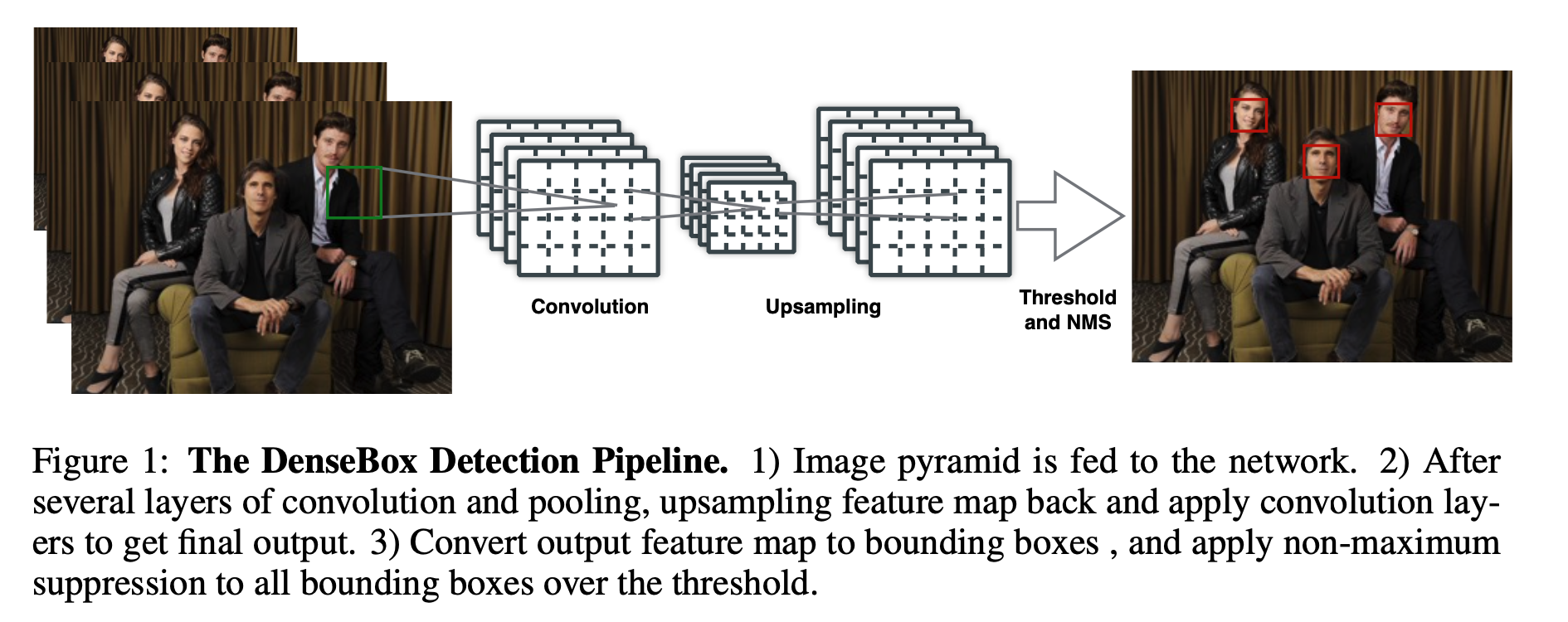
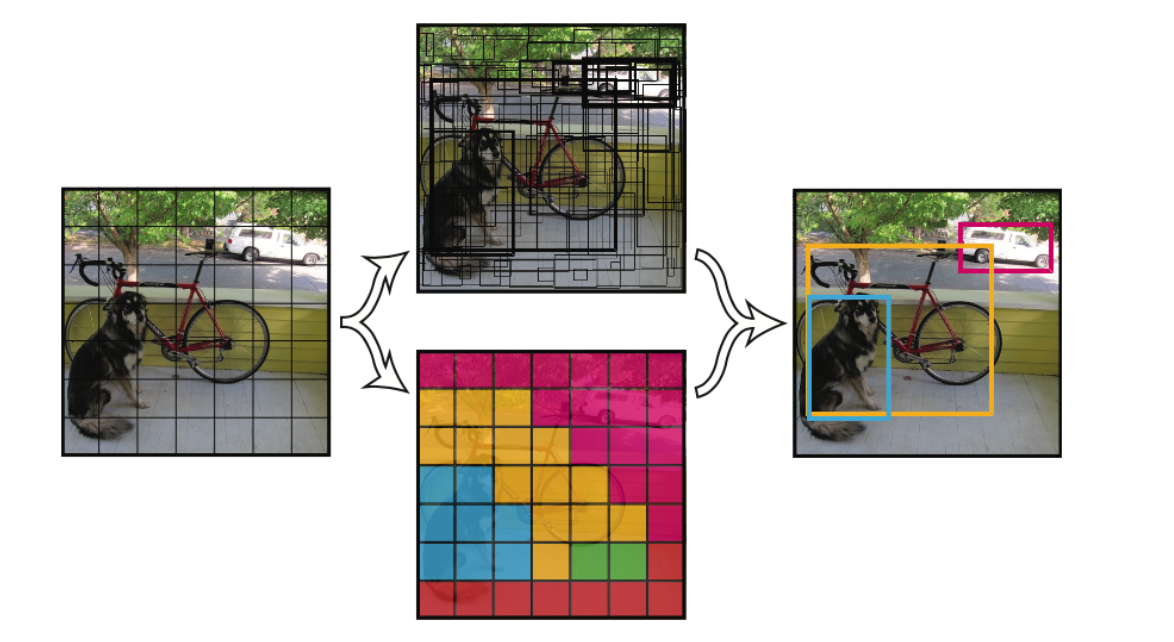
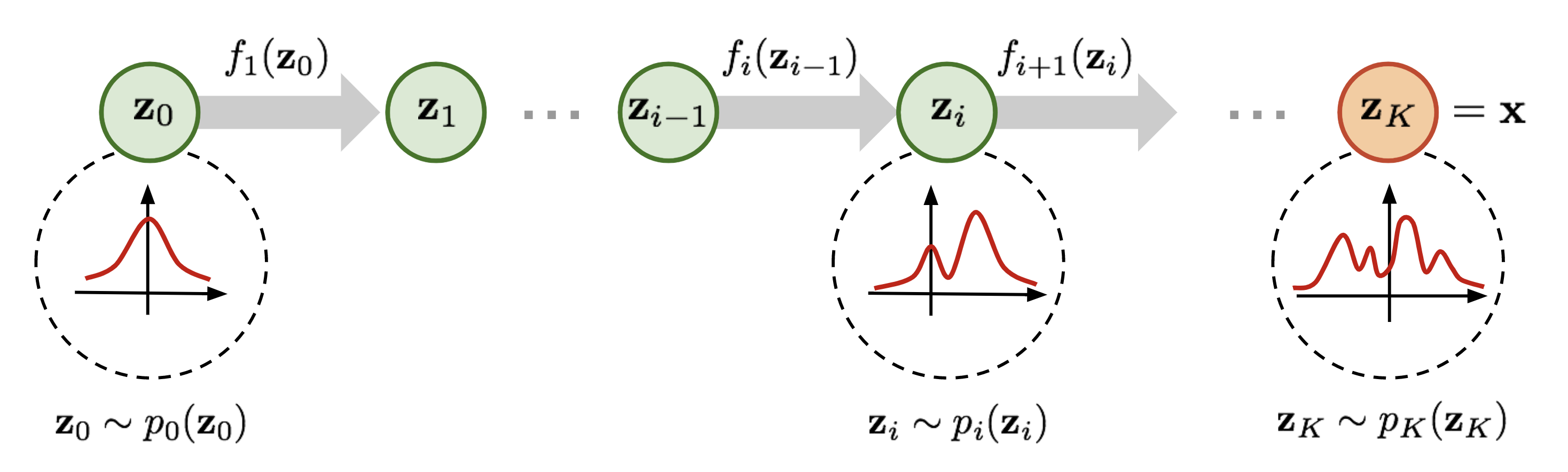
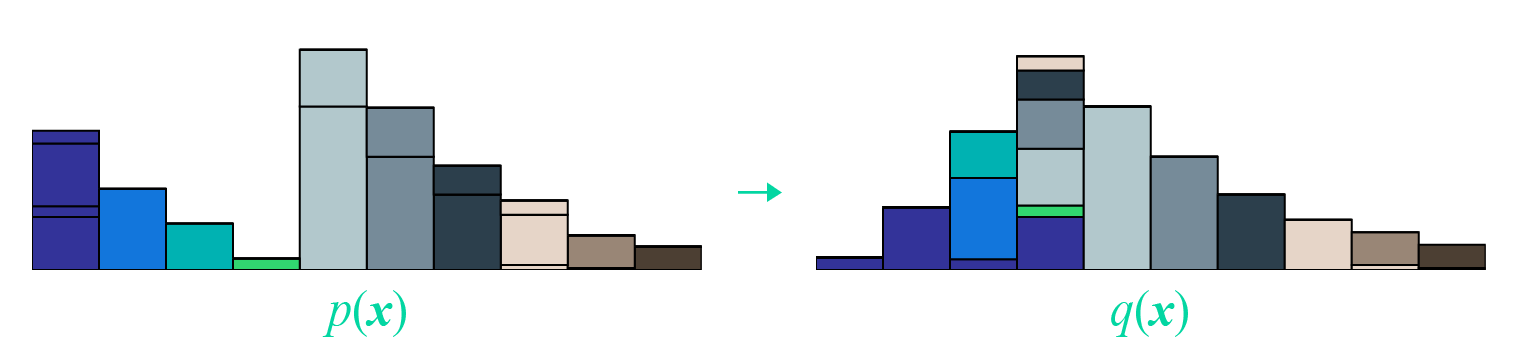
Computer Vision
2026-04-15
