
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
NLP
2026-03-26
概述 HiPPO(High-order Polynomial Projection Operators)是目前大热的structured state space model (S4)及其后续工作的backbone. State space mode主要是控制学科里的内容,最近被引入深度学习领域来解决长距离依赖问题。长距离依赖建模的核心问题是如何通过有限的memory来尽可能记住之前所有的历史信息。当前的主流序列建模模型(即Transformer和RNN) 存在着普遍的遗忘问题 fixed-size context windows: Transformer的window size通常是有限的,一般来说quadratic的attention最多建模到大约10k的token就到计算极限了 vanishing gradient: RNN通过hidden state来存储历史信息,理论上能记住之前所有内容,但实际上的effective memory大概是<1k个token的level,可能的原因是gradient vanishing HiPPO 通过数学方法分析来得到closed-form...

泊松分布 日常生活中,大量事件是有固定频率的。 某医院平均每小时出生3个婴儿 某公司平均每10分钟接到1个电话 某超市平均每天销售4包xx牌奶粉 某网站平均每分钟有2次访问 它们的特点就是,我们可以预估这些事件的总数,但是没法知道具体的发生时间。已知平均每小时出生3个婴儿,请问下一个小时,会出生几个? 有可能一下子出生6个,也有可能一个都不出生。这是我们没法知道的。 泊松分布就是描述某段时间内,事件具体的发生概率。 \[P(N(t)=n)=\frac{(\lambda t)^n e^{-\lambda t}}{n!}\] 上面就是泊松分布的公式。等号的左边, \(P\) 表示概率, \(N\) 表示某种函数关系, \(t\) 表示时间, \(n\) 表示数量,1小时内出生3个婴儿的概率,就表示为 \(P(N(1) = 3)\) 。等号的右边,参数λ是单位时间(或单位面积)内随机事件的平均发生率。 接下来两个小时,一个婴儿都不出生的概率是0.25%,基本不可能发生。 \[P(N(2) = 0) = \frac{(3 \times 2)^0 e^{-3 \times 2}}{0!}...
基本概念 方向导数:是一个数;反映的是 \(f(x,y)\) 在 \(P_0\) 点沿方向 \(v\) 的变化率。 偏导数:是多个数(每元有一个);是指多元函数沿坐标轴方向的 方向导数 ,因此二元函数就有两个偏导数。 偏导函数:是一个函数;是一个关于点的偏导数的函数。 梯度:是一个向量;每个元素为函数对一元变量的偏导数;它既有大小(其大小为最大方向导数),也有方向。 方向导数 反映的是 \(f(x,y)\) 在 \(P_0\) 点沿方向 \(v\) 的变化率。 例子如下: 题目 设二元函数 \( f(x, y) = x^2 + y^2\) ,分别计算此函数在点 \((1, 2)\) 沿方向 \(w=\{3, -4\}\) 与方向 \(u=\{1, 0\}\) 的方向导数。 解: 由于 \(w\) 不是单位向量,因此首先应对其进行单位化: \[v = w^0 = \frac{w}{|w|} = \left\{ \frac{3}{5}, -\frac{4}{5} \right\}\] 计算函数增量: \[\begin{aligned}
\therefore f(x_0 + tv_1,...
