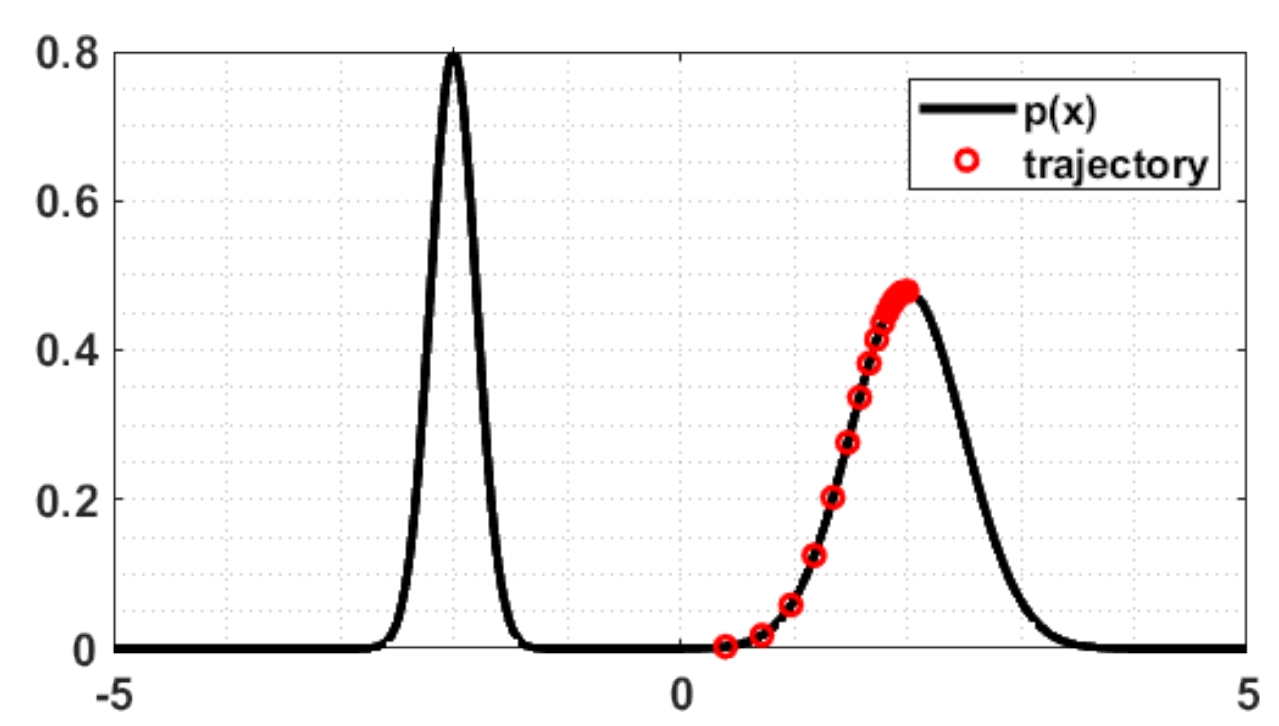
朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 朗之万动力学原理简介 本文的主要内容是基于以下教程: Tutorial on Diffusion Models for Imaging and Vision 此教程写的非常好,非常推荐大家学习。教程的语言风格也很亲切,时不时地蹦出诸如“这是地球人能想出来的公式?”这样的话,为你枯燥的学习过程增添些许趣味。 朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 给定一个已知的概率分布 \(p(x)\) ,我们的目标是采样出概率密度更大的那些样本。解决这个问题有多种方法,比如生成伪随机均匀分布,然后用概率分布变换的方法;或者用马尔可夫链蒙特卡洛方法(MCMC)。而朗之万动力学给出的方法是这样: 随机选取空间中一个点(这是很简单的,采用高斯生成与 \(x\)...
NLP
2026-04-15
Self-Supervised Learning ,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种 通用的特征表达 用于 下游任务 (Downstream Tasks) 。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。 本文主要介绍 Self-Supervised Learning 在 NLP领域 的经典工作:BERT模型的原理及其变体。 本文来自台湾大学李宏毅老师PPT: https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/bert_v8.pdf 芝麻街 在介绍 Self-Supervised Learning...