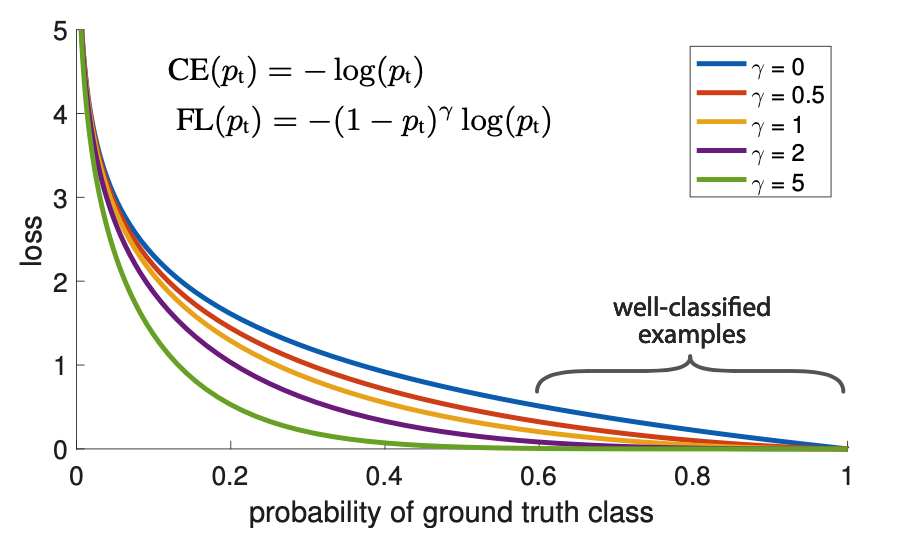
Motivation 我们知道object detection的算法主要可以分为两大类: two-stage detector和one-stage detector 。前者是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。后者是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率不如前者。 作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。 既然有了出发点, 那么就要找one-stage detector的准确率不如two-stage detector的原因,作者认为原因是:样本的类别不均衡导致的 。我们知道在object detection领域,一张图像可能生成成千上万的candidate...