
11. 盛最多水的容器 题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明: 你不能倾斜容器。 示例 1: 输入:[1,8,6,2,5,4,8,3,7]
输出:49
解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。 示例 2: 输入:height = [1,1]
输出:1 提示: n == height.length 2 <= n <= 10 5 0 <= height[i] <= 10 4 题解 在初始时,左右指针分别指向数组的左右两端,它们可以容纳的水量为 \(min(1,7)∗8=8\) 。 此时我们需要移动一个指针。移动哪一个呢?直觉告诉我们,应该移动对应数字较小的那个指针(即此时的左指针)。这是因为,由于容纳的水量是由 两个指针指向的数字中较小值∗指针之间的距离...
Deep Learning
2026-04-15
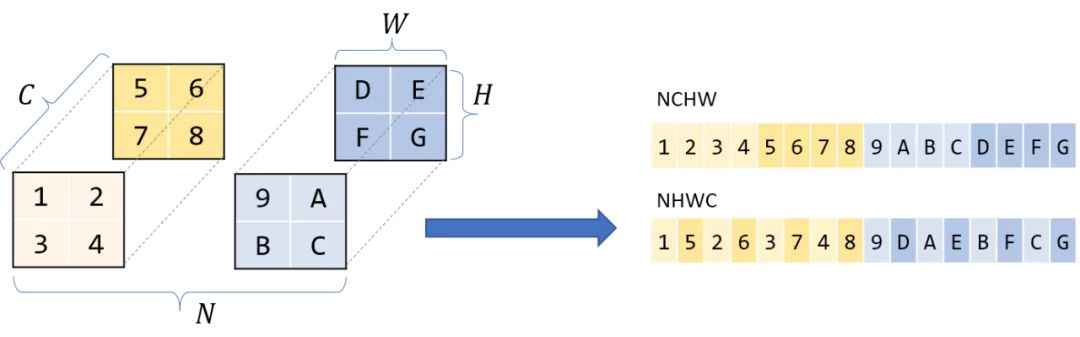
现代深度学习库对大多数操作都具有生产级的、高度优化的实现,这并不奇怪。但这些库究竟是什么魔法?他们如何能够将性能提高100倍?究竟怎样才能“优化”或加速神经网络的运行呢?在讨论高性能/高效DNNs时,我经常会问(也经常被问到)这些问题。 在这篇文章中,我将尝试带你了解在DNN库中卷积层是如何实现的。它不仅是在模型中最常见的和最重的操作,我还发现卷积高性能实现的技巧特别具有代表性——一点点算法的小聪明,非常多的仔细的调优和低层架构的开发。 我在这里介绍的很多内容都来自Goto等人的开创性论文:Anatomy of a high-performance matrix multiplication,该论文为OpenBLAS等线性代数库中使用的算法奠定了基础。 最原始的卷积实现 “过早的优化是万恶之源”——Donald Knuth 在进行优化之前,我们先了解一下基线和瓶颈。这是一个朴素的numpy/for循环卷积: '''
Convolve `input` with `kernel` to generate `output`
input.shape =...
Deep Learning
2026-04-15

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 Upsampling(上采样)[没有学习过程] 在FCN、U-net等网络结构中,涉及到了上采样。上采样概念: 上采样指的是任何可以让图像变成更高分辨率的技术 。最简单的方式是 重采样和插值 :将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在 torch.nn 中的 Vision Layers 里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d PixelShuffle 当stride = (1/r) < 1时,可以让卷积后的feature map变大——即分辨率变大,这个新的操作叫做sub-pixel convolution,具体原理可以看 “PixelShuffle:Real-Time Single Image and Video...
Generative Model
2026-04-15