Self-Supervised
2026-04-15
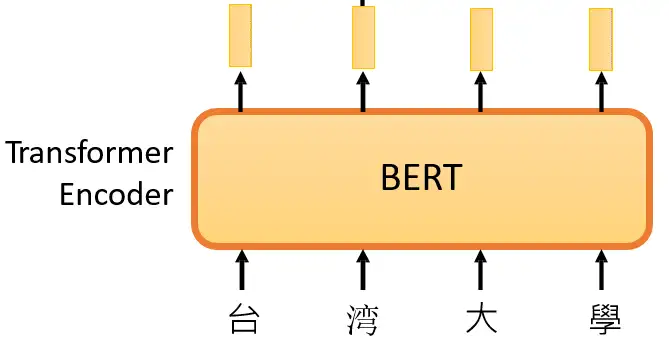
BERT 方法回顾 在 大规模预训练模型BERT 里面我们介绍了 BERT 的自监督预训练的方法,BERT 可以做的事情也就是Transformer 的 Encoder 可以做的事情,就是输入一排向量,输出另外一排向量,输入和输出的维度是一致的。那么不仅仅是一句话可以看做是一个sequence,一段语音也可以看做是一个sequence,甚至一个image也可以看做是一个sequence。所以BERT其实不仅可以用在NLP上,还可以用在CV里面。所以BERT其实输入的是一段文字,如下图所示。 BERT的架构就是Transformer 的 Encoder 接下来要做的事情是把这段输入文字里面的一部分随机盖住。随机盖住有 2 种,一种是直接用一个Mask 把要盖住的token (对中文来说就是一个字)给Mask掉,具体是换成一个 特殊的字符 。另一种做法是把这个token替换成一个随机的token。 把这段输入文字里面的一部分随机盖住 具体BERT详情可以参考: 大规模预训练模型BERT BERT 可以直接用在视觉任务上吗? 上面的 BERT 都是在 NLP 任务上使用,因为 NLP...
Computer Vision
2026-04-15

原理分析 网络架构 本文的任务是Object detection,用到的工具是Transformers,特点是End-to-end。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。 文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。 在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他的baseline。DETR第一个使用End to End的方式解决检测问题,解决的方法是把检测问题视作是一个set prediction problem,如下图所示。...
Computer Vision
2026-04-15
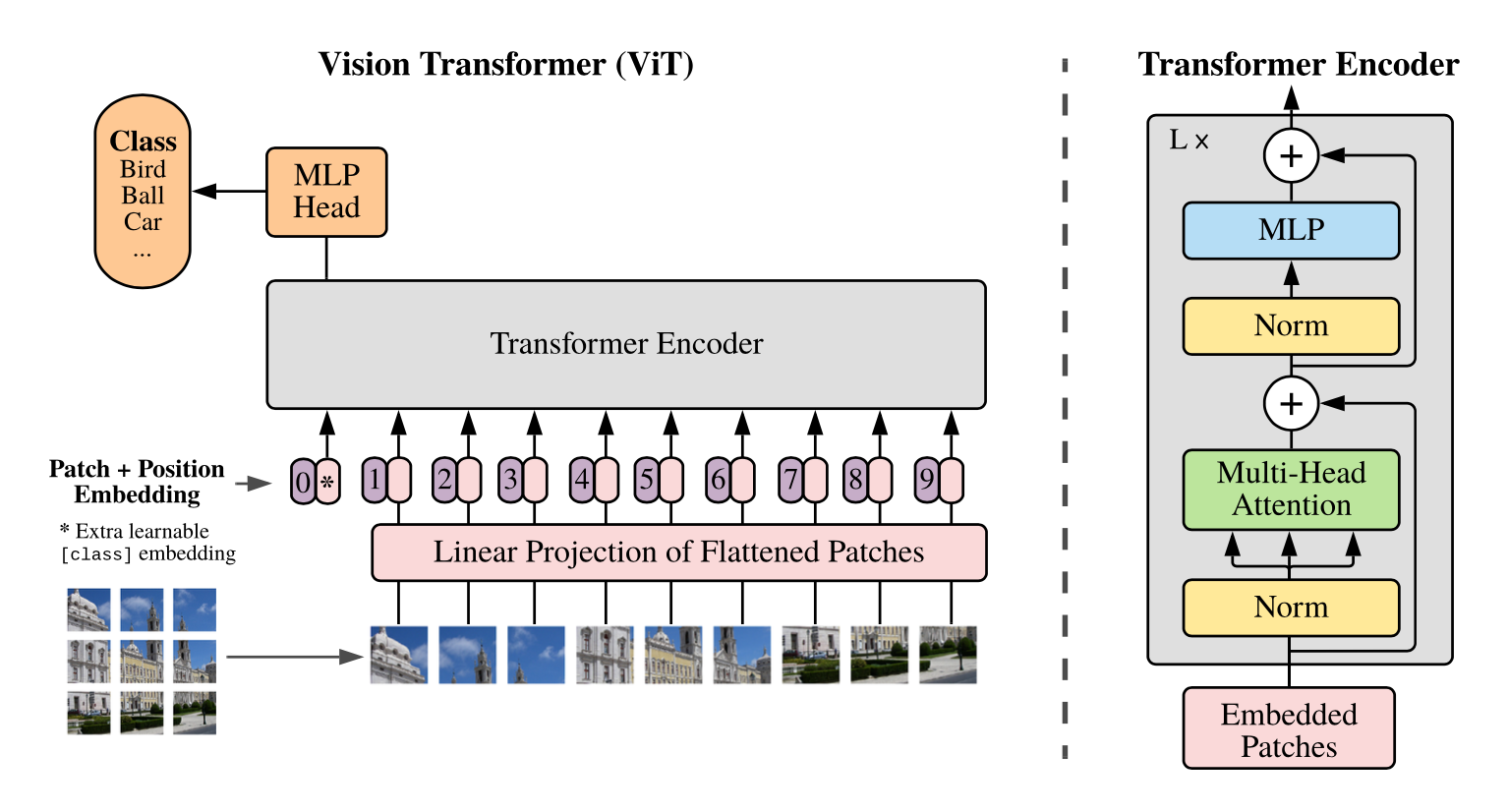
