Computer Vision
2026-04-15

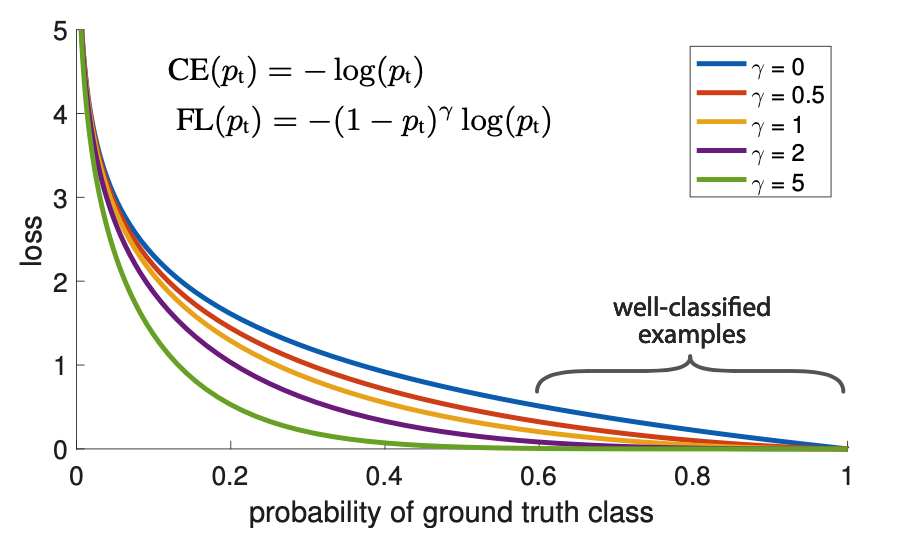
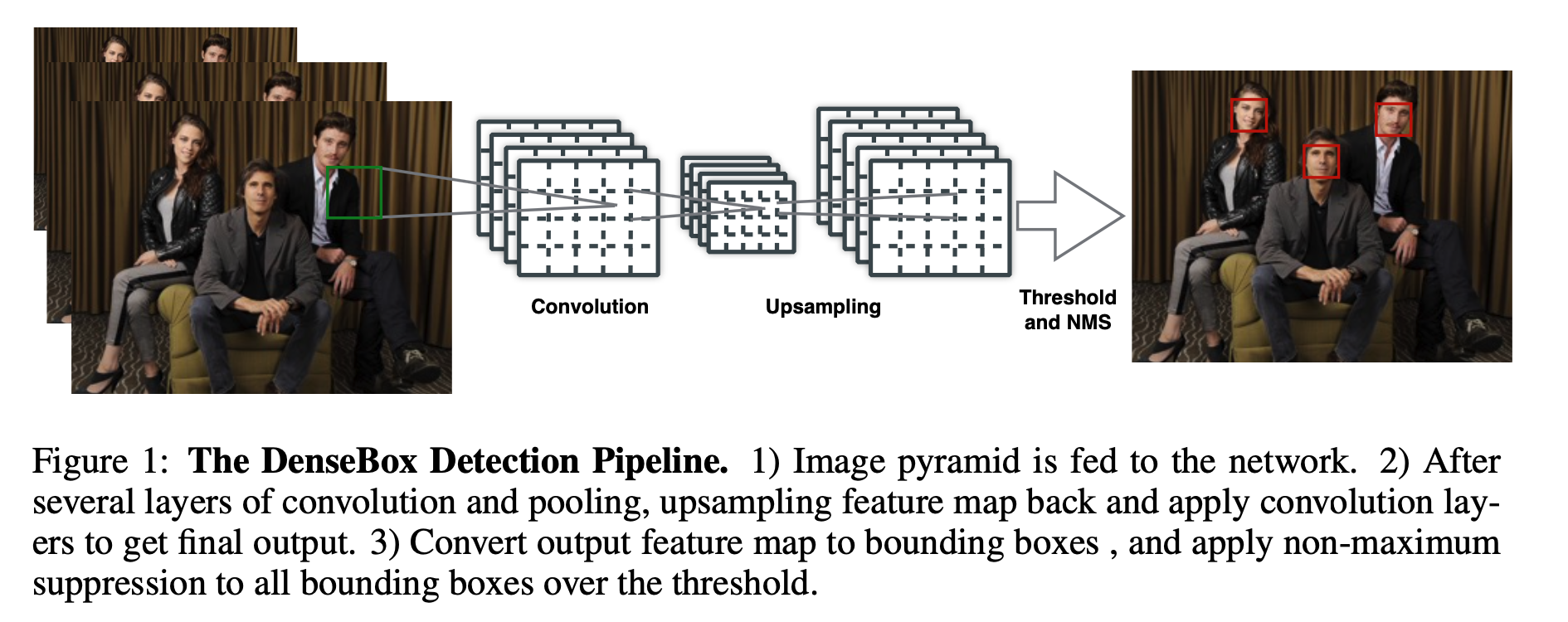
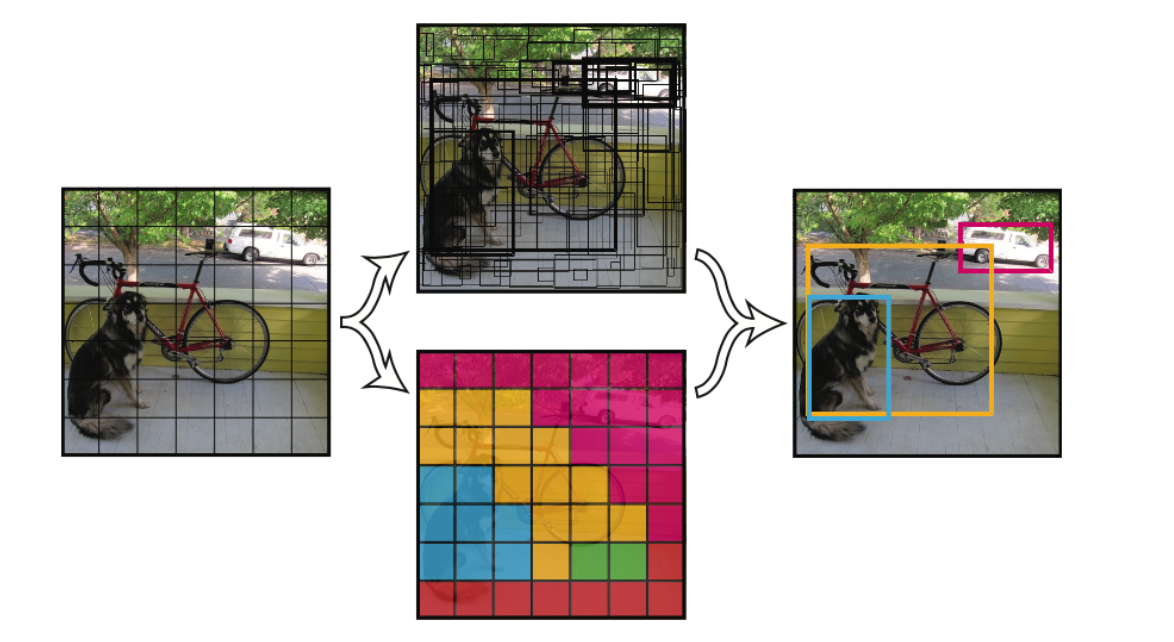
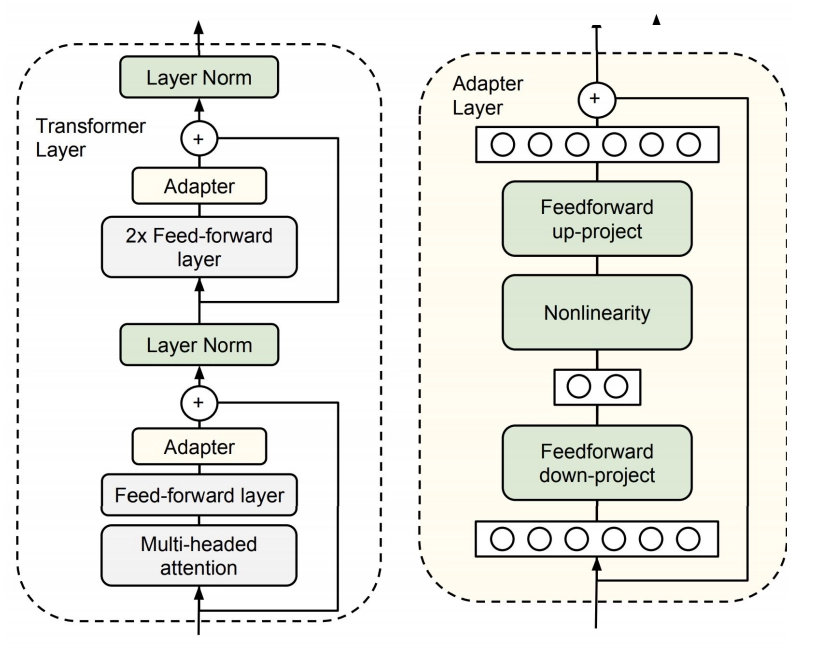
原理分析 网络架构 本文的任务是Object detection,用到的工具是Transformers,特点是End-to-end。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。 文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。 在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他的baseline。DETR第一个使用End to End的方式解决检测问题,解决的方法是把检测问题视作是一个set prediction problem,如下图所示。...