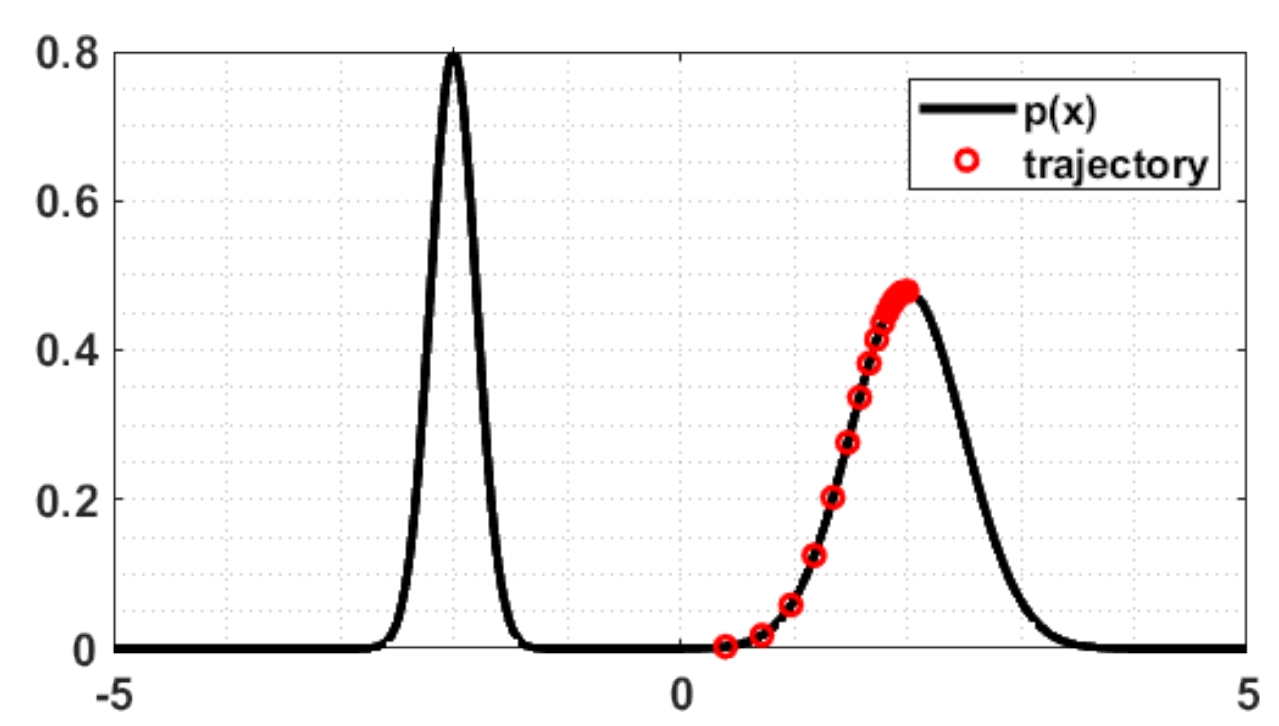
朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 朗之万动力学原理简介 本文的主要内容是基于以下教程: Tutorial on Diffusion Models for Imaging and Vision 此教程写的非常好,非常推荐大家学习。教程的语言风格也很亲切,时不时地蹦出诸如“这是地球人能想出来的公式?”这样的话,为你枯燥的学习过程增添些许趣味。 朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 给定一个已知的概率分布 \(p(x)\) ,我们的目标是采样出概率密度更大的那些样本。解决这个问题有多种方法,比如生成伪随机均匀分布,然后用概率分布变换的方法;或者用马尔可夫链蒙特卡洛方法(MCMC)。而朗之万动力学给出的方法是这样: 随机选取空间中一个点(这是很简单的,采用高斯生成与 \(x\)...