ViT(vision transformer)是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。ViT的思路很简单:直接把图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding,由于transformer的输入就是a sequence of token embeddings,所以将图像的patch embeddings送入transformer后就能够进行特征提取从而分类了。ViT模型原理如下图所示,其实ViT模型只是用了transformer的Encoder来提取特征(原始的transformer还有decoder部分,用于实现sequence to sequence,比如机器翻译)。下面将分别对各个部分做详细的介绍。 Patch Embedding 对于ViT来说,首先要将原始的2-D图像转换成一系列1-D的patch embeddings,这就好似NLP中的word embedding。输入的2-D图像记为 \(x\in...
Computer Vision
2026-04-15

前言 首先看论文题目。Swin Transformer: Hierarchical Vision Transformer using Shifted Windows。即:Swin Transformer是一个用了移动窗口的层级式Vision Transformer 所以Swin来自于 Shifted Windows , 它能够使Vision Transformer像卷积神经网络一样,做层级式的特征提取,这样提取出来的特征具有多尺度的概念 ,这也是 Swin Transformer这篇论文的主要贡献。 标准的Transformer直接用到视觉领域有一些挑战,即: 多尺度问题:比如一张图片里的各种物体尺度不统一,NLP中没有这个问题; 分辨率太大:如果将图片的每一个像素值当作一个token直接输入Transformer,计算量太大,不利于在多种机器视觉任务中的应用。 基于这两点,本文提出了 hierarchical Transformer,通过移动窗口来学习特征。 移动窗口学习,即只在滑动窗口内部计算自注意力,所以称为W-MSA(Window Multi-Self-Attention)。...
