164. 最大间距 题目 给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。 如果数组元素个数小于 2,则返回 0。 Example 1: Input: [3,6,9,1]
Output: 3
Explanation: The sorted form of the array is [1,3,6,9], either
(3,6) or (6,9) has the maximum difference 3. 题解 如果进行排序,这里会超时。采用桶排序 基础排序算法 的思想,可以在线性时间解决。 首先建立桶,每个桶中只需要存放这个桶中元素的最大值和最小值。 我们期望将数组中的各个数等距离分配,也就是每个桶的长度相同,也就是对于所有桶来说,桶内最大值减去桶内最小值都是一样的。可以当成公式来记。 \[每个桶的长度=\max(1,\lfloor{{\max(nums)-\min(nums)}\over{len(nums)-1}}\rfloor)\tag{1}\]...
Algorithm
2026-04-15
实现 方式一:使用 heapq 标准库 这是 Python 最快、最节省内存的方式,因为 heapq 底层是用 C 语言实现的。 小顶堆 (Min Heap) Python 的 heapq 默认就是小顶堆。 import heapq
# 初始化
min_heap = []
# 添加元素 O(log N)
heapq.heappush(min_heap, 5)
heapq.heappush(min_heap, 2)
heapq.heappush(min_heap, 8)
# 查看堆顶 O(1)
print(min_heap[0]) # 输出: 2
# 弹出堆顶 O(log N)
pop_val = heapq.heappop(min_heap)
print(pop_val) # 输出: 2
print(min_heap) # 输出: [5, 8] (注意:堆内部不一定有序,但堆顶一定是最小的)
# 将已有的列表转化为堆 O(N)
nums = [5, 7, 1, 3]
heapq.heapify(nums)
print(nums) #...
Deep Learning
2026-04-15
现代深度学习库对大多数操作都具有生产级的、高度优化的实现,这并不奇怪。但这些库究竟是什么魔法?他们如何能够将性能提高100倍?究竟怎样才能“优化”或加速神经网络的运行呢?在讨论高性能/高效DNNs时,我经常会问(也经常被问到)这些问题。 在这篇文章中,我将尝试带你了解在DNN库中卷积层是如何实现的。它不仅是在模型中最常见的和最重的操作,我还发现卷积高性能实现的技巧特别具有代表性——一点点算法的小聪明,非常多的仔细的调优和低层架构的开发。 我在这里介绍的很多内容都来自Goto等人的开创性论文:Anatomy of a high-performance matrix multiplication,该论文为OpenBLAS等线性代数库中使用的算法奠定了基础。 最原始的卷积实现 “过早的优化是万恶之源”——Donald Knuth 在进行优化之前,我们先了解一下基线和瓶颈。这是一个朴素的numpy/for循环卷积: '''
Convolve `input` with `kernel` to generate `output`
input.shape =...
Deep Learning
2026-04-15

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 Upsampling(上采样)[没有学习过程] 在FCN、U-net等网络结构中,涉及到了上采样。上采样概念: 上采样指的是任何可以让图像变成更高分辨率的技术 。最简单的方式是 重采样和插值 :将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在 torch.nn 中的 Vision Layers 里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d PixelShuffle 当stride = (1/r) < 1时,可以让卷积后的feature map变大——即分辨率变大,这个新的操作叫做sub-pixel convolution,具体原理可以看 “PixelShuffle:Real-Time Single Image and Video...
NLP
2026-04-15
Self-Supervised Learning ,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种 通用的特征表达 用于 下游任务 (Downstream Tasks) 。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。 本文主要介绍 Self-Supervised Learning 在 NLP领域 的经典工作:BERT模型的原理及其变体。 本文来自台湾大学李宏毅老师PPT: https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/bert_v8.pdf 芝麻街 在介绍 Self-Supervised Learning...
