164. 最大间距 题目 给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。 如果数组元素个数小于 2,则返回 0。 Example 1: Input: [3,6,9,1]
Output: 3
Explanation: The sorted form of the array is [1,3,6,9], either
(3,6) or (6,9) has the maximum difference 3. 题解 如果进行排序,这里会超时。采用桶排序 基础排序算法 的思想,可以在线性时间解决。 首先建立桶,每个桶中只需要存放这个桶中元素的最大值和最小值。 我们期望将数组中的各个数等距离分配,也就是每个桶的长度相同,也就是对于所有桶来说,桶内最大值减去桶内最小值都是一样的。可以当成公式来记。 \[每个桶的长度=\max(1,\lfloor{{\max(nums)-\min(nums)}\over{len(nums)-1}}\rfloor)\tag{1}\]...
Algorithm
2026-04-15
实现 方式一:使用 heapq 标准库 这是 Python 最快、最节省内存的方式,因为 heapq 底层是用 C 语言实现的。 小顶堆 (Min Heap) Python 的 heapq 默认就是小顶堆。 import heapq
# 初始化
min_heap = []
# 添加元素 O(log N)
heapq.heappush(min_heap, 5)
heapq.heappush(min_heap, 2)
heapq.heappush(min_heap, 8)
# 查看堆顶 O(1)
print(min_heap[0]) # 输出: 2
# 弹出堆顶 O(log N)
pop_val = heapq.heappop(min_heap)
print(pop_val) # 输出: 2
print(min_heap) # 输出: [5, 8] (注意:堆内部不一定有序,但堆顶一定是最小的)
# 将已有的列表转化为堆 O(N)
nums = [5, 7, 1, 3]
heapq.heapify(nums)
print(nums) #...
Self-Supervised
2026-04-15
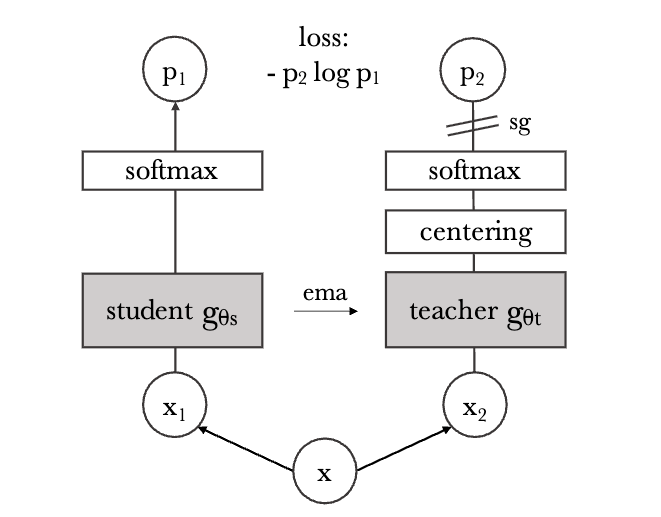
DINO Emerging Properties in Self-Supervised Vision Transformers 论文地址: arxiv.org/pdf/2104.14294 DINO摇摆到了动量式更新,果然【加动量】还是比【只用梯度停止】香。DINO的名字来自于Self- di stillation with no labels中的蒸馏和No标签。 DINO的训练步骤 其实以前的对比学习方案也可以理解为知识蒸馏,DINO里更具体得描述了知识蒸馏的含义。 下图展示了一个样本通过数据增强得到一对views \((x_1,x_2)\) 。注意DINO后面还会使用更复杂的裁剪和对比方案,但这里简单起见先不考虑那些。模型将输入图像的两种不同的随机变换 \(x_1\) 和 \(x_2\) 分别传递给学生和教师网络。 这两个网络具有相同的架构,但参数不同 。教师网络的输出以batch内计算的平均值,进行中心化(减去均值)。每个网络输出一个 \(K\)...
Self-Supervised
2026-04-15

从 NLP 入手 n-gram 语言模型(language model)就是假设一门语言所有可能的句子服从一个概率分布,每个句子出现的概率加起来是1,那么语言模型的任务就是预测每个句子在语言中出现的概率。如果把句子 \(s\) 看成单词 \(w\) 的序列 \(s=\{w_1,w_2,...,w_m\}\) ,那么语言模型就是建模一个 \(p(w_1,w_2,...,w_m)\) 来计算这个句子 \(s\) 出现的概率,直观上我们要得到这个语言模型,基于链式法则可以表示为每个单词出现的条件概率的乘积,我们将条件概率的条件 \((w_1,w_2,...,w_{i-1})\) 称为单词 \(w_i\) 的上下文,用 \(c_i\) 表示。 \[\begin{aligned} p\left(w_{1}, w_{2}, \ldots, w_{m}\right)&=p\left(w_{1}\right) * p\left(w_{2} \mid w_{1}\right) * p\left(w_{3} \mid w_{1}, w_{2}\right) \ldots p\left(w_{m}...