Computer Vision
2026-04-15
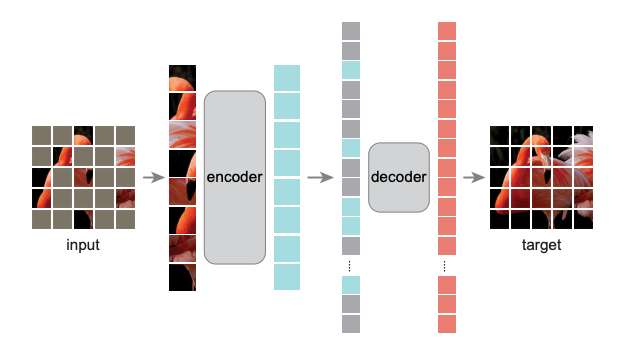
导言 自监督学习(Self-Supervised Learning)能利用大量无标注的数据进行表征学习,然后在特定下游任务上对参数进行微调。通过这样的方式,能够在较少有标注数据上取得优于有监督学习方法的精度。近年来,自监督学习受到了越来越多的关注,如Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。在CV领域涌现了如SwAV、MOCO、DINO、MoBY等一系列工作。MAE是kaiming继MOCO之后在自监督学习领域的又一力作。首先,本文会对MAE进行解读,然后基于EasyCV库的精度复现过程及其中遇到的一些问题作出解答。 概述 MAE的做法很简单:随机mask掉图片中的一些patch,然后通过模型去重建这些丢失的区域。包括两个核心的设计:1.非对称编码-解码结构 2.用较高的掩码率(75%)。通过这两个设计MAE在预训练过程中可以取得3倍以上的训练速度和更高的精度,如ViT-Huge能够通过ImageNet-1K数据上取得87.8%的准确率。 模型拆解...

问题:两条平行线可以相交于一点 在欧氏几何空间,同一平面的两条平行线不能相交,这是我们都熟悉的一种场景。 然而,在透视空间里面,两条平行线可以相交,例如:火车轨道随着我们的视线越来越窄,最后两条平行线在无穷远处交于一点。 欧氏空间(或者笛卡尔空间)描述2D/3D几何非常适合,但是这种方法却不适合处理透视空间的问题(实际上,欧氏几何是透视几何的一个子集合),2维笛卡尔坐标可以表示为 \((x,y)\) 。 如果一个点在无穷远处,这个点的坐标将会 \((∞,∞)\) ,在欧氏空间,这变得没有意义。 平行线在透视空间的无穷远处交于一点,但是在欧氏空间却不能,数学家发现了一种方式来解决这个问题。 方法:齐次坐标 简而言之,齐次坐标就是用 \(N+1\) 维来代表 \(N\) 维坐标 我们可以在一个2D笛卡尔坐标末尾加上一个额外的变量 \(w\) 来形成2D齐次坐标,因此,一个点 \((X,Y)\) 在齐次坐标里面变成了 \((x,y,w)\) ,并且有 \[X = \frac{x}{w} \qquad Y = \frac{y}{w}\] 例如,笛卡尔坐标系下 \((1,2)\)...
