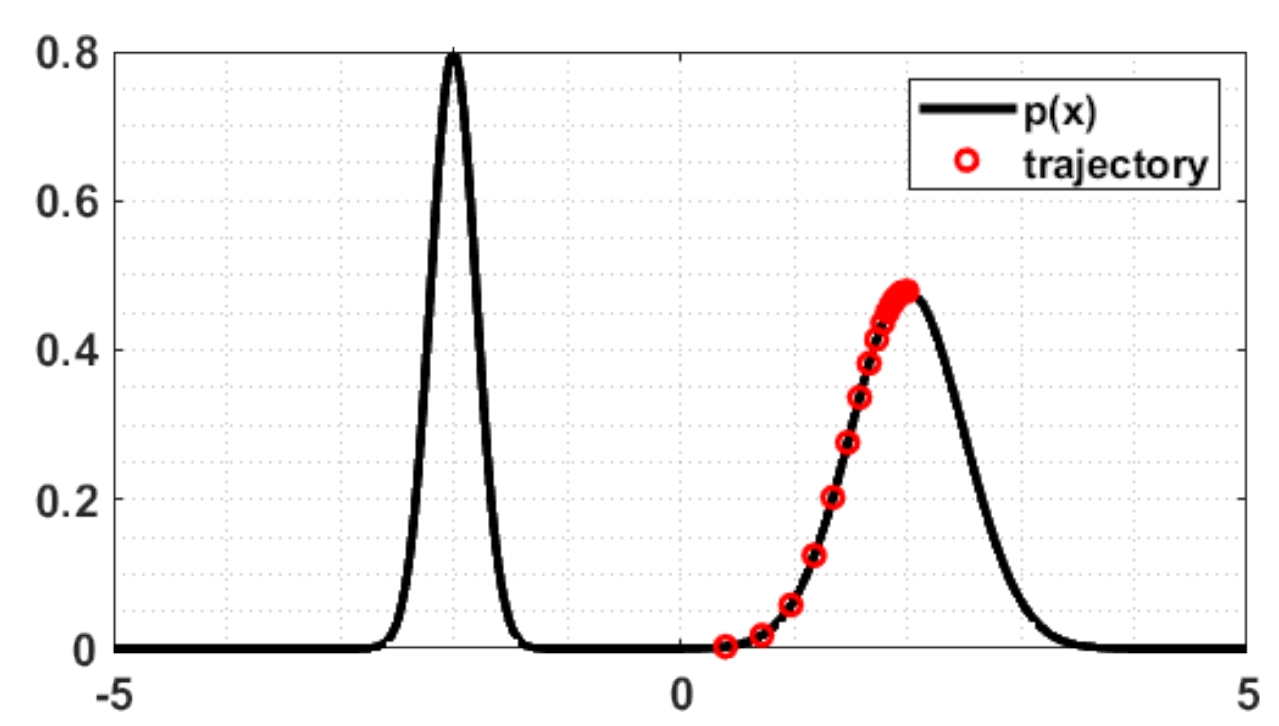
朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 朗之万动力学原理简介 本文的主要内容是基于以下教程: Tutorial on Diffusion Models for Imaging and Vision 此教程写的非常好,非常推荐大家学习。教程的语言风格也很亲切,时不时地蹦出诸如“这是地球人能想出来的公式?”这样的话,为你枯燥的学习过程增添些许趣味。 朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 给定一个已知的概率分布 \(p(x)\) ,我们的目标是采样出概率密度更大的那些样本。解决这个问题有多种方法,比如生成伪随机均匀分布,然后用概率分布变换的方法;或者用马尔可夫链蒙特卡洛方法(MCMC)。而朗之万动力学给出的方法是这样: 随机选取空间中一个点(这是很简单的,采用高斯生成与 \(x\)...