背景 本文主要是 《NICE: Non-linear Independent Components Estimation》 一文的介绍和实现。这篇文章也是glow这个模型的基础文章之一,可以说它就是glow的奠基石。 艰难的分布 众所周知,目前主流的生成模型包括VAE和GAN,但事实上除了这两个之外,还有基于flow的模型(flow可以直接翻译为“流”,它的概念我们后面再介绍)。事实上flow的历史和VAE、GAN它们一样悠久,但是flow却鲜为人知。在我看来,大概原因是flow找不到像GAN一样的诸如“造假者-鉴别者”的直观解释吧,因为flow整体偏数学化,加上早期效果没有特别好但计算量又特别大,所以很难让人提起兴趣来。不过现在看来,OpenAI的这个好得让人惊叹的、基于flow的glow模型,估计会让更多的人投入到flow模型的改进中。 glow模型生成的高清人脸 生成模型的本质,就是希望用一个我们知道的概率模型来拟合所给的数据样本, 也就是说,我们得写出一个带参数 \(𝜃\) 的分布 \(q_{\boldsymbol{\theta}}(\boldsymbol{x})\)...
Generative Model
2026-04-15
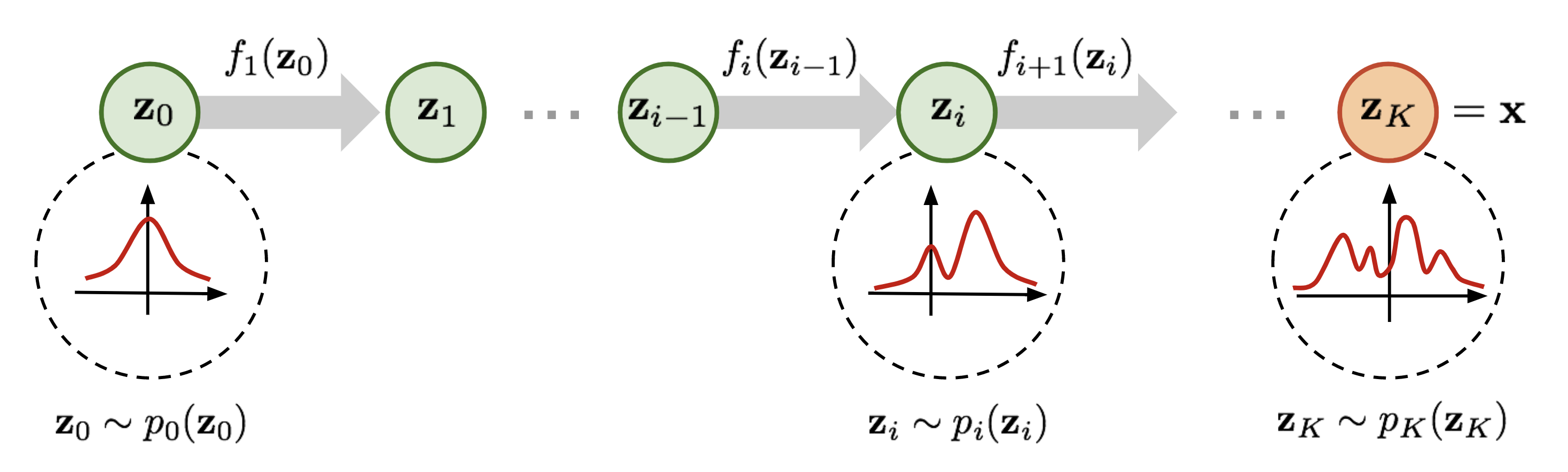
Normalizing flow(标准化流)是一类对概率分布进行建模的工具,它能完成简单的概率分布(例如高斯分布)和任意复杂分布之间的相互转换,经常被用于 data generation、density estimation、inpainting 等任务中,例如 Stability AI 提出的 Stable Diffusion 3 中用到的 rectified flow 就是 normalizing flow 的变体之一。 为了便于理解,在正式开始介绍之前先简要说明一下 normalizing flow 的做法。如上图所示, 为了将一个高斯分布 \(z_0\) 转换为一个复杂的分布 \(z_K\) ,normalizing flow 会对初始的分布 \(z_0\) 进行多次可逆的变换,将其逐渐转换为 \(z_K\) 。由于每一次变换都是可逆的,从 \(z_K\) 出发也能得到高斯分布 \(z_0\) 。这样,我们就实现了复杂分布与高斯分布之间的互相转换,从而能从简单的高斯分布建立任意复杂分布。 对 diffusion models 比较熟悉的读者可能已经发现了,这个过程和...
Generative Model
2026-04-15

1-Rectified Flow 可以认为是 flow matching的ot最优传输形式 Rectified Flow目的是将多对多无约束映射 转变成 一对一有约束映射。 ode会保证路径是“因果”的,也就是避免相交的情况 2-Rectified Flow或者叫Reflow 核心的实际上是加噪过程的样本交点数目降低,交点处模型无法精确学习向量场,交点数少了,模型在每个点预测都更准了,加噪过程是直线,所以能更少步数走到起点(但整体采样过程不是直线) 原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE 。 细想上述过程, 可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了 。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。 Rectified Flow 理论推导 微分方程...
Generative Model
2026-04-15

Flow Matching 其实是将 flow 的离散形式转换为连续形式(连续标准化流CNF),进而可以看成是一个ODE方程,实际求解的是这个ODE 求解的核心思路是:构建速度场通过数值积分求解位移,也就是通过预测速度场,从而转为ode求解 从概率路径的角度上来说,解是无穷多的,不同的方法本质上讲是在于构造尽可能简单、直接、易解的概率路径 通过不同的条件概率路径,可以构造出VP(score matching)、 VE(diffusion)、OT(1-rectified flow)等形式 实际的边缘概率分布路径并不是一条直线 ,我们是通过拟合条件速度场来逼近边缘速度场, 即使我们证明了对于参数 \(\theta\) 来说优化目标是等价的,但终究还是有一些gap Flow-based Models Normalizing Flow Normalizing Flow 是一种基于 变换 对概率分布进行建模的模型,其通过一系列 离散且可逆的变换 实现任意分布与先验分布(例如标准高斯分布)之间的相互转换。在 Normalizing Flow...
Generative Model
2026-04-15

SD模型原理 SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION-5B也是开源的。SD在开源90天github仓库就收获了 33K的stars ,可见这个模型是多受欢迎。 SD是一个 基于latent的扩散模型 ,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于 Latent Diffusion 这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。 基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势...
NLP
2026-04-15

Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times d}\) ,一般场景下都有 \(n > d\) 甚至...
Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\end{equation}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times...
NLP
2026-04-15

Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\end{equation}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times...
NLP
2026-04-15

概述 本文模型脉络图 本文介绍一个比较有意思的高效Transformer工作——来自Google的 《Transformer Quality in Linear Time》 , 什么样的结果值得我们用“惊喜”来形容?有没有言过其实?我们不妨先来看看论文做到了什么: 提出了一种新的Transformer变体,它依然具有二次的复杂度,但是相比标准的Transformer,它有着更快的速度、更低的显存占用以及更好的效果; 提出一种新的线性化Transformer方案,它不但提升了原有线性Attention的效果,还保持了做Decoder的可能性,并且做Decoder时还能保持高效的训练并行性。 说实话,笔者觉得做到以上任意一点都是非常难得的,而这篇论文一下子做到了两点,所以我愿意用“惊喜满满”来形容它。更重要的是,论文的改进总的来说还是比较自然和优雅的,不像很多类似工作一样显得很生硬。此外,笔者自己也做了简单的复现实验,结果显示论文的可复现性应该是蛮好的,所以真的有种“Transformer危矣”的感觉了。 门控注意(Gated Attention Unit)...