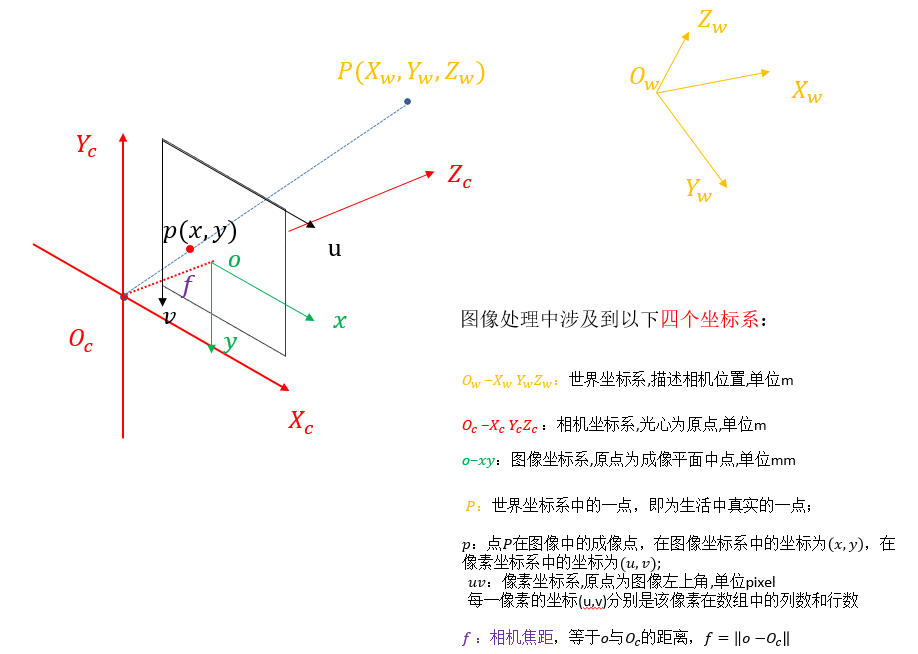
为什么要进行相机标定? 先说结论: 建立相机成像几何模型并矫正透镜畸变 。 建立相机成像几何模型 :计算机视觉的首要任务就是要通过拍摄到的图像信息获取到物体在真实三维世界里相对应的信息,于是,建立物体从三维世界映射到相机成像平面这一过程中的几何模型就显得尤为重要,而这一过程最关键的部分就是要得到相机的 内参和外参 (后文有具体解释)。 矫正透镜畸变 :我们最开始接触到的成像方面的知识应该是有关小孔成像的,但是由于这种成像方式只有小孔部分能透过光线就会导致物体的成像亮度很低,于是聪明的人类发明了透镜。虽然亮度问题解决了,但是新的问题又来了:由于透镜的制造工艺,会使成像产生多种形式的 畸变, 于是为了去除畸变(使成像后的图像与真实世界的景象保持一致),人们计算并利用 畸变系数 来矫正这种像差。(虽然理论上可以设计出不产生畸变的透镜,但其制造工艺相对于球面透镜会复杂很多,so相对于复杂且高成本的制造工艺,人们更喜欢用脑子来解决……) 相机标定的原理...
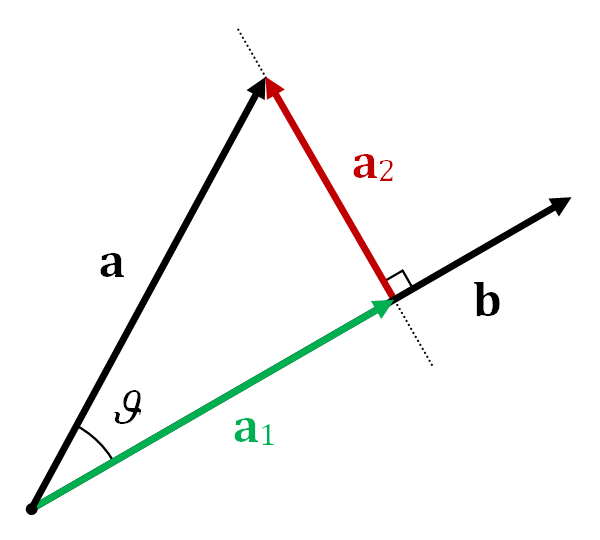
对于向量的三维旋转问题,给定旋转轴和旋转角度,用罗德里格斯(Rodrigues)旋转公式可以得出旋转后的向量。另外,罗德里格斯旋转公式可以用旋转矩阵表示,即将三维旋转的轴-角(axis-angle)表示转变为旋转矩阵表示。 向量投影(Vector projection) 向量 \(a\) 在非零向量 \(b\) 上的向量投影指的是 \(a\) 在平行于向量 \(b\) 的直线上的正交投影。结果是一个平行于 \(b\) 的向量,定义为 \(\mathbf{a}_1=a_1\hat{\mathbf{b}}\) ,其中, \(\mathbf{a}_1\) 是一个标量,称为 \(a\) 在 \(b\) 上的标量投影, \(\hat{\mathbf{b}}\) 是与 \(b \) 同向的单位向量。 \(a_1=\left\Vert\mathbf{a}\right\Vert\cos\theta=\mathbf{a}\cdot \hat{\mathbf{b}}=\mathbf{a}\cdot\frac{\mathbf{b}}{\left\Vert\mathbf{b}\right\Vert}\)...
