背景 RLHF 通常包括三个阶段: 有监督微调(SFT) RLHF首先通过在高质量数据上进行监督学习来微调预训练的语言模型,得到模型 \(\pi_{SFT}\) 。 奖励建模阶段 (Reward Model) 在第二阶段,SFT模型根据提示 \(x\) 生成答案对 \((y_1, y_2) \sim \pi_{SFT}(y|x)\) 。这些答案对呈现给人类标注者,他们表达对一个答案的偏好,表示为 \(y_w \succ y_l|x\) ,其中 \(y_w\) 和 \(y_l\) 分别表示在 \((y_1, y_2)\) 中更受偏好和不受偏好的答案。 这些偏好被假定由某个潜在的奖励模型 \(r^*(y, x)\) 生成,我们无法直接访问该模型。一种流行的建模偏好的方法是Bradley-Terry(BT)模型,该模型规定人类偏好分布 \(p^*\) 可以写为: \[p^*(y_1 \succ y_2|x) = \frac{\exp(r^*(x, y_1))}{\exp(r^*(x, y_1)) + \exp(r^*(x, y_2))}
\] 假设我们有一个从 \(p^*\)...
Large Model
2026-04-15

简介 24年12月,研究团队开发了 DeepSeek-V3,这是一个基于 MoE 架构的大模型,总参数量达到 671B,其中每个 token 会激活 37B 个参数。 基于提升性能和降低成本的双重目标,在架构设计方面,DeepSeek-V3 采用了 MLA 来确保推理效率,并使用 DeepSeekMoE 来实现经济高效的训练。这两种架构在 DeepSeek-V2 中已经得到验证,证实了它们能够在保持模型性能的同时实现高效的训练和推理。 除了延续这些基础架构外,研究团队还引入了两项创新策略来进一步提升模型性能。 首先,DeepSeek-V3 首创了 无辅助损失的负载均衡 策略(auxiliary-loss-free strategy for load balancing),有效降低了负载均衡对模型性能的负面影响。另外,DeepSeek-V3 采用了 多 token 预测训练目标, 这种方法在评估基准测试中展现出了显著的性能提升。 为了提高训练效率,该研究采用了 FP8 混合精度训练技术...
Large Model
2026-04-15

简介 后训练(post-training)已成为完整训练流程中的重要组成部分。相比于预训练,后训练需要的计算资源相对较少,但能够: 提高推理任务的准确性 使模型与社会价值观保持一致 适应用户偏好 OpenAI 的 o1 系列模型首次引入了通过增加思维链(Chain-of-Thought)推理过程长度来实现推理时间,扩展这种方法在数学、编程和科学推理等各种推理任务上取得了显著改进 研究界已探索多种方法来提高模型的推理能力:比如 基于过程的奖励模型 (Process-based Reward Models) 强化学习 (Reinforcement Learning), 代表工作:InstructGPT, 以及 搜索算法( 蒙特卡洛树搜索(Monte Carlo Tree Search)、束搜索(Beam Search))。然而,这些方法尚未达到与 OpenAI o1 系列模型相当的通用推理性能。 DeepSeek-R1-Zero 本文首先探索使用纯强化学习(RL)来提高语言模型的推理能力,重点关注: 探索 LLM 在没有任何监督数据的情况下,通过纯 RL 过程的自我进化来发展推理能力...
Reinforcement Learning
2026-04-15

基础概念 Grid-Word Example 环境描述 :网格世界是一个直观的二维环境,包含: 白色格子 :可通行区域。 橙色格子 :禁止进入的区域(禁区)。 目标格子 :代理需要到达的目标位置。 任务目标 : 找到一条“好的”策略,使代理从任意初始位置到达目标格子。 策略应避免进入禁区、碰撞边界或走不必要的弯路。 什么是强化学习:依据策略执行动作-感知状态-得到奖励 所谓强化学习(Reinforcement Learning,简称RL),是指基于智能体在复杂、不确定的环境中最大化它能获得的奖励,从而达到自主决策的目的。 a computational approach to learning whereby an agent tries to maximize the total amount of reward it receives while interacting with a complex and uncertain environment 经典的强化学习模型可以总结为下图的形式(你可以理解为任何强化学习都包含这几个基本部分:智能体、行为、环境、状态、奖励):...
Large Model
2026-04-15

