背景 RLHF 通常包括三个阶段: 有监督微调(SFT) RLHF首先通过在高质量数据上进行监督学习来微调预训练的语言模型,得到模型 \(\pi_{SFT}\) 。 奖励建模阶段 (Reward Model) 在第二阶段,SFT模型根据提示 \(x\) 生成答案对 \((y_1, y_2) \sim \pi_{SFT}(y|x)\) 。这些答案对呈现给人类标注者,他们表达对一个答案的偏好,表示为 \(y_w \succ y_l|x\) ,其中 \(y_w\) 和 \(y_l\) 分别表示在 \((y_1, y_2)\) 中更受偏好和不受偏好的答案。 这些偏好被假定由某个潜在的奖励模型 \(r^*(y, x)\) 生成,我们无法直接访问该模型。一种流行的建模偏好的方法是Bradley-Terry(BT)模型,该模型规定人类偏好分布 \(p^*\) 可以写为: \[p^*(y_1 \succ y_2|x) = \frac{\exp(r^*(x, y_1))}{\exp(r^*(x, y_1)) + \exp(r^*(x, y_2))}
\] 假设我们有一个从 \(p^*\)...
Large Model
2026-04-15

简介 24年12月,研究团队开发了 DeepSeek-V3,这是一个基于 MoE 架构的大模型,总参数量达到 671B,其中每个 token 会激活 37B 个参数。 基于提升性能和降低成本的双重目标,在架构设计方面,DeepSeek-V3 采用了 MLA 来确保推理效率,并使用 DeepSeekMoE 来实现经济高效的训练。这两种架构在 DeepSeek-V2 中已经得到验证,证实了它们能够在保持模型性能的同时实现高效的训练和推理。 除了延续这些基础架构外,研究团队还引入了两项创新策略来进一步提升模型性能。 首先,DeepSeek-V3 首创了 无辅助损失的负载均衡 策略(auxiliary-loss-free strategy for load balancing),有效降低了负载均衡对模型性能的负面影响。另外,DeepSeek-V3 采用了 多 token 预测训练目标, 这种方法在评估基准测试中展现出了显著的性能提升。 为了提高训练效率,该研究采用了 FP8 混合精度训练技术...
Large Model
2026-04-15

简介 后训练(post-training)已成为完整训练流程中的重要组成部分。相比于预训练,后训练需要的计算资源相对较少,但能够: 提高推理任务的准确性 使模型与社会价值观保持一致 适应用户偏好 OpenAI 的 o1 系列模型首次引入了通过增加思维链(Chain-of-Thought)推理过程长度来实现推理时间,扩展这种方法在数学、编程和科学推理等各种推理任务上取得了显著改进 研究界已探索多种方法来提高模型的推理能力:比如 基于过程的奖励模型 (Process-based Reward Models) 强化学习 (Reinforcement Learning), 代表工作:InstructGPT, 以及 搜索算法( 蒙特卡洛树搜索(Monte Carlo Tree Search)、束搜索(Beam Search))。然而,这些方法尚未达到与 OpenAI o1 系列模型相当的通用推理性能。 DeepSeek-R1-Zero 本文首先探索使用纯强化学习(RL)来提高语言模型的推理能力,重点关注: 探索 LLM 在没有任何监督数据的情况下,通过纯 RL 过程的自我进化来发展推理能力...
Large Model
2026-04-15

CLIP算法原理 CLIP 不预先定义图像和文本标签类别,直接利用从互联网爬取的 400 million 个image-text pair 进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉分类。简单的说,CLIP 无需利用 ImageNet 的数据和标签进行训练,就可以达到 ResNet50 在 ImageNet数据集上有监督训练的结果,所以叫做 Zero-shot。 CLIP(contrastive language-image pre-training)主要的贡献就是 利用无监督的文本信息,作为监督信号来学习视觉特征 。 CLIP 作者先是回顾了并总结了和上述相关的两条表征学习路线: 构建image和text的联系,比如利用已有的image-text pair数据集,从text中学习image的表征; 获取更多的数据(不要求高质量,也不要求full...