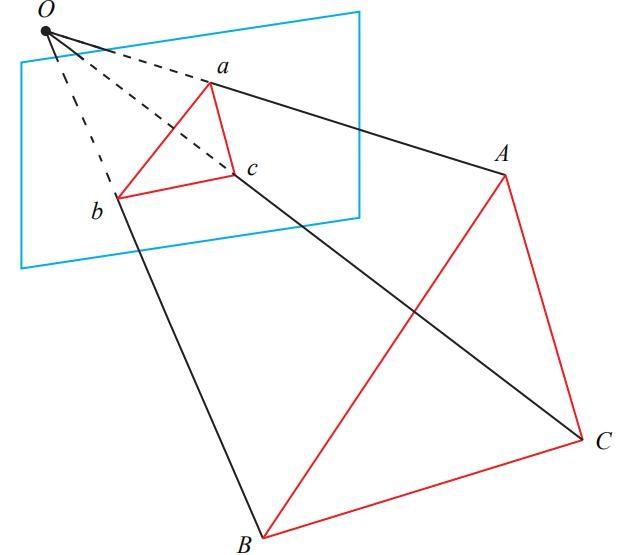
简介 PnP(Perspective-n-Point)是求解3D到2D点对运动的方法,目的是求解相机坐标系相对世界坐标系的位姿。 它描述了已知 \(n\) 个3D点的坐标(相对世界坐标系)以及这些点的像素坐标时,如何估计相机的位姿(即求解世界坐标系到相机坐标系的旋转矩阵 \(R\) 和平移向量 \(t\) )。 用数学公式描述如下: 基本公式: \[\omega \boldsymbol{p}=KP^C=K(R_{CW}\times P^W+t^C_{CW})\] 其中, \(\boldsymbol{p}\) 为点在像素坐标系下的坐标, \(P^C\) 为点在相机坐标系下的坐标, \(P^W\) 为点在世界坐标系下的坐标, \(\omega\) 为点的深度, \(K\) 为相机的内参矩阵, \(R_{CW}\) 和 \(t^C_{CW}\) 为从世界坐标系到相机坐标系的位姿转换。 已知 : \(n\) 个点在 世界坐标系 下的坐标 \(P_1^W,P_2^W,...,P_n^W\) ,这些点相应在 像素坐标系 下的坐标...
3D Model
2026-04-15

本文主要介绍球谐(Spherical Harmonic,简称SH)函数在光照中的一些计算实现,其内容来自于GDC2003的演讲: Spherical Harmonic Lighting: The Gritty Details 学习总结 球谐函数是一组正交基函数,两两相乘的积分结果是0,而自身相乘的积分结果为1,任意信号都可以通过与球谐函数相乘积分算出其在对应球谐函数上的系数,这个过程可以看成是信号在球谐函数上的投影, 通过多个球谐函数按照对应系数累加可以得到原始信号的模拟,参与模拟的球谐函数阶数越高,模拟精度也就越高。 球面坐标系( \(\theta, \phi\) )下面的球谐函数可以表示任意点到球心的距离,而这个距离也可以解读成强度,从而可以用于实现某点处各个方向上的输入光强。 同时,每个点处的输入光强与输出光强的转换关系(BRDF之类)也可以使用球谐函数来表示,实际光照就是上述两个球谐函数相乘的积分输出 ,而在实际计算中,如果在离线的时候完成两个球谐函数的系数的求取,在运行时只需要一个系数向量点乘即可完成,大大简化了计算量,提升了计算速度。 背景简介 球谐光照(SH...