Deep Learning
2026-04-15
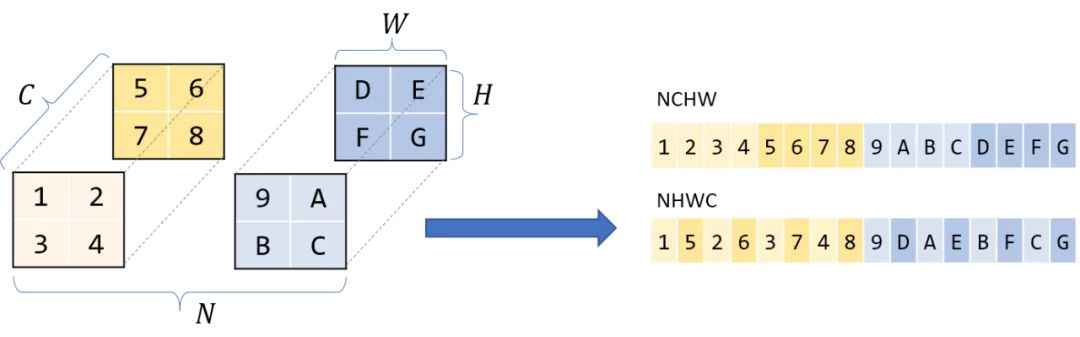
现代深度学习库对大多数操作都具有生产级的、高度优化的实现,这并不奇怪。但这些库究竟是什么魔法?他们如何能够将性能提高100倍?究竟怎样才能“优化”或加速神经网络的运行呢?在讨论高性能/高效DNNs时,我经常会问(也经常被问到)这些问题。 在这篇文章中,我将尝试带你了解在DNN库中卷积层是如何实现的。它不仅是在模型中最常见的和最重的操作,我还发现卷积高性能实现的技巧特别具有代表性——一点点算法的小聪明,非常多的仔细的调优和低层架构的开发。 我在这里介绍的很多内容都来自Goto等人的开创性论文:Anatomy of a high-performance matrix multiplication,该论文为OpenBLAS等线性代数库中使用的算法奠定了基础。 最原始的卷积实现 “过早的优化是万恶之源”——Donald Knuth 在进行优化之前,我们先了解一下基线和瓶颈。这是一个朴素的numpy/for循环卷积: '''
Convolve `input` with `kernel` to generate `output`
input.shape =...