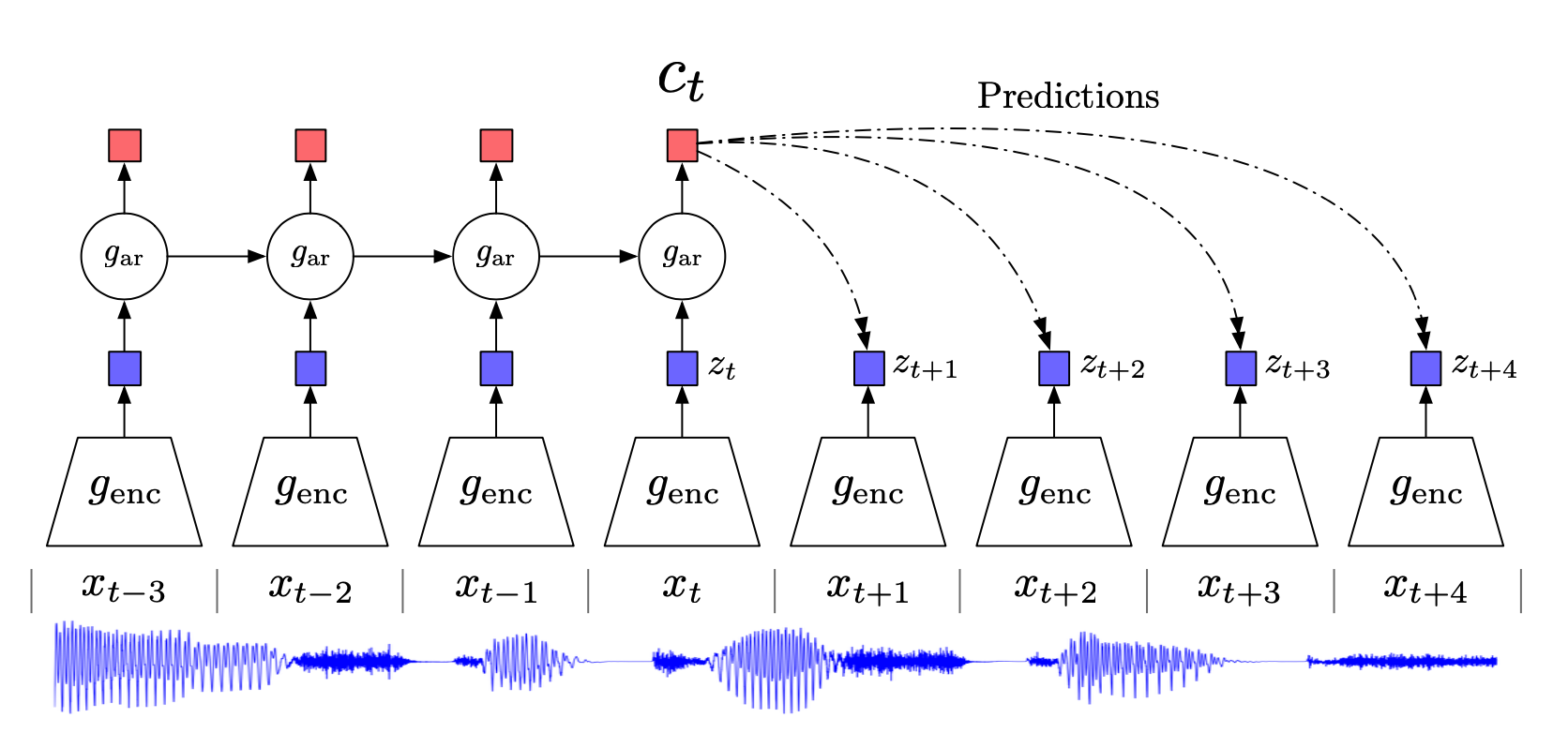
补充知识 表示学习 (Representation Learning): 学习数据的表征,以便在构建分类器或其他预测器时更容易提取有用的信息 ,无监督学习也属于表示学习。 互信息 (Mutual Information):表示两个变量 \(X\) 和 \(Y\) 之间的关系,定义为: \[I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x|y)}{p(x)}\] 对比损失(contrastive loss) :计算成对样本的匹配程度,主要用于降维中。计算公式为: \[L=\frac{1}{2N}\sum_{n-1}^N[yd^2+(1-y)max(margin-d, 0)^2]\] 其中, \(d=\sqrt{(a_n-b_n)^2}\) 为两个样本的欧式距离, \(y=\{0,1\}\) 代表两个样本的匹配程度, \(margin\) 代表设定的阈值。这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。当 \( y=1\) (即样本相似)时,损失函数只剩下 \(∑d^2\)...