Deep Learning
2026-04-15
机器学习 Hinge Loss Hinge 的叫法来源于其损失函数的图形,为一个折线,通用函数方式为: \[L(m_i) = max(0,1-m_i(w))\] Hinge可以解 间距最大化 问题,带有代表性的就是svm,最初的svm优化函数如下: \[\underset{w,\zeta}{argmin} \frac{1}{2}||w||^2+ C\sum_i \zeta_i \\ st.\quad \forall y_iw^Tx_i \geq 1- \zeta_i \\ \zeta_i \geq 0\] 将约束项进行变形则为: \[\zeta_i \geq 1-y_iw^Tx_i\] 则可以将损失函数进一步写为: \[\begin{aligned}J(w)&=\frac{1}{2}||w||^2 + C\sum_i max(0,1-y_iw^Tx_i) \\ &= \frac{1}{2}||w||^2 + C\sum_i max(0,1-m_i(w)) \\ &= \frac{1}{2}||w||^2 + C\sum_i L_{Linge}(m_i) \end{aligned}\]...
Generative Model
2026-04-15

背景 本文主要是 《NICE: Non-linear Independent Components Estimation》 一文的介绍和实现。这篇文章也是glow这个模型的基础文章之一,可以说它就是glow的奠基石。 艰难的分布 众所周知,目前主流的生成模型包括VAE和GAN,但事实上除了这两个之外,还有基于flow的模型(flow可以直接翻译为“流”,它的概念我们后面再介绍)。事实上flow的历史和VAE、GAN它们一样悠久,但是flow却鲜为人知。在我看来,大概原因是flow找不到像GAN一样的诸如“造假者-鉴别者”的直观解释吧,因为flow整体偏数学化,加上早期效果没有特别好但计算量又特别大,所以很难让人提起兴趣来。不过现在看来,OpenAI的这个好得让人惊叹的、基于flow的glow模型,估计会让更多的人投入到flow模型的改进中。 glow模型生成的高清人脸 生成模型的本质,就是希望用一个我们知道的概率模型来拟合所给的数据样本, 也就是说,我们得写出一个带参数 \(𝜃\) 的分布 \(q_{\boldsymbol{\theta}}(\boldsymbol{x})\)...
Generative Model
2026-04-15
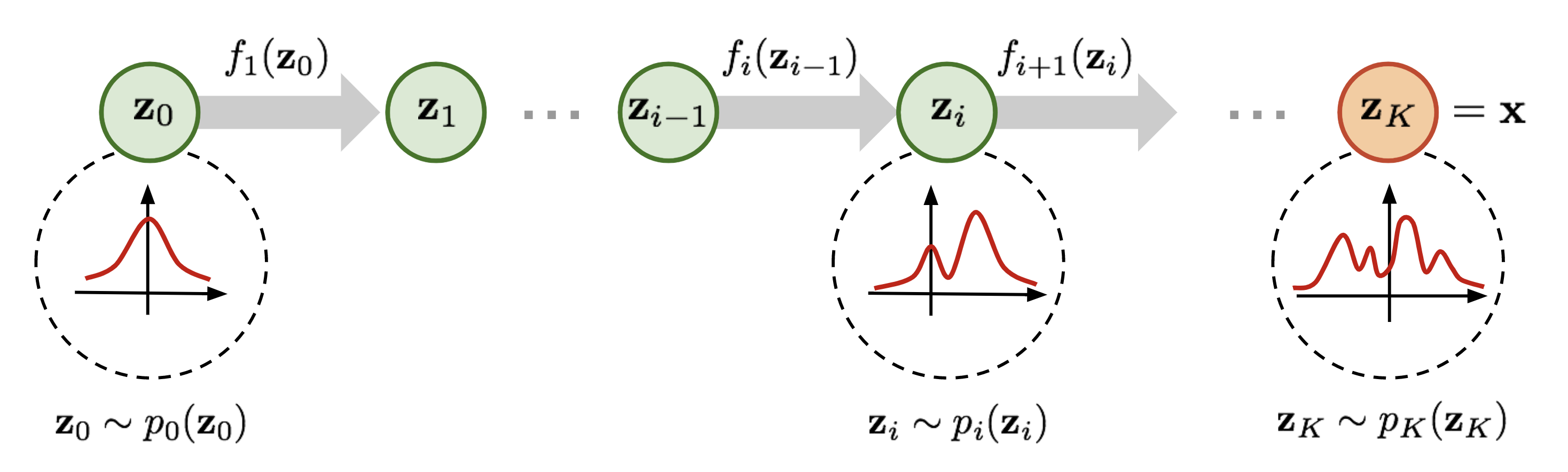