Large Model
2026-04-15

https://www.deepseek.com/ DeepSeek LLM 代码地址: https://github.com/deepseek-ai/DeepSeek-LLM 背景 量化巨头幻方探索AGI(通用人工智能)新组织“深度求索”在成立半年后,发布的第一代大模型,免费商用,完全开源。作为一家隐形的AI巨头,幻方拥有1万枚英伟达A100芯片,有手撸的HAI-LLM训练框架HAI-LLM:高效且轻量的大模型训练工具。 概述 DeepSeek LLMs,这是一系列在2万亿标记的英语和中文大型数据集上从头开始训练的开源模型 在本文中,深入解释了超参数选择、Scaling Laws以及做过的各种微调尝试。校准了先前工作中的Scaling Laws,并提出了新的最优模型/数据扩展-缩放分配策略。此外,还提出了一种方法,使用给定的计算预算来预测近似的batch-size和learning-rate。进一步得出结论,Scaling Laws与数据质量有关,这可能是不同工作中不同扩展行为的原因。在Scaling Laws的指导下,使用最佳超参数进行预训练,并进行全面评估。...
Large Model
2026-04-15

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
Large Model
2026-04-15

项目: https://llava-vl.github.io/ github: https://github.com/haotian-liu/LLaVA 一句话 优点 : 极大简化了VLM的训练方式:Pre-training + Instruction Tuning 训练量得到简化:1M量级数据+ 8卡A100 → 一天完成训练 LLaVA LLaVA是2023的连续工作,包含了LLaVA 1.0, 1.5, 1.6几个版本(后续会有更多),也是2023年多模态领域妥妥的顶流。发表9个月620的stars,GitHub超过12K的stars。 LLaVA它的网络结构简单、微调成本比较低,任何研究组、企业甚至个人都可以基于它构建自己的领域的多模态模型。 非常建议对多模态大模型感兴趣的朋友关注LLaVA这篇工作。 简介...
Large Model
2026-04-15

问题背景 首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗? 其实没那么简单。先看文本生成,事实上文本生成自始至终都只有一条主流路线,那就是语言模型,即建模条件概率 \(p(x_t|x_1,\cdots,x_{t-1})\) ,不论是最初的 n-gram语言模型,还是后来的Seq2Seq、GPT,都是这个条件概率的近似。也就是说,一直以来,人们对“实现文本生成需要往哪个方向走”是很明确的,只是背后所用的模型有所不同,比如LSTM、CNN、Attention乃至最近复兴的线性RNN等。所以, 文本生成确实可以All in Transformer来大力出奇迹,因为方向是标准的、清晰的。 然而,对于图像生成,并没有这样的“标准方向”。就本站所讨论过的图像生成模型,就有 VAE 、 GAN 、 Flow 、 Diffusion ,还有小众的 EBM...