https://www.deepseek.com/ DeepSeek LLM 代码地址: https://github.com/deepseek-ai/DeepSeek-LLM 背景 量化巨头幻方探索AGI(通用人工智能)新组织“深度求索”在成立半年后,发布的第一代大模型,免费商用,完全开源。作为一家隐形的AI巨头,幻方拥有1万枚英伟达A100芯片,有手撸的HAI-LLM训练框架HAI-LLM:高效且轻量的大模型训练工具。 概述 DeepSeek LLMs,这是一系列在2万亿标记的英语和中文大型数据集上从头开始训练的开源模型 在本文中,深入解释了超参数选择、Scaling Laws以及做过的各种微调尝试。校准了先前工作中的Scaling Laws,并提出了新的最优模型/数据扩展-缩放分配策略。此外,还提出了一种方法,使用给定的计算预算来预测近似的batch-size和learning-rate。进一步得出结论,Scaling Laws与数据质量有关,这可能是不同工作中不同扩展行为的原因。在Scaling Laws的指导下,使用最佳超参数进行预训练,并进行全面评估。...
Large Model
2026-04-15

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
Large Model
2026-04-15
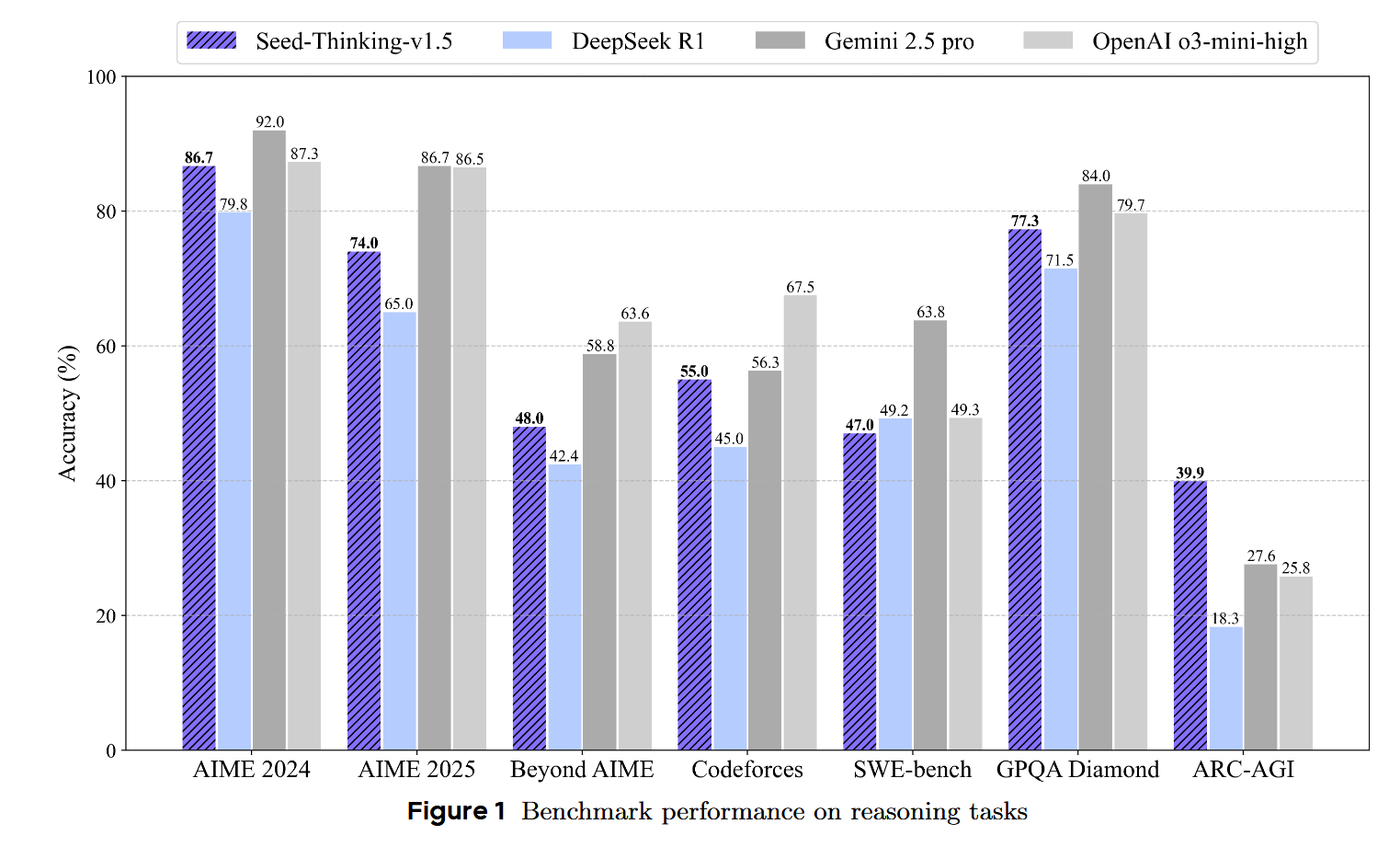
Seed-Thinking-v1.5 https://github.com/ByteDance-Seed/Seed-Thinking-v1.5 Seed-Thinking-v1.5 是 ByteDance Seed 团队开发的一个先进推理模型,采用 Mixture-of-Experts (MoE) 架构,具有 200B 总参数和 20B 激活参数。该模型的核心创新在于其"思考后回答"的机制,在数学、编程、科学推理等任务上取得了卓越的性能。相比DeepSeek R1 ,在很多数据指标上都取得了一定程度的进步。 数据 训练数据分为两大类: 可验证问题 (有明确答案)和 不可验证问题 (无明确答案)。模型的推理能力主要来自第一部分,并能泛化到第二部分。 可验证问题数据 可验证数据主要包含 STEM数据, 编程数据,以及逻辑推理数据 STEM 数据 数据组成:包含数十万道高质量竞赛级别问题, 涵盖数学、物理、化学,其中数学占比超过 80%; 数据清洗:初步删除问题陈述不完整、符号不一致或要求不明确的问题; 进一步过滤过于简单的数据以及有可能答案是错误的数据...
Large Model
2026-04-15