Normalizing flow(标准化流)是一类对概率分布进行建模的工具,它能完成简单的概率分布(例如高斯分布)和任意复杂分布之间的相互转换,经常被用于 data generation、density estimation、inpainting 等任务中,例如 Stability AI 提出的 Stable Diffusion 3 中用到的 rectified flow 就是 normalizing flow 的变体之一。 为了便于理解,在正式开始介绍之前先简要说明一下 normalizing flow 的做法。如上图所示, 为了将一个高斯分布 \(z_0\) 转换为一个复杂的分布 \(z_K\) ,normalizing flow 会对初始的分布 \(z_0\) 进行多次可逆的变换,将其逐渐转换为 \(z_K\) 。由于每一次变换都是可逆的,从 \(z_K\) 出发也能得到高斯分布 \(z_0\) 。这样,我们就实现了复杂分布与高斯分布之间的互相转换,从而能从简单的高斯分布建立任意复杂分布。 对 diffusion models 比较熟悉的读者可能已经发现了,这个过程和...
Generative Model
2026-04-15

1-Rectified Flow 可以认为是 flow matching的ot最优传输形式 Rectified Flow目的是将多对多无约束映射 转变成 一对一有约束映射。 ode会保证路径是“因果”的,也就是避免相交的情况 2-Rectified Flow或者叫Reflow 核心的实际上是加噪过程的样本交点数目降低,交点处模型无法精确学习向量场,交点数少了,模型在每个点预测都更准了,加噪过程是直线,所以能更少步数走到起点(但整体采样过程不是直线) 原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE 。 细想上述过程, 可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了 。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。 Rectified Flow 理论推导 微分方程...
Machine Learning
2026-04-15
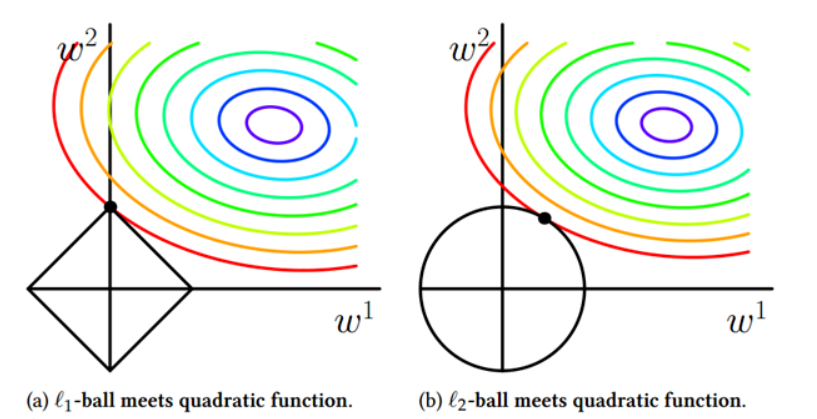
正则化 正则化是一个通用的算法和思想,所有会产生过拟合现象的算法都可以使用正则化来避免过拟合。 在经验风险最小化的基础上(也就是训练误差最小化),尽可能采用简单的模型,可以有效提高泛化预测精度。如果模型过于复杂,变量值稍微有点变动,就会引起预测精度问题。正则化之所以有效,就是因为其降低了特征的权重,使得模型更为简单。 正则化一般会采用 L1 范式或者 L2 范式,其形式分别为 \(\Phi(w)=||x||_1\) 和 \(\Phi(w)=||x||_2\) 。 L1正则化 LASSO 回归,相当于为模型添加了这样一个先验知识: \(w\) 服从零均值拉普拉斯分布。 首先看看拉普拉斯分布长什么样子: \[f(w|\mu,b)=\frac{1}{2b}exp(-\frac{|w-\mu|}{b})\] 由于引入了先验知识,所以似然函数这样写:...