Large Model
2026-04-15
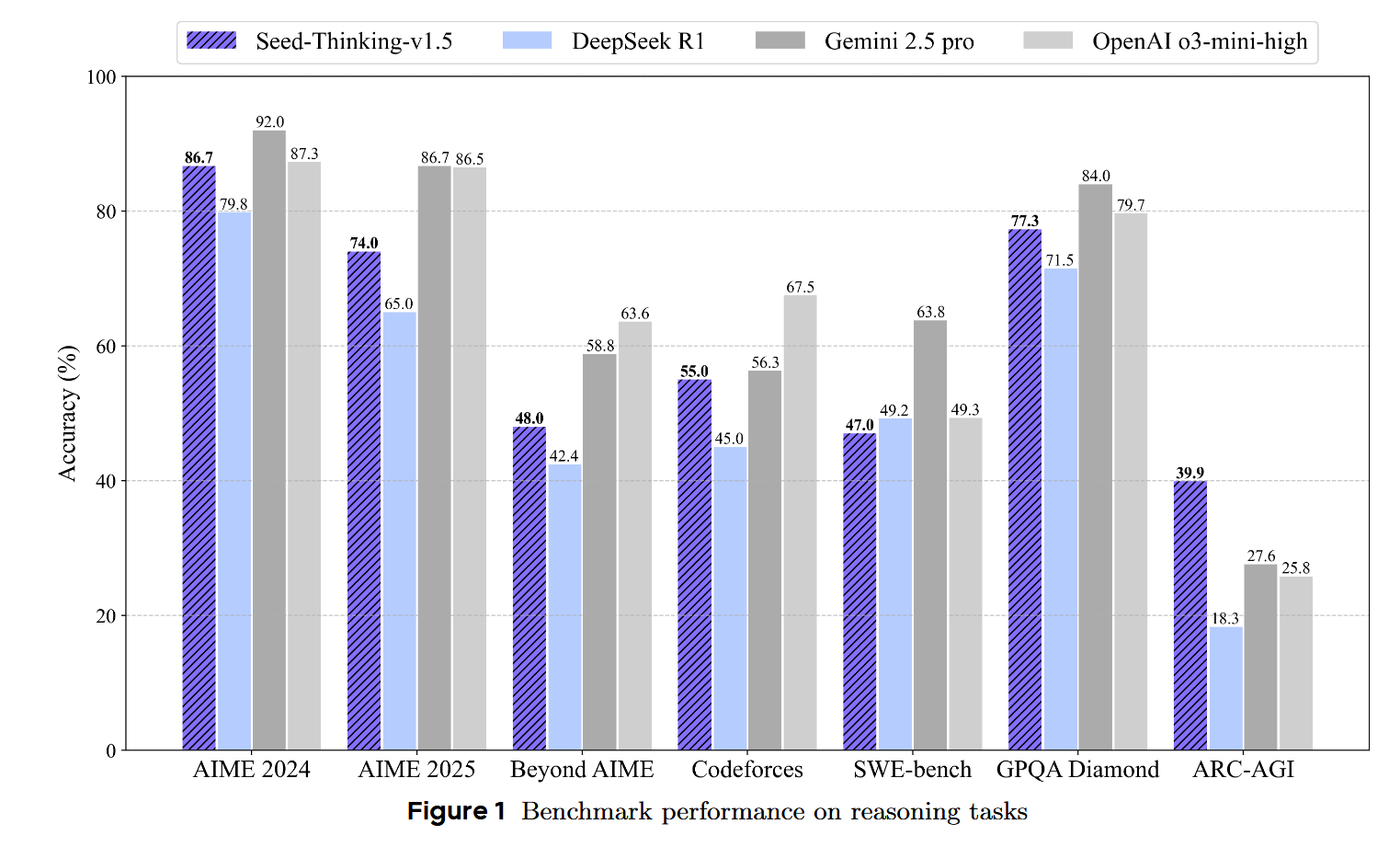
Seed-Thinking-v1.5 https://github.com/ByteDance-Seed/Seed-Thinking-v1.5 Seed-Thinking-v1.5 是 ByteDance Seed 团队开发的一个先进推理模型,采用 Mixture-of-Experts (MoE) 架构,具有 200B 总参数和 20B 激活参数。该模型的核心创新在于其"思考后回答"的机制,在数学、编程、科学推理等任务上取得了卓越的性能。相比DeepSeek R1 ,在很多数据指标上都取得了一定程度的进步。 数据 训练数据分为两大类: 可验证问题 (有明确答案)和 不可验证问题 (无明确答案)。模型的推理能力主要来自第一部分,并能泛化到第二部分。 可验证问题数据 可验证数据主要包含 STEM数据, 编程数据,以及逻辑推理数据 STEM 数据 数据组成:包含数十万道高质量竞赛级别问题, 涵盖数学、物理、化学,其中数学占比超过 80%; 数据清洗:初步删除问题陈述不完整、符号不一致或要求不明确的问题; 进一步过滤过于简单的数据以及有可能答案是错误的数据...