Self-Supervised
2026-04-15
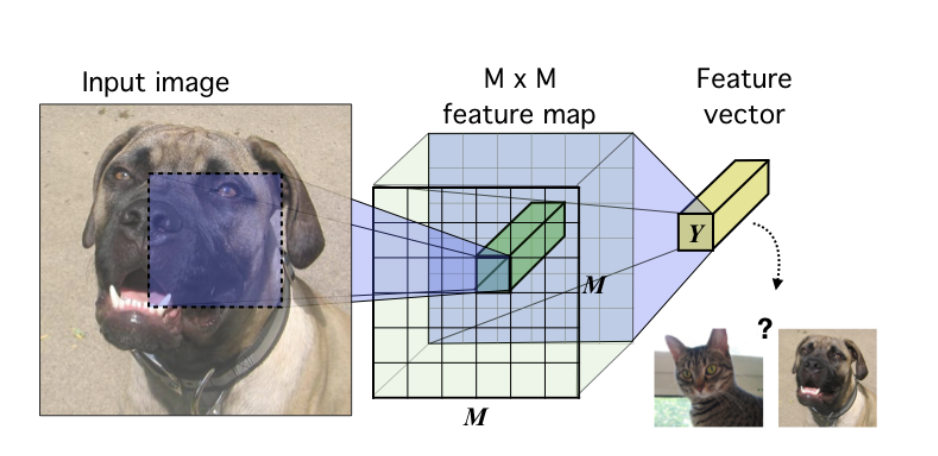
相关内容 自监督学习 (Self-supervised):属于无监督学习,其核心是自动为数据打标签(伪标签或其他角度的可信标签,包括图像的旋转、分块等等),通过让网络按照既定的规则,对数据打出正确的标签来更好地进行特征表示,从而应用于各种下游任务。 互信息 (Mutual Information):表示两个变量 \(X\) 和 \(Y\) 之间的关系,定义为: \[I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x|y)}{p(x)}\] 噪声对抗估计 (Noise Contrastive Estimation, NCE):在NLP任务中一种降低计算复杂度的方法,将语言模型估计问题简化为一个二分类问题。 Introduction 无监督学习一个重要的问题就是学习有用的 representation,本文的目的就是训练一个 representation learning 函数(即编码器encoder) ,其通过最大编码器输入和输出之间的互信息(MI)来学习对下游任务有用的 representation,而互信息可以通过 MINE...
Self-Supervised
2026-04-15
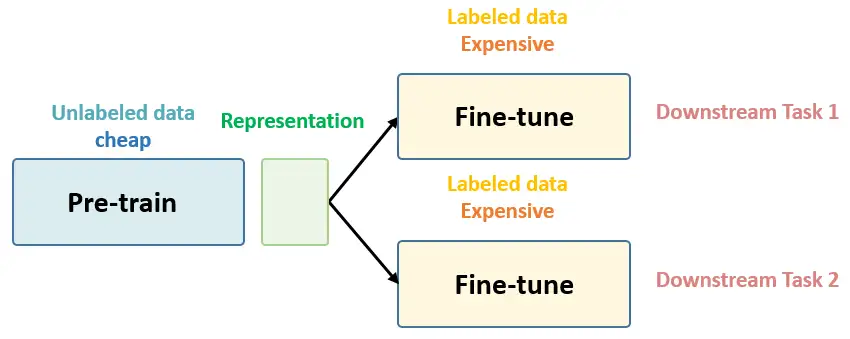
总结下 Self-Supervised Learning 的方法,用 4 个英文单词概括一下就是: Unsupervised Pre-train, Supervised Fine-tune. 在预训练阶段我们使用 无标签的数据集 (unlabeled data) ,因为有标签的数据集 很贵 ,打标签得要多少人工劳力去标注,那成本是相当高的,所以这玩意太贵。相反,无标签的数据集网上随便到处爬,它 便宜 。在训练模型参数的时候,我们不追求把这个参数用带标签数据从 初始化的一张白纸 给一步训练到位,原因就是数据集太贵。于是 Self-Supervised Learning 就想先把参数从 一张白纸 训练到 初步成型 ,再从 初步成型 训练到 完全成型 。注意这是2个阶段。这个 训练到初步成型的东西 ,我们把它叫做 Visual Representation 。预训练模型的时候,就是模型参数从 一张白纸 到 初步成型 的这个过程,还是用无标签数据集。等我把模型参数训练个八九不离十,这时候再根据你 下游任务 (Downstream Tasks) 的不同去用带标签的数据集把参数训练到 完全成型...
