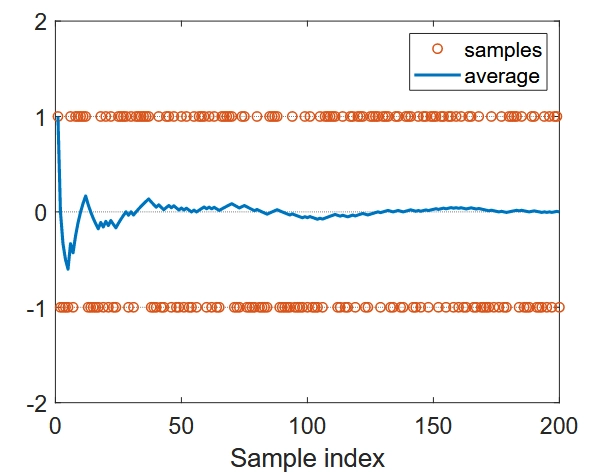
引言与背景 蒙特卡洛方法是强化学习中的重要算法类别,它标志着从基于模型到无模型算法的转变。这类算法不依赖环境模型,而是通过与环境的直接交互获取经验数据来学习最优策略。 蒙特卡洛方法在强化学习算法谱系中处于"无模型"方法的起始位置,是从基于模型的方法(如值迭代和策略迭代)向无模型方法过渡的第一步。 无模型强化学习的核心理念可以简述为: 如果没有模型,我们必须有数据;如果没有数据,我们必须有模型;如果两者都没有,我们就无法找到最优策略。在强化学习中,"数据"通常指智能体与环境交互的经验 。 均值估计问题 在介绍蒙特卡洛强化学习算法之前,我们首先需要理解均值估计问题,这是理解从数据而非模型中学习的基础。 考虑一个可以取有限实数集合 \(X\) 中值的随机变量 \(X\) ,我们的任务是计算 \(X\) 的均值或期望值: \(E[X]\) 有两种方法可以计算 \(E[X]\) : 基于模型的方法 :当已知随机变量的概率分布时,可以直接根据期望值的定义计算: \[E[X] = \sum_{x \in X} p(x) \cdot x\] 其中 \(p(x)\) 是 \(X\) 取值为 \(x\)...
Reinforcement Learning
2026-04-15

引言 DDPG同样使用了Actor-Critic的结构,Deterministic的确定性策略是和随机策略相对而言的,对于某一些动作集合来说,它可能是连续值,或者非常高维的离散值,这样动作的空间维度极大。如果我们使用随机策略,即像DQN一样研究它所有的可能动作的概率,并计算各个可能的动作的价值的话,那需要的样本量是非常大才可行的。于是有人就想出使用确定性策略来简化这个问题。 作为随机策略,在相同的策略,在同一个状态 \(s\) 处,采用的动作 \(\pi_\theta(a|s)\) 是基于一个概率分布的,即是不确定的。而确定性策略则决定简单点,虽然在同一个状态处,采用的动作概率不同,但是最大概率只有一个,如果我们只取最大概率的动作,去掉这个概率分布,那么就简单多了。即作为确定性策略,相同的策略,在同一个状态处,动作是唯一确定的,即策略变成 \[a = \mu(s, \theta)\] 所以DDPG基于确定性策略梯度(DPG)算法,结合了DQN的成功经验。 使用回放缓冲区中的样本进行离策略训练,以减少样本之间的相关性 使用目标Q网络在时序差分更新过程中提供一致的目标...
背景 RLHF 通常包括三个阶段: 有监督微调(SFT) RLHF首先通过在高质量数据上进行监督学习来微调预训练的语言模型,得到模型 \(\pi_{SFT}\) 。 奖励建模阶段 (Reward Model) 在第二阶段,SFT模型根据提示 \(x\) 生成答案对 \((y_1, y_2) \sim \pi_{SFT}(y|x)\) 。这些答案对呈现给人类标注者,他们表达对一个答案的偏好,表示为 \(y_w \succ y_l|x\) ,其中 \(y_w\) 和 \(y_l\) 分别表示在 \((y_1, y_2)\) 中更受偏好和不受偏好的答案。 这些偏好被假定由某个潜在的奖励模型 \(r^*(y, x)\) 生成,我们无法直接访问该模型。一种流行的建模偏好的方法是Bradley-Terry(BT)模型,该模型规定人类偏好分布 \(p^*\) 可以写为: \[p^*(y_1 \succ y_2|x) = \frac{\exp(r^*(x, y_1))}{\exp(r^*(x, y_1)) + \exp(r^*(x, y_2))}
\] 假设我们有一个从 \(p^*\)...
Large Model
2026-04-15

简介 后训练(post-training)已成为完整训练流程中的重要组成部分。相比于预训练,后训练需要的计算资源相对较少,但能够: 提高推理任务的准确性 使模型与社会价值观保持一致 适应用户偏好 OpenAI 的 o1 系列模型首次引入了通过增加思维链(Chain-of-Thought)推理过程长度来实现推理时间,扩展这种方法在数学、编程和科学推理等各种推理任务上取得了显著改进 研究界已探索多种方法来提高模型的推理能力:比如 基于过程的奖励模型 (Process-based Reward Models) 强化学习 (Reinforcement Learning), 代表工作:InstructGPT, 以及 搜索算法( 蒙特卡洛树搜索(Monte Carlo Tree Search)、束搜索(Beam Search))。然而,这些方法尚未达到与 OpenAI o1 系列模型相当的通用推理性能。 DeepSeek-R1-Zero 本文首先探索使用纯强化学习(RL)来提高语言模型的推理能力,重点关注: 探索 LLM 在没有任何监督数据的情况下,通过纯 RL 过程的自我进化来发展推理能力...
Reinforcement Learning
2026-04-15

基础概念 Grid-Word Example 环境描述 :网格世界是一个直观的二维环境,包含: 白色格子 :可通行区域。 橙色格子 :禁止进入的区域(禁区)。 目标格子 :代理需要到达的目标位置。 任务目标 : 找到一条“好的”策略,使代理从任意初始位置到达目标格子。 策略应避免进入禁区、碰撞边界或走不必要的弯路。 什么是强化学习:依据策略执行动作-感知状态-得到奖励 所谓强化学习(Reinforcement Learning,简称RL),是指基于智能体在复杂、不确定的环境中最大化它能获得的奖励,从而达到自主决策的目的。 a computational approach to learning whereby an agent tries to maximize the total amount of reward it receives while interacting with a complex and uncertain environment 经典的强化学习模型可以总结为下图的形式(你可以理解为任何强化学习都包含这几个基本部分:智能体、行为、环境、状态、奖励):...
Large Model
2026-04-15

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...