引言 Structured Generation with LLM,是指 让LLM按照预先定义的schema,输出符合schema的结构化结果 。 常见的应用场景有: 数据处理 。主要功能为a -> b,即从源文本中 抽取/生成 符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等; Agent 。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参。 将 LLM 限制为始终生成符合特定模式的、有效的 JSON 或 YAML,是许多应用的关键功能。 Kor Kor ,一个 基于prompt的技术方案 ;Kor比较适合 数据处理 场景,且原理简单、易于理解,适合作为入门, 并且Kor适用于那些不支持function calling的比较旧的模型。 使用Kor进行structured generation的流程如下: 定义schema,包括结构、注释还有例子; Kor用特定的 prompt template ,将用户提供的schema和待处理的raw text,组装成prompt; 将prompt发送给LLM,借助其通用的In...
Large Model
2026-04-15
DeepSeek-V2 的发布引起了大家的热烈讨论。首先,最让人哗然的是1块钱100万token的价格,普遍比现有的各种竞品API便宜了两个数量级,以至于有人调侃“这个价格哪怕它输出乱码,我也会认为这个乱码是一种艺术”;其次,从模型的技术报告看,如此便宜的价格背后的关键技术之一是它新提出的MLA( M ulti-head L atent A ttention),这是对GQA的改进,据说能比GQA更省更好,也引起了读者的广泛关注。 接下来,本文将跟大家一起梳理一下从MHA、MQA、GQA到MLA的演变历程,并着重介绍一下MLA的设计思路。 MHA MHA( M ulti- H ead A ttention),也就是多头注意力,是开山之作 《Attention is all you need》 所提出的一种Attention形式,可以说它是当前主流LLM的基础工作。在数学上,多头注意力MHA等价于多个独立的单头注意力的拼接,假设输入的(行)向量序列为 \(\boldsymbol{x}_1,\boldsymbol{x}_2,\cdots,\boldsymbol{x}_l\) ,其中...
最优策略(Optimal Policy ) 之前在 贝尔曼方程(Bellman Equation) 中说过, 状态值可以用来评估一个策略是好是坏 ,这里给出正式的概念: \[v_{\pi_1}(s) \geq v_{\pi_2}(s) \quad \text { for all } s \in \mathcal{S}\] 那么此时 \(\pi_1\) 比 \(\pi_2\) ”更好“ 最优状态值(Optimal State Value) : 对于任意状态 \(s\) ,最优状态值 \(v^*(s)\) 是所有可能策略中状态值的最大值: \[v^*(s) = \max_{\pi} v_{\pi}(s)\] 其中 \(v_{\pi}(s)\) 是策略 \(\pi\) 下的状态值。 最优策略(Optimal Policy) : 如果一个策略的状态值在所有状态中均大于或等于其他策略的状态值,则该策略为最优策略: \[\pi^* = \arg\max_{\pi} v_{\pi}(s), \forall s \in S\] 即最优策略总是选择使得状态值最大的动作。 性质 : 存在性...