
236. 二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百 度百科中最近公共祖先的定义为:“对于有根树 \(T\) 的两个节点 \(p\) 、 \(q\) ,最近公共祖先表示为一个节点 \(x\) ,满足 \(x\) 是 \(p\) 、 \(q \) 的祖先且 \(x\) 的深度尽可能大( 一个节点也可以是它自己的祖先 )。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root = [1,2], p = 1, q = 2
输出:1 提示: 树中节点数目在范围 [2, 10 5 ] 内。 -10 9 <= Node.val <= 10 9 所有 Node.val...
二叉树结构 class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None 递归 时间复杂度: \(O(n)\) , \(n\) 为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度: \(O(h)\) , \(h\) 为树的高度。最坏情况下需要空间 \(O(n)\) ,平均情况为 \(O(logn)\) 递归1: 二叉树遍历最易理解和实现版本 class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
# 前序递归
return [root.val] + self.preorderTraversal(root.left) + self.preorderTraversal(root.right)
...

48. 旋转图像 题目 给定一个 \(n × n\) 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。 请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]] 示例 2: 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]] 提示: n == matrix.length == matrix[i].length 1 <= n <= 20 -1000 <= matrix[i][j] <= 1000 题解 这是一个经典的矩阵操作问题。要在原地(In-place)将图像顺时针旋转 90 度,我们可以利用矩阵的几何性质。 最直观且易于实现的方法是将...
Large Model
2026-04-15

Stanford Alpaca 结合英文语料通过Self Instruct方式微调LLaMA 7B Stanford Alpaca简介 2023年3月中旬,斯坦福的Rohan Taori等人发布Alpaca(中文名:羊驼):号称只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型(即LLaMA 7B), 具体做法是通过52k指令数据,然后在8个80GB A100上训练3个小时,使得Alpaca版的LLaMA 7B在单纯对话上的性能比肩GPT-3.5(text-davinci-003) ,这便是指令调优LLaMA的意义所在 论文《Alpaca: A Strong Open-Source Instruction-Following Model》 GitHub地址: https://github.com/tatsu-lab/stanford_alpaca 数据地址 (即斯坦福团队微调LLaMA 7B所用的52K英文指令数据): raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json...
Large Model
2026-04-15
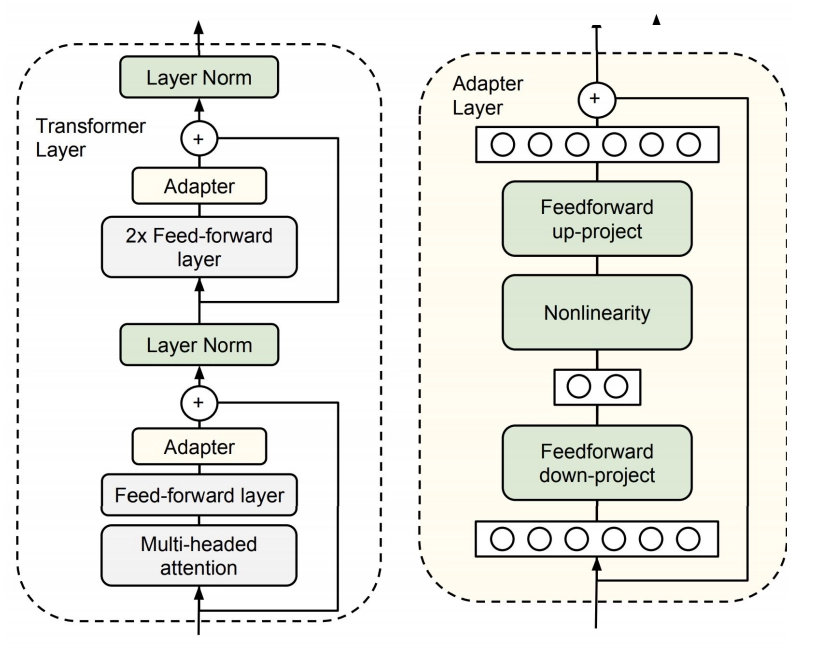
Adapter tuning Adapter Tuning试图在Transformer Layer的Self-Attetion+FFN之后插入一个先降维再升维的MLP(以及一层残差和LayerNormalization)来学习模型微调的知识。 在预训练模型每一层(或某些层)中添加Adapter模块(如上图左侧结构所示),微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。每个Adapter模块由两个前馈子层组成,第一个前馈子层将Transformer块的输出作为输入,将原始输入维度 \(d\) 投影到 \(m\) ,通过控制 \(m\) 的大小来限制Adapter模块的参数量,通常情况下 \(m\ll d\) 。在输出阶段,通过第二个前馈子层还原输入维度,将 \(m\) 重新投影到 \(d\)...