Machine Learning
2026-04-15
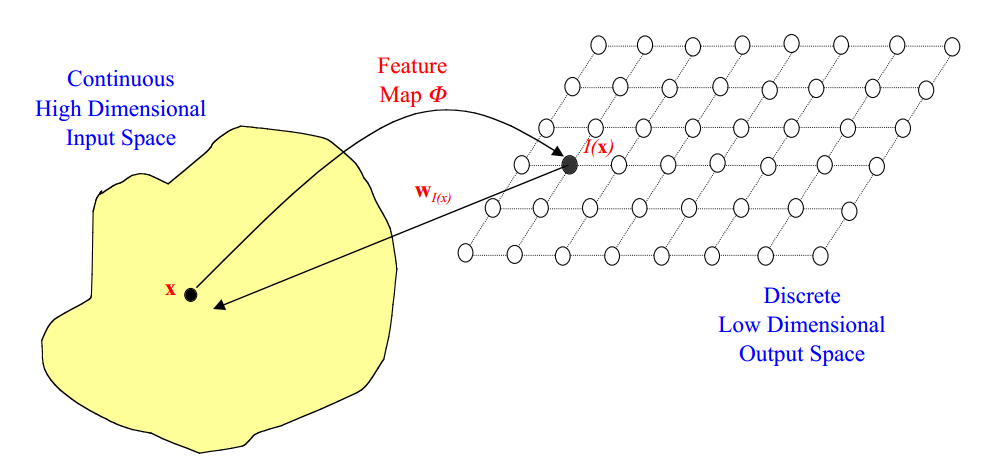
什么是自组织映射? 一个特别有趣的无监督系统是基于 竞争性学习 ,其中输出神经元之间竞争激活,结果是在任意时间只有一个神经元被激活。这个激活的神经元被称为 胜者神经元(winner-takes-all neuron) 。这种竞争可以通过在神经元之间具有 横向抑制连接 (负反馈路径)来实现。其结果是神经元被迫对自身进行重新组合,这样的网络我们称之为 自组织映射(Self Organizing Map,SOM) 。 拓扑映射 神经生物学研究表明,不同的感觉输入(运动,视觉,听觉等)以 有序的方式 映射到大脑皮层的相应区域。 这种映射我们称之为 拓扑映射 ,它具有两个重要特性: 在表示或处理的每个阶段,每一条传入的信息都保存在适当的上下文(相邻节点)中 处理密切相关的信息的神经元之间保持密切,以便它们可以通过短突触连接进行交互 我们的兴趣是建立人工的拓扑映射,以神经生物学激励的方式通过自组织进行学习。 我们将遵循 拓扑映射形成的原则 :“拓扑映射中输出层神经元的空间位置对应于输入空间的特定域或特征”。 建立自组织映射 SOM的主要目标是将任意维度的输入信号模式 转换...
Machine Learning
2026-04-15
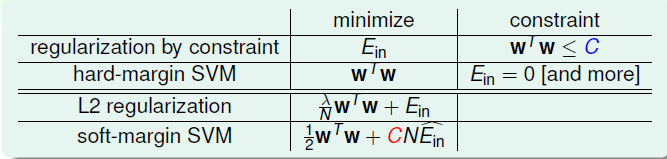
介绍如何将Kernel Trick引入到Logistic Regression,以及LR与SVM的结合 SVM与正则化 首先回顾Soft-Margin SVM的原始问题: \[\begin{aligned}\min\limits_{b,\mathbf{w}, \xi} \quad &\frac{1}{2} \mathbf{w}^T\mathbf{w} + C \cdot \sum\limits_{n=1}^{N}\xi_n \\ s.t. \quad & y_n(\mathbf{w}^T\mathbf{z}^n+b) \geq 1-\xi_n, for \ all\ n \end{aligned}\] 其中 \(ξ_n\) 是训练数据违反边界的多少,没有违反的话, \(ξ_n=0\) ,反之 \(ξ_n>0\) ,换句话说,目标函数的第二项就可以表示模型的损失。现在换一种方式来写,将二者结合起来: \(ξ_n=max(1−y_n(w^Tz^n+b),0)\) ,这一个等式就代表了上面的约束条件,这样上述问题,就与下面的无约束问题等价 \[\begin{aligned} &...
