Large Model
2026-04-15
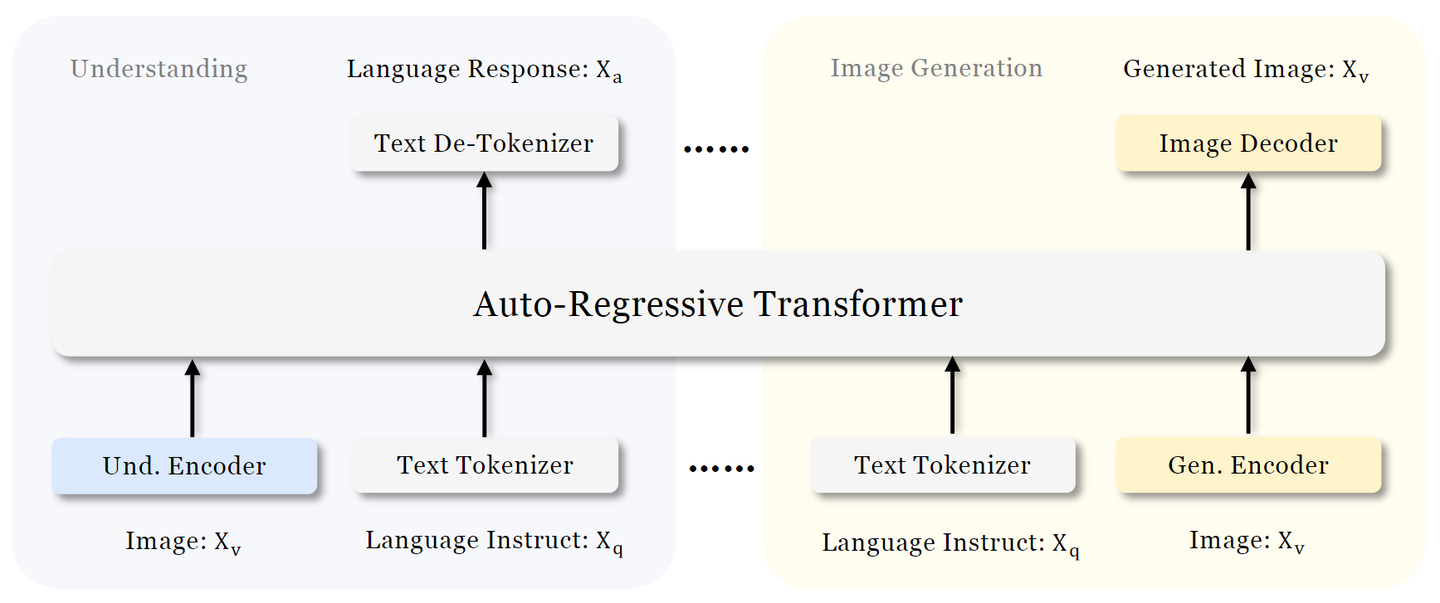
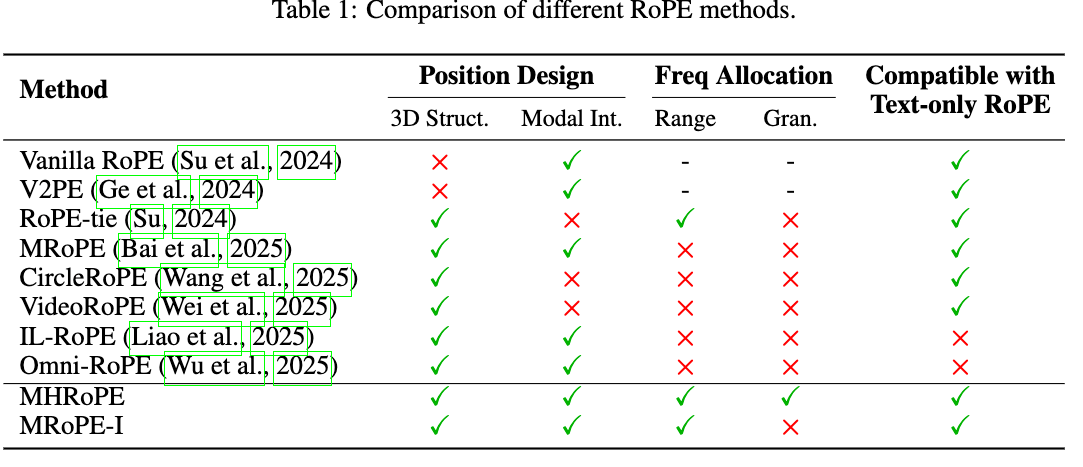
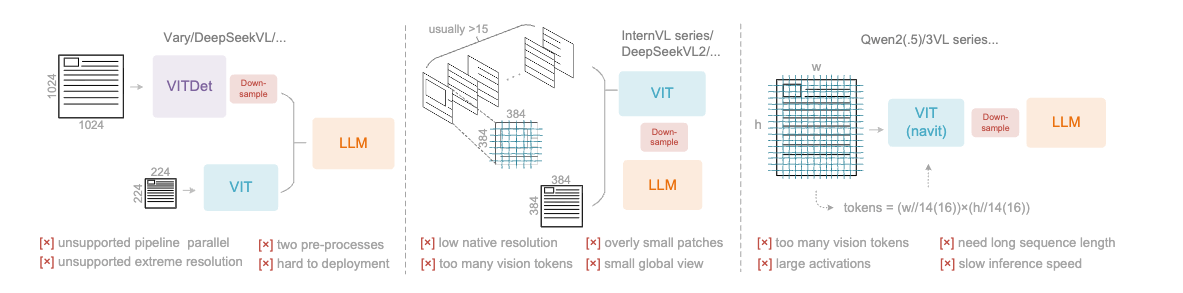
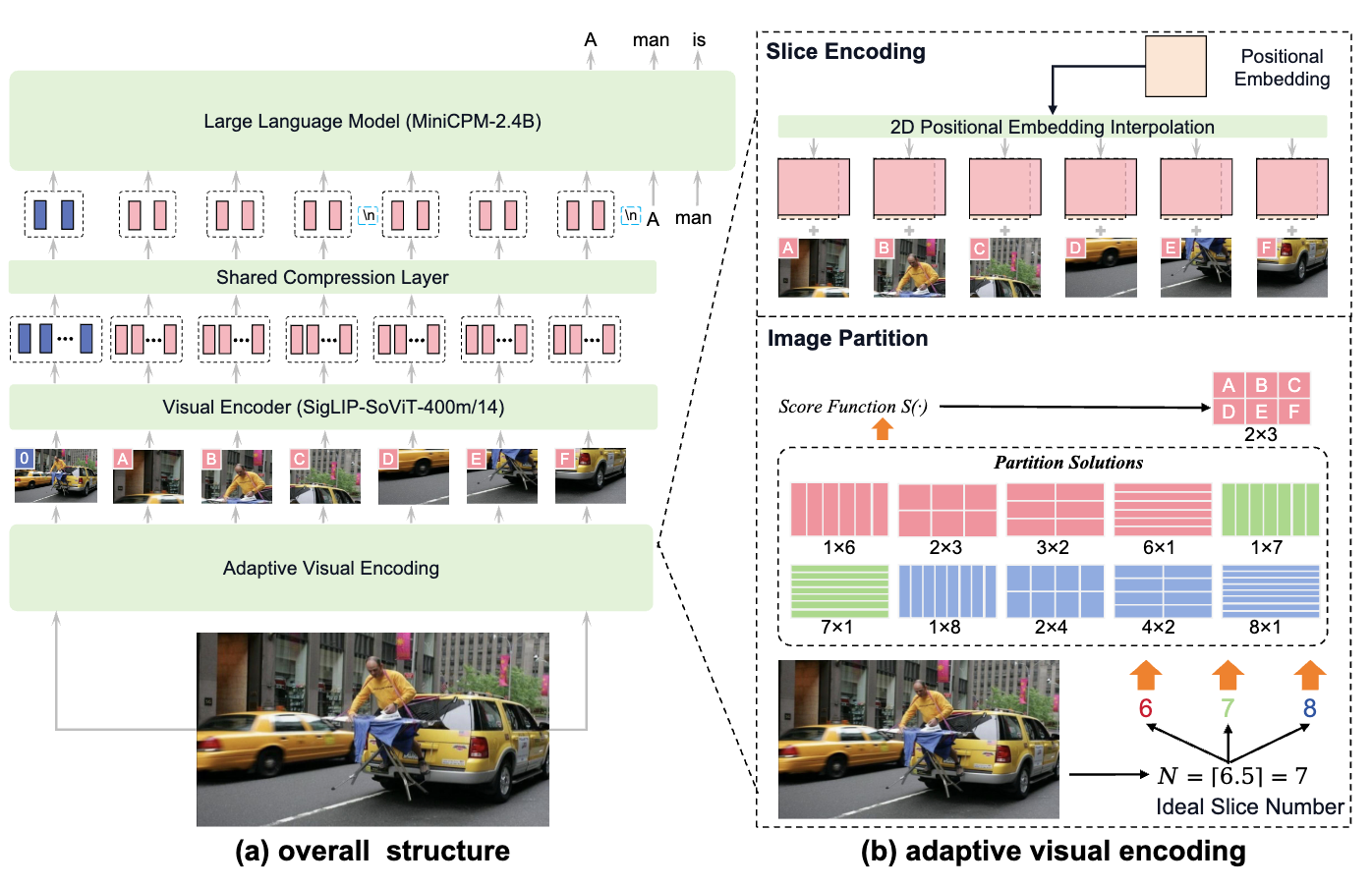