Self-Supervised
2026-04-15
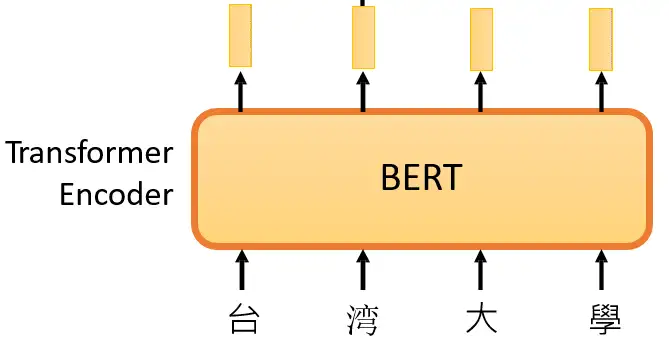
BERT 方法回顾 在 大规模预训练模型BERT 里面我们介绍了 BERT 的自监督预训练的方法,BERT 可以做的事情也就是Transformer 的 Encoder 可以做的事情,就是输入一排向量,输出另外一排向量,输入和输出的维度是一致的。那么不仅仅是一句话可以看做是一个sequence,一段语音也可以看做是一个sequence,甚至一个image也可以看做是一个sequence。所以BERT其实不仅可以用在NLP上,还可以用在CV里面。所以BERT其实输入的是一段文字,如下图所示。 BERT的架构就是Transformer 的 Encoder 接下来要做的事情是把这段输入文字里面的一部分随机盖住。随机盖住有 2 种,一种是直接用一个Mask 把要盖住的token (对中文来说就是一个字)给Mask掉,具体是换成一个 特殊的字符 。另一种做法是把这个token替换成一个随机的token。 把这段输入文字里面的一部分随机盖住 具体BERT详情可以参考: 大规模预训练模型BERT BERT 可以直接用在视觉任务上吗? 上面的 BERT 都是在 NLP 任务上使用,因为 NLP...
Computer Vision
2026-04-15

原理分析 网络架构 本文的任务是Object detection,用到的工具是Transformers,特点是End-to-end。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。 文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。 在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他的baseline。DETR第一个使用End to End的方式解决检测问题,解决的方法是把检测问题视作是一个set prediction problem,如下图所示。...
Computer Vision
2026-04-15
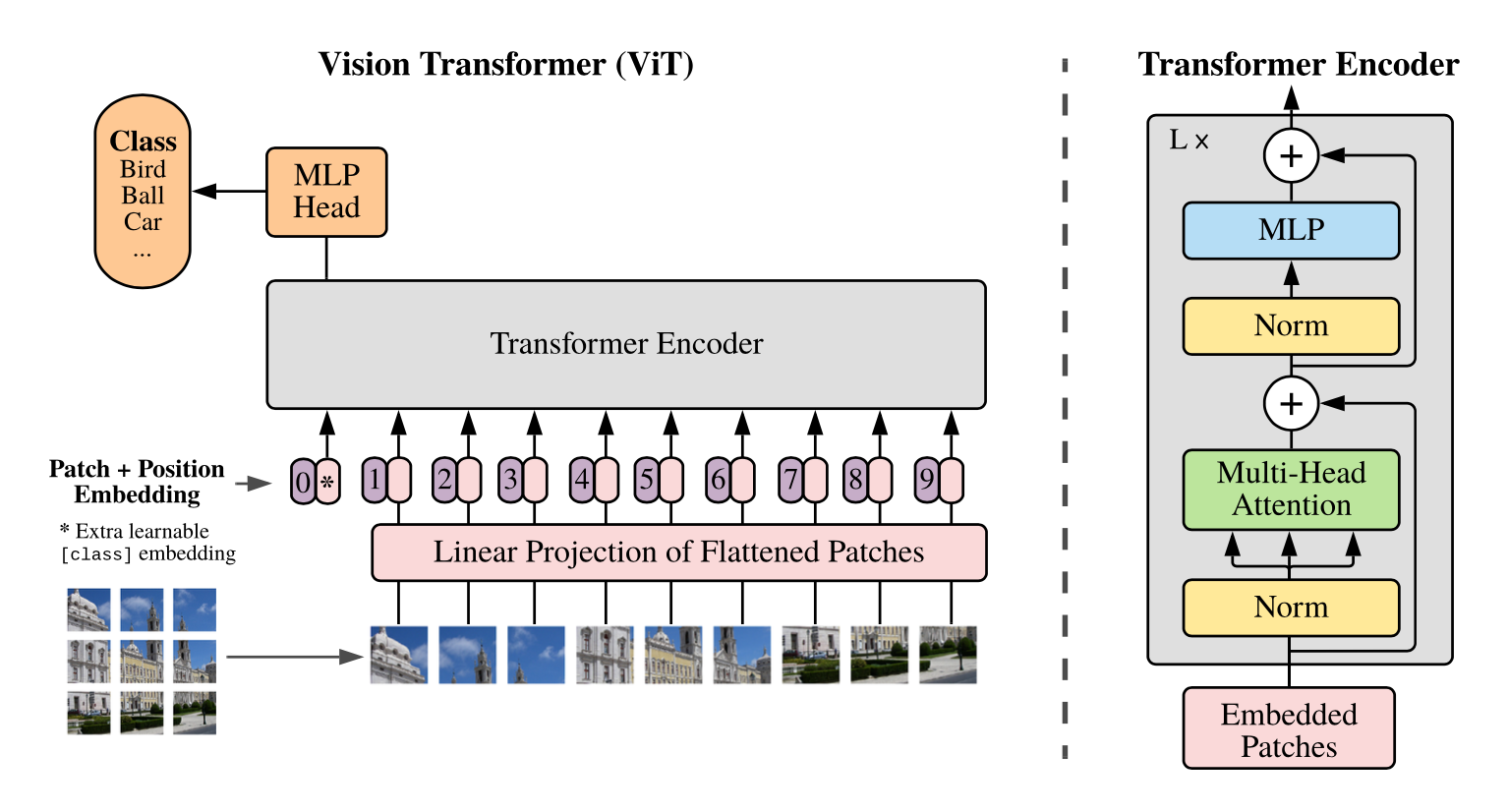