Machine Learning
2026-04-15
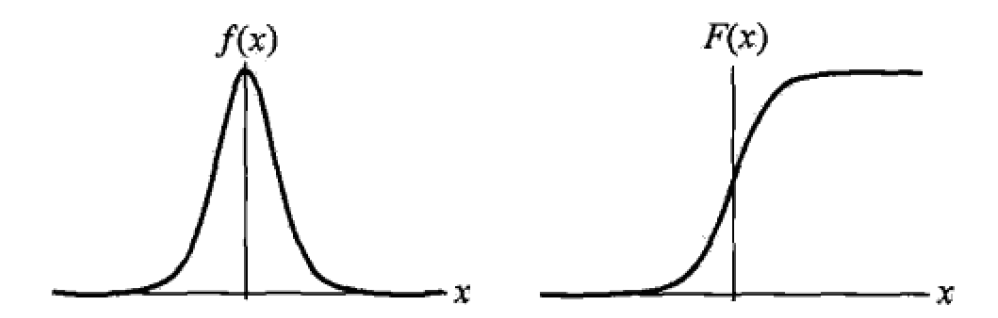
模型介绍 Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。 Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。 Logistic 分布 Logistic 分布是一种连续型的概率分布,其 分布函数 和 密度函数 分别为: \[F(x)=P(X\le x)=\frac{1}{1+e^{-(x-\mu)/\gamma}}\\ f(x)=F^{'}(x)=\frac{e^{-(x-\mu)/\gamma}}{\gamma(1+e^{-(x-\mu)/\gamma})^2}\] 其中, \(\mu\) 表示位置参数, \(\gamma\) 为形状参数。我们可以看下其图像特征: Logistic 分布是由其位置和尺度参数定义的连续分布。Logistic 分布的形状与正态分布的形状相似,但是 Logistic 分布的尾部更长,所以我们可以使用 Logistic...
Machine Learning
2026-04-15
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域算法的基础,比如隐式马尔科夫算法(HMM), LDA主题模型的变分推断等等。本文就对EM算法的原理做一个总结。 EM算法要解决的问题 我们经常会从样本观察数据中,找出样本的模型参数。 最常用的方法就是极大化模型分布的对数似然函数。 但是在一些情况下,我们得到的观察数据有未观察到的隐含数据, 此时我们未知的有隐含数据和模型参数,因而无法直接用极大化对数似然函数得到模型分布的参数 。怎么办呢?这就是EM算法可以派上用场的地方了。 EM算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们 可以先猜想隐含数据(EM算法的E步),接着基于观察数据和猜测的隐含数据一起来极大化对数似然,求解我们的模型参数(EM算法的M步)...
Machine Learning
2026-04-15
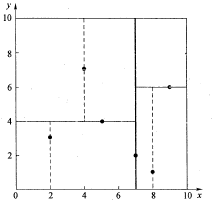
k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构。主要应用于 多维空间关键数据的搜索 (如:范围搜索和最近邻搜索)。 应用背景 SIFT算法中做特征点匹配的时候就会利用到k-d树。而特征点匹配实际上就是一个通过距离函数在高维矢量之间进行相似性检索的问题。针对如何快速而准确地找到查询点的近邻,现在提出了很多高维空间索引结构和近似查询的算法,k-d树就是其中一种。 索引结构中相似性查询有两种基本的方式:一种是范围查询(range searches),另一种是K近邻查询(K-neighbor searches)。范围查询就是给定查询点和查询距离的阈值,从数据集中找出所有与查询点距离小于阈值的数据;K近邻查询是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,就是最近邻查询(nearest neighbor searches)。...