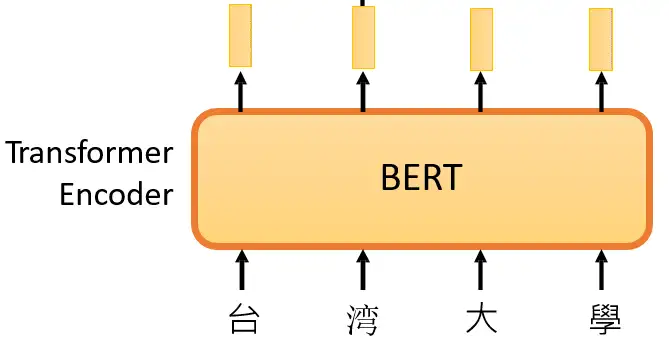
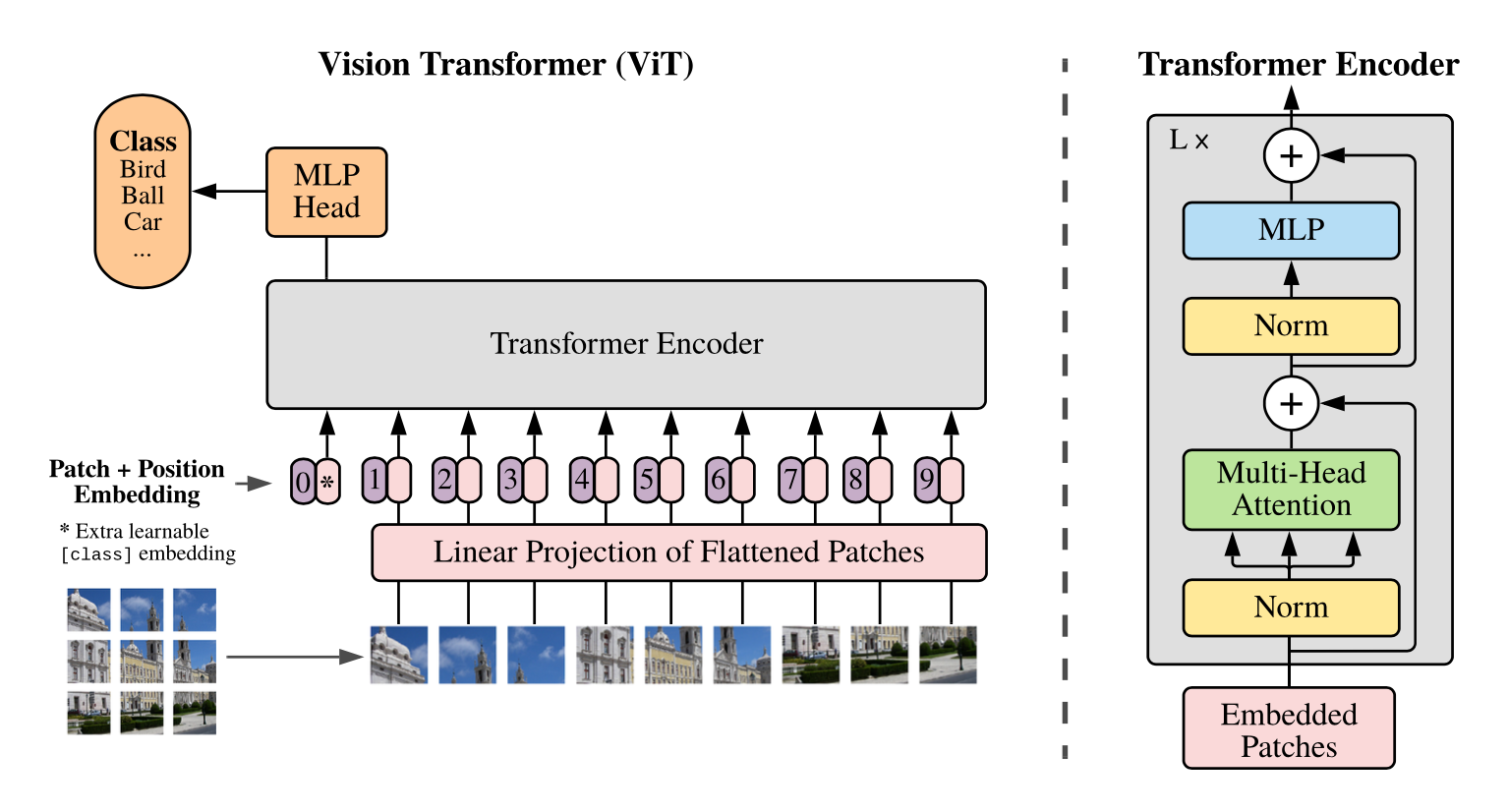
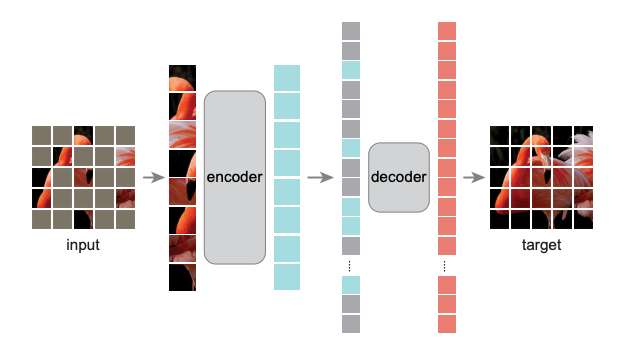
Janus 论文名称: Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation 论文地址: arxiv.org/pdf/2410.13848 项目主页 : github.com/deepseek-ai/Janus 模型 Janus 是使用一个统一的 Transformer 架构来统一多模态图像理解和多模态图像生成任务的模型。这种方法通常使用单个视觉编码器来处理这 2 个任务的输入。然而, 多模态理解和生成任务所需的表征差异很大 : 多模态理解 任务中,视觉编码器的目的是提取高级语义信息。理解任务的输出不仅涉及从图像中提取信息,还涉及复杂的语义推理。因此,视觉编码器表示的粒度往往主要集中在高维语义的表征上。相比之下, 视觉生成任务 中,主要关注点是生成局部细节并保持图像中的全局一致性。在这种情况下,表征需要表示出细粒度的空间结构,以及纹理细节。 在同一空间中统一这两个任务的表示将导致冲突...