Large Model
2026-04-15

引言 Diffusion模型近年来在图像生成这一连续域任务中取得了显著成果,展现出强大的生成能力。然而,在文本生成这一离散域任务中整体效果仍不尽如人意,未能在该领域引起广泛关注。 去年,一篇研究离散扩散模型在文本生成的文章《Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution》获得ICML 2024的Best Paper,引发了学术界的广泛兴趣,也激发了新一轮的研究热潮。随后在2025年,越来越多高校和企业也开始积极探索基于Diffusion的文本生成方法。其中,近期备受关注的Block Diffusion也成功入选ICLR oral,进一步推动了该方向的发展。...
Large Model
2026-04-15
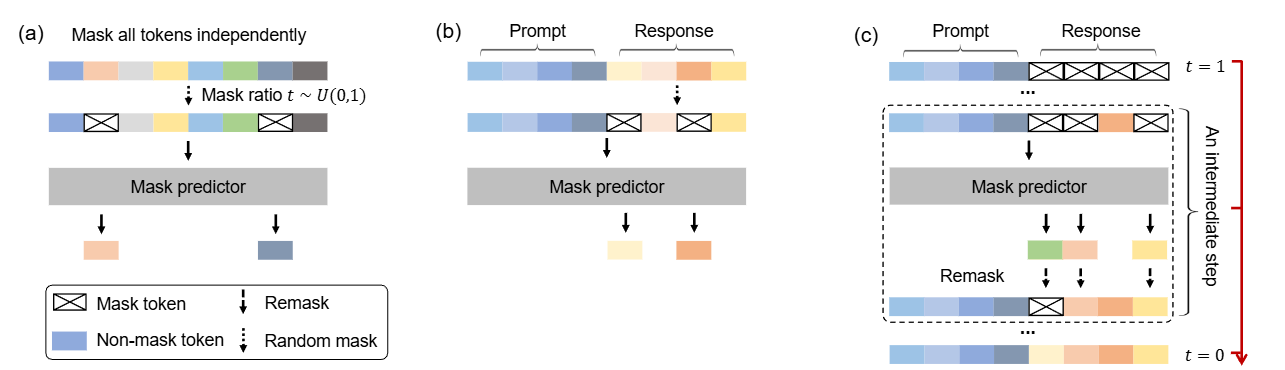
这是一篇尝试改变LLM「范式」的文章:当前主流的LLM架构都是「自回归」的,通俗地理解就是必须「从左到右依次生成」。这篇文章挑战了这一范式,探索扩散模型在 LLMs 上的可行性,通过 随机掩码 - 预测 的逆向思维,让模型学会「全局思考」。 论文: [2502.09992] Large Language Diffusion Models 背景 主流大语言模型架构:自回归模型 (Autoregressive LLMs) 过去几年, 自回归模型(Autoregressive Models, ARMs)一直是大语言模型(LLM)的主流架构。典型的自回归语言模型以Transformer解码器为基础,按照从左到右 的顺序依次预测下一个词元(token)。 形式化地,自回归模型将一个长度为 \(N\) 的文本序列 \(X=(x_1, x_2, ..., x_N)\) 的概率分解为各位置的条件概率连乘积: \[P_{\theta}(x_1, x_2, \dots, x_N) = \prod_{i=1}^{N} P_{\theta}(x_i \mid x_1, x_2, \dots,...
Generative Model
2026-04-15

1-Rectified Flow 可以认为是 flow matching的ot最优传输形式 Rectified Flow目的是将多对多无约束映射 转变成 一对一有约束映射。 ode会保证路径是“因果”的,也就是避免相交的情况 2-Rectified Flow或者叫Reflow 核心的实际上是加噪过程的样本交点数目降低,交点处模型无法精确学习向量场,交点数少了,模型在每个点预测都更准了,加噪过程是直线,所以能更少步数走到起点(但整体采样过程不是直线) 原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE 。 细想上述过程, 可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了 。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。 Rectified Flow 理论推导 微分方程...