Large Model
2026-04-15
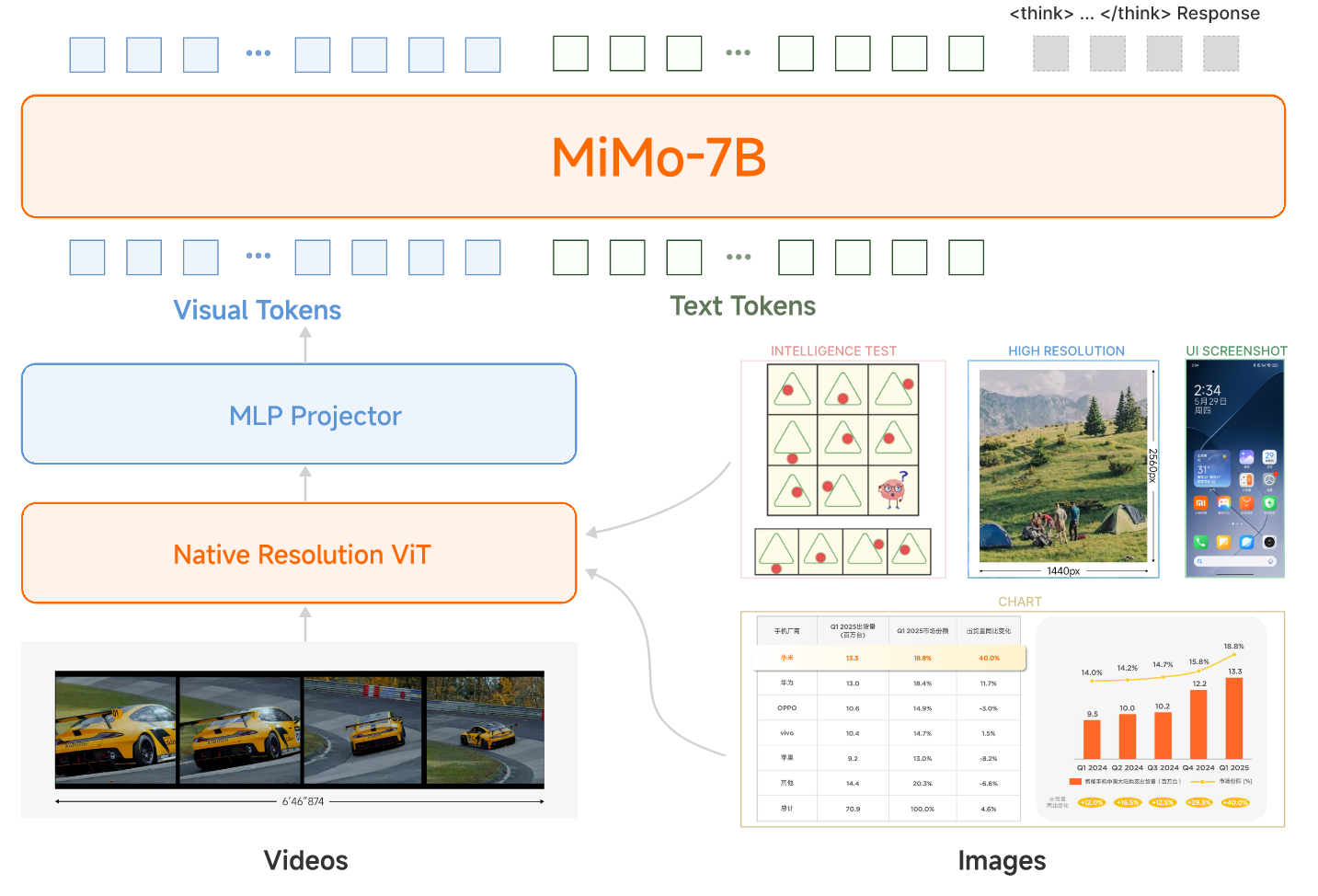
概述 小米团队近日发布了MIMO-VL-7B-SFT和MIMO-VL-7B-RL,这是两个强大的视觉语言模型,MIMO-VL-7B-RL在40个评估任务中的35个上优于QWEN2.5-VL-7B,对于GUI Grounding任务,它在OSWorld-G上设置了一个新标准,甚至超过了UI-TARS等专业模型。模型通过四个阶段的预训练(2.4T Token)与Mixed On-policy 强化(MORL)整合了多样化的奖励信号。 在文章中,作者提到了两个重要的发现: 从Pre-Traing 训练阶段中加入高质量且覆盖广的推理数据对于强化模型性能至关重要。 Mixed On-policy 强化学习进一步增强了模型的性能,同时实现了稳定的同时改进仍然在性能方面具有挑战性。 Pre-Training 模型结构 整个模型还是采用了VIT-MLP-LLM的结构,具体来说,视觉模型采用了Qwen2.5-VL中的视觉encoder,LLM采用了自家的语言模型MiMo-7B-Base。 整个Pretraining采用了四个阶段的训练,每个阶段采用的数据,模型训练参数和模型参数如下面两表所示...
Large Model
2026-04-15
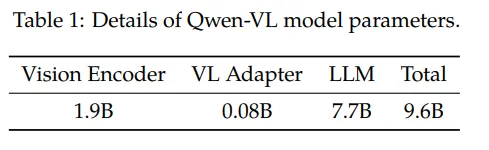
Qwen-VL系列 Qwen-VL 阿里巴巴的Qwen-VL是另一个比较经典的模型,十分值得作为案例介绍多模态大模型的训练要点。Qwen-VL使用Qwen-7B LLM作为语言模型基座,Openclip预训练的ViT-bigG作为视觉特征Encoder,随机初始化的单层Cross-Attention模块作为视觉和自然语言的的Adapter,总参数大小约9.6B。 