ViT(vision transformer)是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。ViT的思路很简单:直接把图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding,由于transformer的输入就是a sequence of token embeddings,所以将图像的patch embeddings送入transformer后就能够进行特征提取从而分类了。ViT模型原理如下图所示,其实ViT模型只是用了transformer的Encoder来提取特征(原始的transformer还有decoder部分,用于实现sequence to sequence,比如机器翻译)。下面将分别对各个部分做详细的介绍。 Patch Embedding 对于ViT来说,首先要将原始的2-D图像转换成一系列1-D的patch embeddings,这就好似NLP中的word embedding。输入的2-D图像记为 \(x\in...
Computer Vision
2026-04-15

前言 首先看论文题目。Swin Transformer: Hierarchical Vision Transformer using Shifted Windows。即:Swin Transformer是一个用了移动窗口的层级式Vision Transformer 所以Swin来自于 Shifted Windows , 它能够使Vision Transformer像卷积神经网络一样,做层级式的特征提取,这样提取出来的特征具有多尺度的概念 ,这也是 Swin Transformer这篇论文的主要贡献。 标准的Transformer直接用到视觉领域有一些挑战,即: 多尺度问题:比如一张图片里的各种物体尺度不统一,NLP中没有这个问题; 分辨率太大:如果将图片的每一个像素值当作一个token直接输入Transformer,计算量太大,不利于在多种机器视觉任务中的应用。 基于这两点,本文提出了 hierarchical Transformer,通过移动窗口来学习特征。 移动窗口学习,即只在滑动窗口内部计算自注意力,所以称为W-MSA(Window Multi-Self-Attention)。...