Search&Rec
2026-04-15
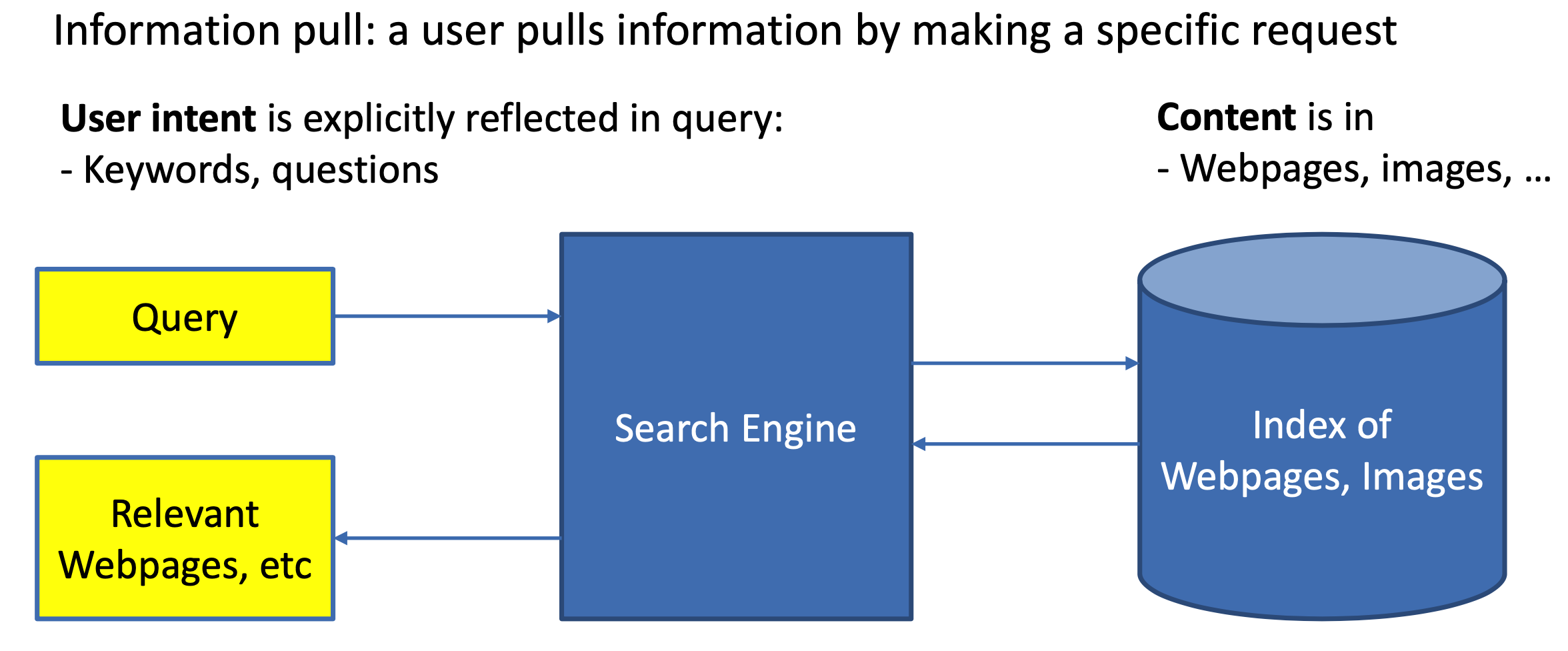
搜索引擎概述 推荐和搜索比较 推荐系统和搜索应该是机器学习乃至深度学习在工业界落地应用最多也最容易变现的场景。而无论是搜索还是推荐,本质其实都是匹配,搜索的本质是给定query,匹配doc;推荐的本质是给定user,推荐item。 对于搜索来说,搜索引擎的本质是对于用户给定query,搜索引擎通过query-doc的match匹配,返回用户最可能点击的文档的过程。从某种意义上来说,query代表的是一类用户,就是对于给定的query,搜索引擎要解决的就是query和doc的match,如图1.1所示。 图1.1 搜索引擎架构 对于推荐来说,推荐系统就是系统根据用户的属性(如性别、年龄、学历等),用户在系统里过去的行为(例如浏览、点击、搜索、收藏等),以及当前上下文环境(如网络、手机设备等),从而给用户推荐用户可能感兴趣的物品(如电商的商品、feeds推荐的新闻、应用商店推荐的app等),从这个过程来看,推荐系统要解决的就是user和item的match,如图1.2所示。 图1.2 推荐引擎架构 不同之处 意图不同...