如下图,Qwen-VL的训练过程分为三个阶段: Stage1 为预训练,目标是使用大量的图文Pair对数据对齐视觉模块和LLM的特征,这个阶段冻结LLM模块的参数; Stage2 为多任务预训练,使用更高质量的图文多任务数据(主要来源自开源VL任务,部分自建数据集),更高的图片像素输入,全参数训练; Stage3 为指令微调阶段,这个阶段冻结视觉Encoder模块,使用的数据主要来自大模型Self-Instruction方式自动生成,目标是提升模型的指令遵循和多轮对话能力。...
Large Model
2026-04-15

简介 bagel-ai.org BAGEL 模型原生支持统一的多模态理解和生成,是一个 decoder-only 的模型,BAGEL 在包含文本、图像、视频和网络数据的大量多模态数据上进行了预训练,包括数万亿 tokens。尽管有一些研究尝试扩展其统一模型,但它们 主要仍然依赖于标准图像生成和理解任务中的图像-文本配对数据 进行训练。 然而,最近的研究发现,学术模型与 GPT-4o 和 Gemini 2.0 等 专有系统在统一多模态理解和生成方面存在显著差距 ,而这些专有系统的底层技术并未公开。作者认为,弥合这一差距的关键在于 使用精心构建的多模态交错数据进行规模化训练 。这种多模态交错数据 整合了文本、图像、视频和网络来源 。通过使用这种多样化的多模态交错数据进行扩展时,模型展现出 复杂的、新兴的多模态推理能力 。这种规模化不仅增强了核心的多模态理解和生成能力,还促进了 复杂的组合能力 ,例如自由形式的视觉操作和需要长上下文推理的多模态生成。 论文主要贡献: 数据策略创新,融合多源数据。包含: 架构设计理念,采用 Mixture-of-Transformer-Experts...