Computer Vision
2026-04-15
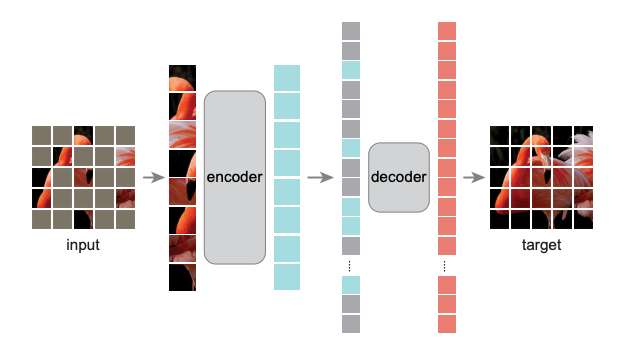
导言 自监督学习(Self-Supervised Learning)能利用大量无标注的数据进行表征学习,然后在特定下游任务上对参数进行微调。通过这样的方式,能够在较少有标注数据上取得优于有监督学习方法的精度。近年来,自监督学习受到了越来越多的关注,如Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。在CV领域涌现了如SwAV、MOCO、DINO、MoBY等一系列工作。MAE是kaiming继MOCO之后在自监督学习领域的又一力作。首先,本文会对MAE进行解读,然后基于EasyCV库的精度复现过程及其中遇到的一些问题作出解答。 概述 MAE的做法很简单:随机mask掉图片中的一些patch,然后通过模型去重建这些丢失的区域。包括两个核心的设计:1.非对称编码-解码结构 2.用较高的掩码率(75%)。通过这两个设计MAE在预训练过程中可以取得3倍以上的训练速度和更高的精度,如ViT-Huge能够通过ImageNet-1K数据上取得87.8%的准确率。 模型拆解...

简介 生成树(spanning tree) 在图论中,无向图 \(G=(V,E)\) 的生成树(spanning tree)是具有 \(G\) 的全部顶点,但边数最少的联通子图。假设 \(G\) 中一共有 \(n\) 个顶点,一颗生成树满足下列条件 \(n\) 个顶点; \(n-1\) 条边; \(n\) 个顶点联通; 一个图的生成树可能有多个。 最小生成树(minimum spanning tree, MST)/最小生成森林 :联通加权无向图中边缘权重加和最小的生成树。给定无向图 \(G=(V,E)\) , \((u,v)\) 代表顶点 \(u\) 与顶点 \(v\) 的边, \(w(u,v)\) 代表此边的权重,若存在生成树T使得: \[w(T) = \sum_{(u,v)\in T}w(w,v)\] 最小,则 \(T\) 为 \(G\) 的最小生成树。对于非连通无向图来说,它的每一 连通分量 同样有最小生成树,它们的并被称为 最小生成森林 。最小生成树除了继承生成树的性质之外,还存在下面两个特点: 当图的每一条边的权值都相同时,该图的所有生成树都是最小生成树;...
💡 不断排除不存在解的区间,直至最后剩下一个 这里归纳最重要的部分: 分析题意,挖掘题目中隐含的 单调性; while (left < right) 退出循环的时候有 left == right 成立,因此无需考虑返回 left 还是 right ; 始终思考下一轮搜索区间是什么,如果是 [mid, right] 就对应 left = mid ,如果是 [left, mid - 1] 就对应 right = mid - 1 ,是保留 mid 还是 +1、−1 就在这样的思考中完成; 从一个元素什么时候不是解开始考虑下一轮搜索区间是什么 ,把区间分为 2个部分(一个部分肯定不存在目标元素,另一个部分有可能存在目标元素),问题会变得简单很多,这是一条 非常有用 的经验; 每一轮区间被划分成 2 部分,理解 区间划分 决定中间数取法( 无需记忆,需要练习 + 理解 ),在调试的过程中理解 区间和中间数划分的配对关系: 划分 [left, mid] 与 [mid + 1, right] ,mid 被分到左边,对应 int mid = left + (right - left) / 2 ;...