Self-Supervised
2026-04-15
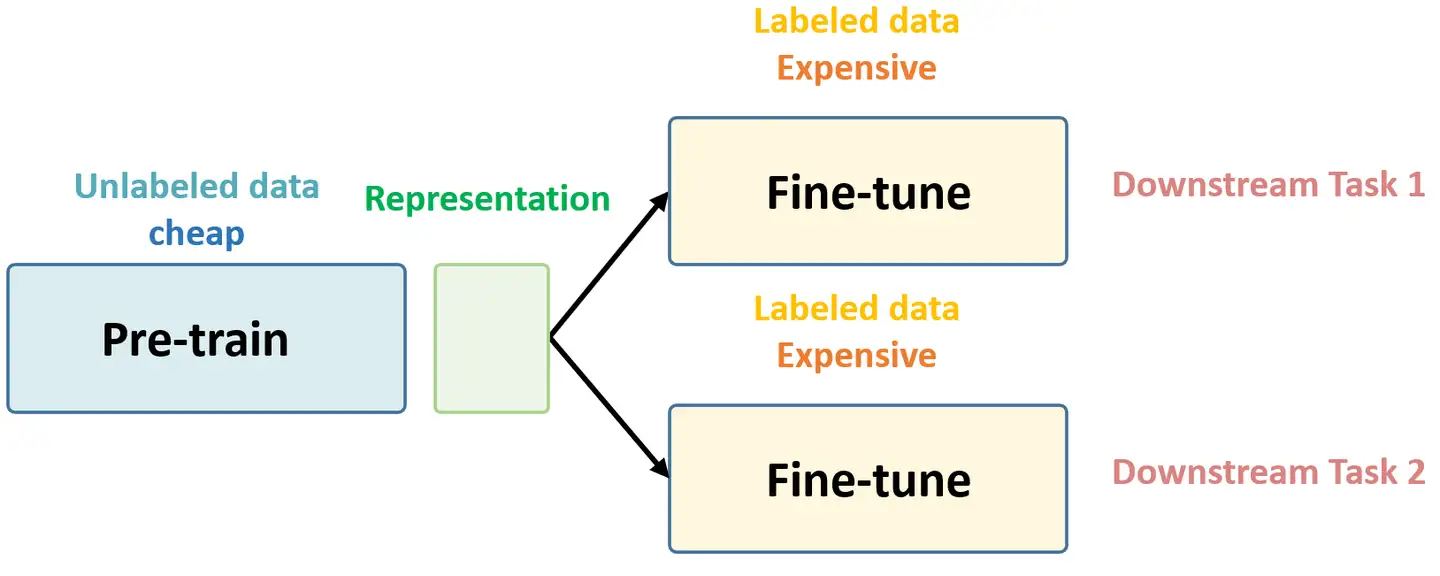
Self-Supervised Learning ,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种 通用的特征表达 用于 下游任务 (Downstream Tasks) 。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。 总结下 Self-Supervised Learning 的方法,用 4 个英文单词概括一下就是: Unsupervised Pre-train, Supervised Fine-tune. 这段话先放在这里,可能你现在还不一定完全理解,后面还会再次提到它。 在预训练阶段我们使用 无标签的数据集 (unlabeled data) ,因为有标签的数据集 很贵...