问题表示 有很多概率问题,尤其是独立重复实验问题,如果用生成函数的方法来做,会显得特别方便。本文要讲的“随机游走”问题便是其中一例,它又被形象地叫做“醉汉问题”,其本质上是一个二项分布,但是由于取了极限,出现了很多新的性质和应用。我们先考虑如下问题: 考虑实数轴上的一个粒子,在 \(t=0\) 时刻它位于原点,每过一秒,它要不向前移动一格( \(+1\) ),要不就向后移动一格( \(-1\) ),问 \(n\) 秒后它所处位置的概率分布。 不难发现,这个问题跟二项分布是雷同的。如果把这个粒子形象比喻成一个“喝醉酒的人”,那么上面的走法就类似于一个完全不省人事的醉汉走路问题了。(当然,醉汉是在三维空间走路的,这里简单起见,只描述了一维的。)这是一个独立重复实验,每秒的行走可用函数描述为 \(\frac{1}{2}(z+z^{-1})\) ,于是 \(n\) 秒后的运动分布情况可以用 \[\frac{1}{2^n}(z+z^{-1})^n\] 来描述, \(z^i(i=-n,-n+1,\dots,n-1,n)\) 的系数表示粒子位于 \(i\) 的概率。 💡...
Large Model
2026-03-18
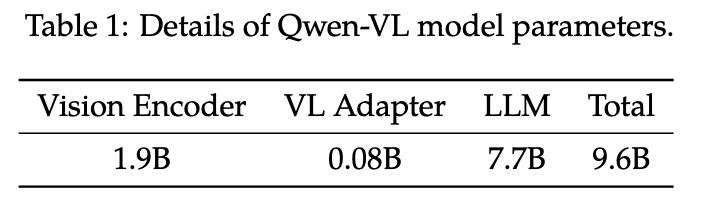
Qwen-VL 模型框架 Qwen-VL的整体网络架构由三个组件组成: LLM:使用 Qwen-7B 的预训练权重进行初始化。 视觉编码器:Qwen-VL 的可视化编码器使用ViT 架构,使用 Openclip 的 ViT-bigG 的预训练权重进行初始化。在训练和推理过程中,输入图像的大小都会调整为特定分辨率。视觉编码器通过以 14 步幅将图像分割成块来处理图像,生成一组图像特征。 位置感知视觉语言适配器:为了缓解长图像特征序列带来的效率问题,Qwen-VL 引入了一种视觉语言适配器来压缩图像特征。类似QFormer,该适配器包括一个随机初始化的单层交叉注意力模块。使用一组可训练向量(嵌入)作为query,并将视觉编码器中的图像特征作为交叉注意力作的key。该机制将视觉特征序列压缩到固定长度 256。 图像输入 图像不会直接以像素形式喂给语言模型(LLM)。 典型流程是: Visual Encoder :把图片编码成一串视觉特征(embedding/feature sequence)。 Adapter :把视觉特征映射到语言模型可接入的表征空间/维度。 最终得到:...
Large Model
2026-03-18
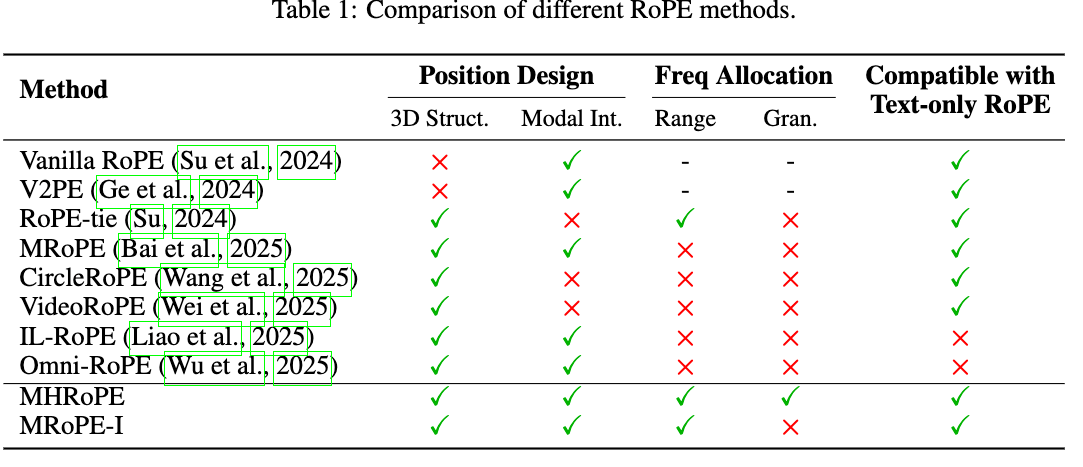
简介 论文: 《REVISITING MULTIMODAL POSITIONAL ENCODING IN VISION–LANGUAGE MODELS》 通过对多模态旋转位置嵌入(RoPE)的两个核心组件——位置设计和频率分配进行综合分析。通过实验,确定了三个关键指南:位置一致性、频率全利用和保留文本先验。基于这些见解,提出了多头RoPE(MHRoPE)和MRoPE-Interleave(MRoPE-I),这两种简单且即插即用的变体不需要任何架构更改。 为了构建更稳健的多模态位置编码,作者在MRoPE的基础上,系统地探索了三个未充分研究的方案: 位置设计——如何为文本和视觉标记分配无歧义、分离良好的坐标; 频率分配——如何将旋转频率分配到每个位置轴的嵌入维度; 与纯文本RoPE的兼容性——确保设计默认为标准RoPE,以便进行有效的迁移学习。 Vanilla RoPE RoPE与加性位置嵌入不同,RoPE对query和key向量应用旋转变换,从而将相对位置依赖直接纳入自注意力机制。给定位置 \(m\) 的查询向量 \(q\) 和位置 \(n\) 的键向量 \(k\) ,注意力分数...
Large Model
2026-03-12

