Large Model
2026-04-15
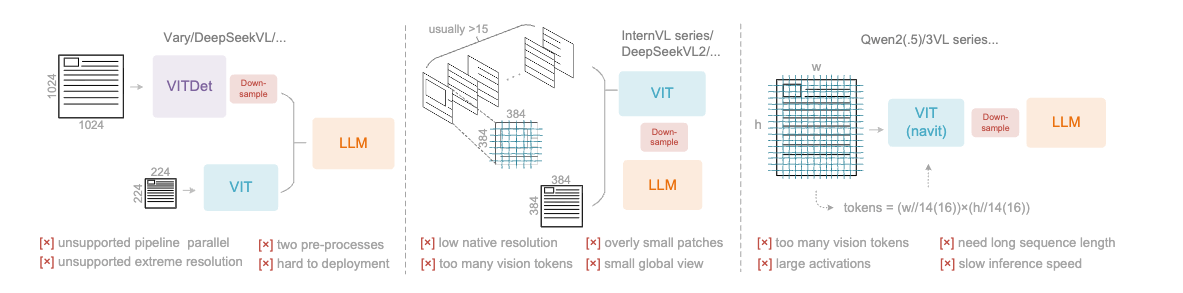
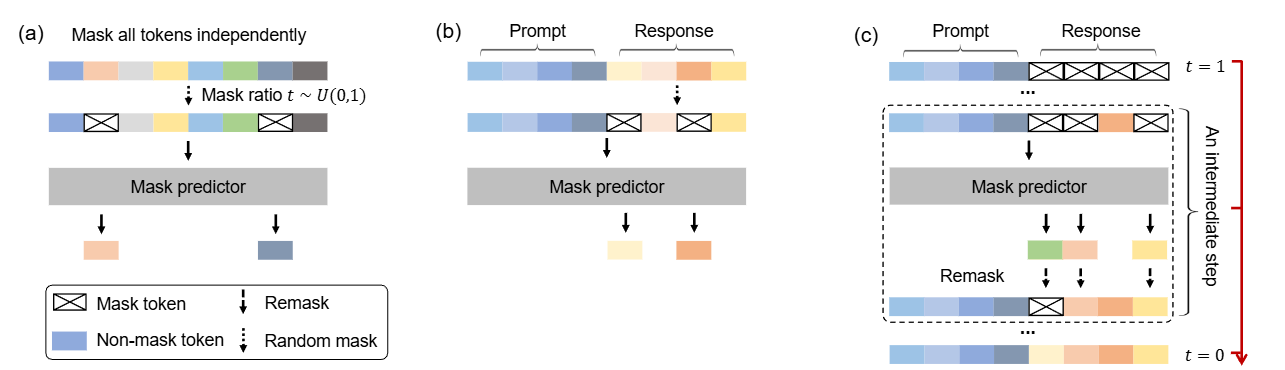
DeeSeek-OCR 简介 当前的大型语言模型(LLMs)在处理长文本时面临显著的计算挑战,其开销随序列长度呈二次增长。本文探索一种潜在的解决方案:将视觉模态作为高效的文本信息压缩媒介。 单张包含文档文本的图像,能够用显著更少的 token 表达丰富信息,相比等量的数字文本更为紧凑;这表明,通过视觉 token 进行光学压缩有望实现更高的压缩比。 本文关注视觉编码器如何提升 LLM 在处理文本信息时的效率,而非人类本就擅长的基础 VQA 任务 当前主流 VLM 视觉编码器的问题 第一类是以 Vary 为代表的双塔(dual-tower)架构,通过并行的 SAM 编码器来提升高分辨率图像处理时的视觉词表参数规模。该方法虽然在参数量与激活内存上更可控,但也存在显著缺点:需要对图像进行两套预处理,增加了部署复杂度;同时在训练中使编码器管线的并行化变得困难。 第二类是以 InternVL2.0 为代表的切片(tile-based)方法,通过将图像划分为小块并行处理,在高分辨率场景下降低激活内存。尽管这种方法能够处理极高分辨率,但由于其原生编码器分辨率通常较低(低于...