Self-Supervised
2026-04-15

如果把 近几年对比学习在视觉领域有代表性的工作做一下总结,那么对比学习的发展历程大概可以分为四个阶段: 百花齐放 这个阶段代表性工作有InstDisc(instance discrimination,)、CPC、CMC等。在这个阶段中,方法、模型、目标函数、代理任务都还没有统一,所以说是一个百花齐放的时代 CV双雄 代表作有MoCo v1、SimCLR v1、MoCo v2、SimCLR v2;CPC、CMC的延伸工作、SwAV等。这个阶段发展非常迅速,有的工作间隔甚至不到一个月,ImageNet上的成绩基本上每个月都在被刷新。 不用负样本 BYOL及其改进工作、SimSiam(CNN在对比学习中的总结性工作) transformer MoCo v3、DINO。这个阶段,无论是对比学习还是最新的掩码学习,都是用Vision Transformer做的。 第一阶段:百花齐放(2018-2019Mid) InstDisc(instance discrimination) 这篇文章提出了个体判别任务(代理任务)以及 memory bank ,非常经典,后人给它的方法起名为InstDisc。...

简介 生成树(spanning tree) 在图论中,无向图 \(G=(V,E)\) 的生成树(spanning tree)是具有 \(G\) 的全部顶点,但边数最少的联通子图。假设 \(G\) 中一共有 \(n\) 个顶点,一颗生成树满足下列条件 \(n\) 个顶点; \(n-1\) 条边; \(n\) 个顶点联通; 一个图的生成树可能有多个。 最小生成树(minimum spanning tree, MST)/最小生成森林 :联通加权无向图中边缘权重加和最小的生成树。给定无向图 \(G=(V,E)\) , \((u,v)\) 代表顶点 \(u\) 与顶点 \(v\) 的边, \(w(u,v)\) 代表此边的权重,若存在生成树T使得: \[w(T) = \sum_{(u,v)\in T}w(w,v)\] 最小,则 \(T\) 为 \(G\) 的最小生成树。对于非连通无向图来说,它的每一 连通分量 同样有最小生成树,它们的并被称为 最小生成森林 。最小生成树除了继承生成树的性质之外,还存在下面两个特点: 当图的每一条边的权值都相同时,该图的所有生成树都是最小生成树;...
💡 不断排除不存在解的区间,直至最后剩下一个 这里归纳最重要的部分: 分析题意,挖掘题目中隐含的 单调性; while (left < right) 退出循环的时候有 left == right 成立,因此无需考虑返回 left 还是 right ; 始终思考下一轮搜索区间是什么,如果是 [mid, right] 就对应 left = mid ,如果是 [left, mid - 1] 就对应 right = mid - 1 ,是保留 mid 还是 +1、−1 就在这样的思考中完成; 从一个元素什么时候不是解开始考虑下一轮搜索区间是什么 ,把区间分为 2个部分(一个部分肯定不存在目标元素,另一个部分有可能存在目标元素),问题会变得简单很多,这是一条 非常有用 的经验; 每一轮区间被划分成 2 部分,理解 区间划分 决定中间数取法( 无需记忆,需要练习 + 理解 ),在调试的过程中理解 区间和中间数划分的配对关系: 划分 [left, mid] 与 [mid + 1, right] ,mid 被分到左边,对应 int mid = left + (right - left) / 2 ;...
引入 在具体讲何为「背包 dp」前,先来看如下的例题: 题意概要:有 \( 𝑛\) 个物品和一个容量为 \( 𝑊\) 的背包,每个物品有重量 \(𝑤_𝑖\) 和价值 \(𝑣_𝑖\) 两种属性,要求选若干物品放入背包使背包中物品的总价值最大且背包中物品的总重量不超过背包的容量. 在上述例题中,由于每个物体只有两种可能的状态(取与不取),对应二进制中的 0 和 1,这类问题便被称为「0-1 背包问题」. 0-1背包 解释 例题中已知条件有第 \(𝑖\) 个物品的重量 \(𝑤_𝑖\) ,价值 \(𝑣_𝑖\) ,以及背包的总容量 \(𝑊\) . 设 DP 状态 \(𝑓_{𝑖,𝑗} \) 为在只能放前 \(𝑖\) 个物品的情况下,容量为 \(𝑗\) 的背包所能达到的最大总价值. 考虑转移.假设当前已经处理好了前 \(𝑖 −1 \) 个物品的所有状态,那么对于第 \(𝑖\) 个物品,当其不放入背包时,背包的剩余容量不变,背包中物品的总价值也不变,故这种情况的最大价值为 \(𝑓_{𝑖−1,𝑗}\) ;当其放入背包时,背包的剩余容量会减小 \(𝑤_𝑖\) ,背包中物品的总价值会增大 \(𝑣_𝑖\)...