比起两年前,NLG任务已经得到了非常有效的发展,transformers模块的使用广泛程度也达到前所未有的程度。在模型推理预测时,一个核心的语句就是 model.generate() ,本文就来详细介绍一下generate方法是如何运作的。在生成的过程中,包含了诸多生成策略,本文将以最常用的beam search为例,尽可能详细地展开介绍。 随着各种LLM的出现,transformers中与generate相关的代码发生了一些变化,主要区别在于: generate的源码位置发生了改变; generate方法中,采用一个 generation_config 参数来管理生成相关的各种配置,并优化了逻辑,使得逻辑更加清晰。 generate的代码位置 在之前版本的transformers中(transformers~=4.9),generate方法位于 transformers.generation_utils.py ,这个方法是 GenerationMixin 类的一个方法。 而在新版本的transformers中(transformers~=4.42),generate方法被转移到了...
Large Model
2026-03-12

概述 https://github.com/FasterDecoding/Medusa Medusa 是自投机领域较早的一篇工作,对后续工作启发很大,其主要思想是 multi-decoding head + tree attention + typical acceptance(threshold)。Medusa 没有使用独立的草稿模型,而是在原始模型的基础上增加多个解码头(MEDUSA heads),并行预测多个后续 token。 正常的LLM只有一个用于预测 \(t\) 时刻token的head。Medusa 在 LLM 的最后一个 Transformer层之后保留原始的 LM Head,然后额外增加多个(假设是 \(k\) 个) 可训练的Medusa Head(解码头),分别负责预测 \(t+1,t+2,...,\) 和 \(t+k\) 时刻的不同位置的多个 Token。 Medusa 让每个头生成多个候选 token,而非像投机解码那样只生成一个候选。然后将所有的候选结果组装成多个候选序列,多个候选序列又构成一棵树。再通过树注意力机制并行验证这些候选序列 。 原理...
Large Model
2026-03-10

概述 投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 > 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。 下图左侧是自回归解码模型,右侧是投机解码机制。 从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地猜测出模型接下来要输出的token。作为对比,也有一种方案是通过路由的方式组合多个不同规模和性能的模型。路由方式在调用之前已经确定好需要调用哪个模型,直到调用结束。而投机解码在一个 Query 内会反复调用大小模型。 背景 我们都知道,生成式 LLM 大部分是 Decoder-only...
Large Model
2026-03-10

引言 Structured Generation with LLM,是指 让LLM按照预先定义的schema,输出符合schema的结构化结果 。 常见的应用场景有: 数据处理 。主要功能为a -> b,即从源文本中 抽取/生成 符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等; Agent 。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参。 将 LLM 限制为始终生成符合特定模式的、有效的 JSON 或 YAML,是许多应用的关键功能。 Kor Kor ,一个 基于prompt的技术方案 ;Kor比较适合 数据处理 场景,且原理简单、易于理解,适合作为入门, 并且Kor适用于那些不支持function calling的比较旧的模型。 使用Kor进行structured generation的流程如下: 定义schema,包括结构、注释还有例子; Kor用特定的 prompt template ,将用户提供的schema和待处理的raw text,组装成prompt; 将prompt发送给LLM,借助其通用的In...
Large Model
2026-03-10

问题背景 首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗? 其实没那么简单。先看文本生成,事实上文本生成自始至终都只有一条主流路线,那就是语言模型,即建模条件概率 \(p(x_t|x_1,\cdots,x_{t-1})\) ,不论是最初的 n-gram语言模型,还是后来的Seq2Seq、GPT,都是这个条件概率的近似。也就是说,一直以来,人们对“实现文本生成需要往哪个方向走”是很明确的,只是背后所用的模型有所不同,比如LSTM、CNN、Attention乃至最近复兴的线性RNN等。所以, 文本生成确实可以All in Transformer来大力出奇迹,因为方向是标准的、清晰的。 然而,对于图像生成,并没有这样的“标准方向”。就本站所讨论过的图像生成模型,就有 VAE 、 GAN 、 Flow 、 Diffusion ,还有小众的 EBM...