Search&Rec
2026-04-15

讨论一下推荐系统三板斧: 数据、特征和模型 ,因为搜索的排序套路和推荐十分类似,除了多了query维度特征,对相关性有一定的要求,其他很大程度上思想一致。 这里先行引用一个比较形象的推荐系统优化流程: 明确业务目标 将业务目标转化为机器学习可优化目标 样本收集 特征工程 模型选择和训练 离线评测验证 在线AB验证 通过离线验证和在线AB的结果反馈到2,形成一个增强回路慢慢起飞。 而在一般情况下,各个环节的贡献占比:样本>>特征工程>模型。另外如果离线验证集85分,线上很多时候也会略低,各种原因也不胜枚举:特征延迟、特征不一致、甚至在样本落盘时的数据丢失等等。 本篇先行介绍上述过程特征工程的一般方法,包括特征设计、清洗、变换以及特征选择,并在最后讨论深度学习背景下的特征工程。 特征设计 特征工程的第一步是要找到对模型预测有用的特征,最常用的方式是基于经验 分维度梳理 ,如电商领域第一层可以按场景元素分成 User特征、Item特征、Seller特征、Query特征、上下文特征等...
Search&Rec
2026-04-15
CTR预测问题简介 点击率(Click Through Rate, CTR)预估是程序化广告里的一个最基本而又最重要的问题。比如在竞价广告里,排序的依据就是 \(𝑐𝑡𝑟×𝑏𝑖𝑑\) 。通过选择 \(𝑐𝑡𝑟×𝑏𝑖𝑑\) 最大的广告就能最大化平台的eCPM。从机器学习的角度来说这是一个普通的回归问题,但是它的特殊性在于训练数据只有0/1的值——因为我们没有办法给同一个用户展示同一个广告1万次,然后统计点击的次数来估计真实的点击率。另外有人也许会有这样的看法:对于某一个特定的曝光,某个用户是否点击某个广告是确定的,第一次不点,第二次也不会点,因此点击率是一个0/1的固定值而不是一个0-1之间的概率值。这个说法有一些道理,原因是第二次实验和第一次使用不是独立同分布的。“真正”的做法是第二次做实验前要擦除用户第一次实验的记忆,然后在一模一样的场景(时间、地点……)下做 \(N\)...
Search&Rec
2026-04-15
Learning to rank 排序学习是推荐、搜索、广告的核心方法。排序结果的好坏很大程度影响用户体验、广告收入等。排序学习可以理解为机器学习中用户排序的方法,这里首先推荐一本微软亚洲研究院刘铁岩老师关于LTR的著作,Learning to Rank for Information Retrieval,书中对排序学习的各种方法做了很好的阐述和总结。我这里是一个超级精简版。 排序学习是一个有监督的机器学习过程,对每一个给定的查询-文档对,抽取特征,通过日志挖掘或者人工标注的方法获得真实数据标注。然后通过排序模型,使得输入能够和实际的数据相似。常用的排序学习分为三种类型:PointWise,PairWise和ListWise。 PointWise 单文档方法的处理对象是单独的一篇文档,将文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档打分,打分结果即是搜索结果...