Machine Learning
2026-04-15
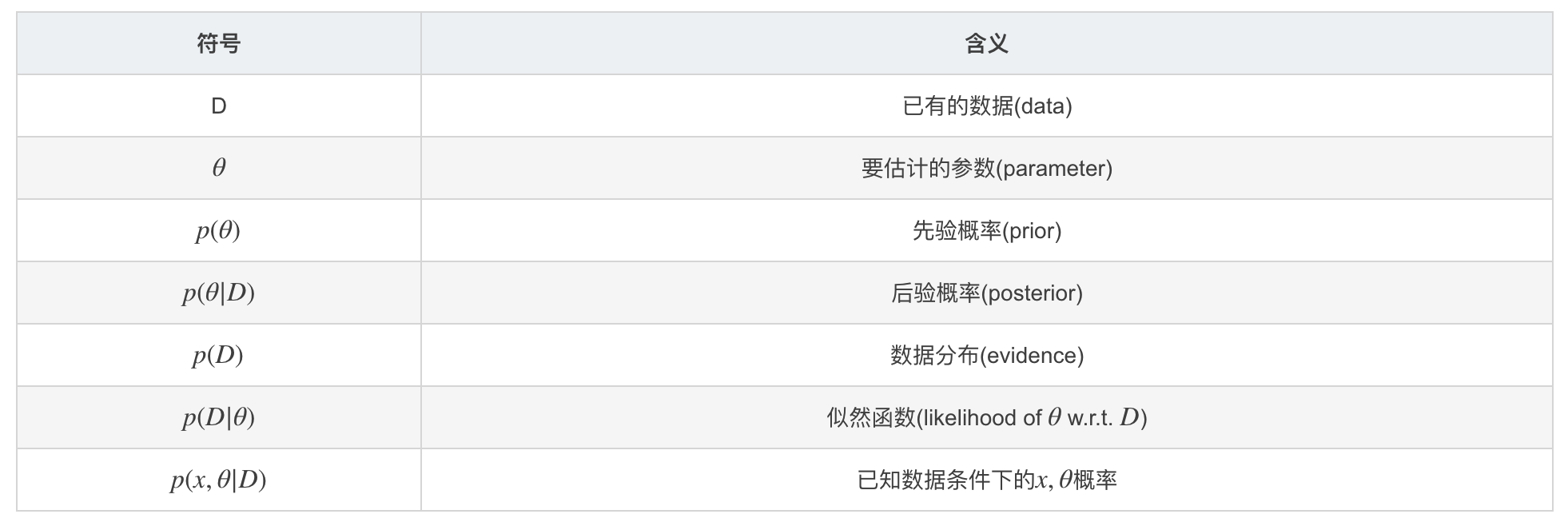
序言 极大似然估计与贝叶斯估计是统计中两种对模型的参数确定的方法,两种参数估计方法使用不同的思想。 前者来自于频率派,认为参数是固定的,我们要做的事情就是根据已经掌握的数据来估计这个参数;而后者属于贝叶斯派,认为参数也是服从某种概率分布的,已有的数据只是在这种参数的分布下产生的。 所以,直观理解上,极大似然估计就是假设一个参数 \(θ\) ,然后根据数据来求出这个 \(θ\) . 而贝叶斯估计的难点在于 \(p(θ)\) 需要人为设定,之后再考虑结合MAP(maximum a posterior)方法来求一个具体的 \(θ\) . 所以极大似然估计与贝叶斯估计最大的不同就在于是否考虑了先验,而两者适用范围也变成了:极大似然估计适用于数据大量,估计的参数能够较好的反映实际情况;而贝叶斯估计则在数据量较少或者比较稀疏的情况下,考虑先验来提升准确率。 预知识 为了更好的讨论,本节会先给出我们要解决的问题,然后给出一个实际的案例。这节不会具体涉及到极大似然估计和贝叶斯估计的细节,但是会提出问题和实例,便于后续方法理解。 问题前提 首先,我们有一堆数据...