Search&Rec
2026-04-15
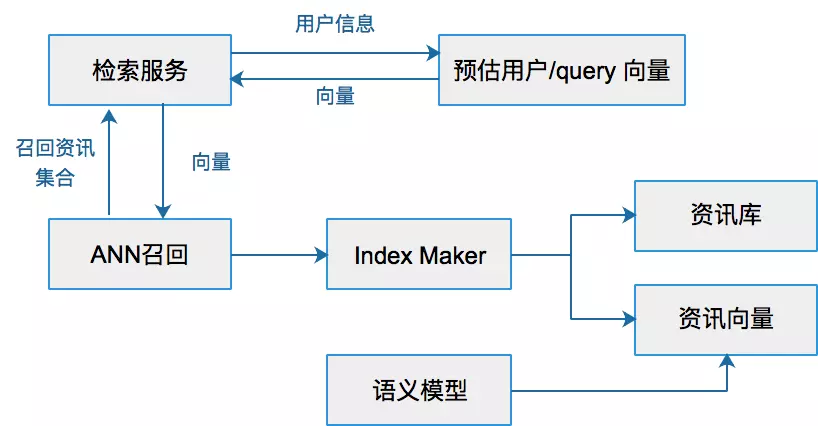
概述 新闻推荐系统从海量新闻中推荐出你感兴趣的新闻,百度从海量的搜索结果中找到最优的结果,短视频推荐出你每天都停不下来的视频流,这些里面都包含ANN方法。当然,在现在的检索系统中,往往是多分支并行触发的效果,虽然DNN 大行其道,但是 ANN 一直不可或缺。 通用理解上,ANN(Approximate Nearest Neighbor)是在向量空间中搜索向量最近邻的优化问题。目前业界常用nmslib、Annoy算法作为实现。在实际的工程应用中,ANN是作为一种向量检索技术应用,用于解决长尾Query召回问题。将一个资讯的ANN 召回系统抽象出来大概是下面的样子。 Ann(approximate nearest neighbor)是指一系列用于解决最近邻查找问题的近似算法。最近邻查找问题,即在给定的向量集合中查找出与目标向量距离最近的N个向量。...
Search&Rec
2026-04-15

一句话总结 正排索引:一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。 倒排索引:Inverted index,指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。 倒排索引创建索引的流程 形成文档列表 首先对原始文档数据进行编号(DocID),形成列表,就是一个文档列表。 创建倒排索引列表 对文档中数据进行分词,得到词条。对词条进行编号,以词条创建索引。保存包含这些词条的文档的编号信息。 搜索的过程 当用户输入任意的词条时,首先对用户输入的数据进行分词,得到用户要搜索的所有词条,然后拿着这些词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号。 然后根据这些编号去文档列表中找到文档 正排和倒排 正排索引(正向索引) 通过文档ID查文档中的各个词:url -> term,ID为关键字,后面的拉链为文档里面每个字的位置信息 正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。...
Generative Model
2026-04-15

DDPM 有一个非常明显的问题:采样过程很慢。因为 DDPM 的反向过程利用了马尔可夫假设, 所以每次都必须在相邻的时间步之间进行去噪,而不能跳过中间步骤 。原始论文使用了 1000 个时间步,所以我们在采样时也需要循环 1000 次去噪过程,这个过程是非常慢的。 为了加速 DDPM 的采样过程,DDIM 在不利用马尔可夫假设的情况下推导出了 diffusion 的反向过程,最终可以实现仅采样 20~100 步的情况下达到和 DDPM 采样 1000 步相近的生成效果,也就是提速 10~50 倍。这篇文章将对 DDIM 的理论进行讲解,并实现 DDIM 采样的代码。 DDPM 的反向过程 首先我们回顾一下 DDPM 反向过程的推导,为了推导出 \(q(\mathbf{x}_{t-1}|\mathbf{x}_t)\) 这个条件概率分布,DDPM 利用贝叶斯公式将其变成了先验分布的组合, 并且通过向条件中加入 \(\mathbf{x}_0 \) 将所有的分布转换为已知分布 :...
Generative Model
2026-04-15
技术分析 从方法上来看,条件控制生成的方式分两种: 事后修改(Classifier-Guidance)和事前训练(Classifier-Free) 。 对于大多数人来说,一个SOTA级别的扩散模型训练成本太大了,而分类器(Classifier)的训练还能接受,所以就想着直接复用别人训练好的无条件扩散模型,用一个分类器来调整生成过程以实现控制生成,这就是事后修改的Classifier-Guidance方案;而对于“财大气粗”的Google、OpenAI等公司来说,它们不缺数据和算力,所以更倾向于往扩散模型的训练过程中就加入条件信号,达到更好的生成效果,这就是事前训练的Classifier-Free方案。 Classifier-Guidance方案最早出自 《Diffusion Models Beat GANs on Image Synthesis》 ,最初就是用来实现按类生成的;后来 《More Control for Free! Image Synthesis with Semantic Diffusion Guidance》...