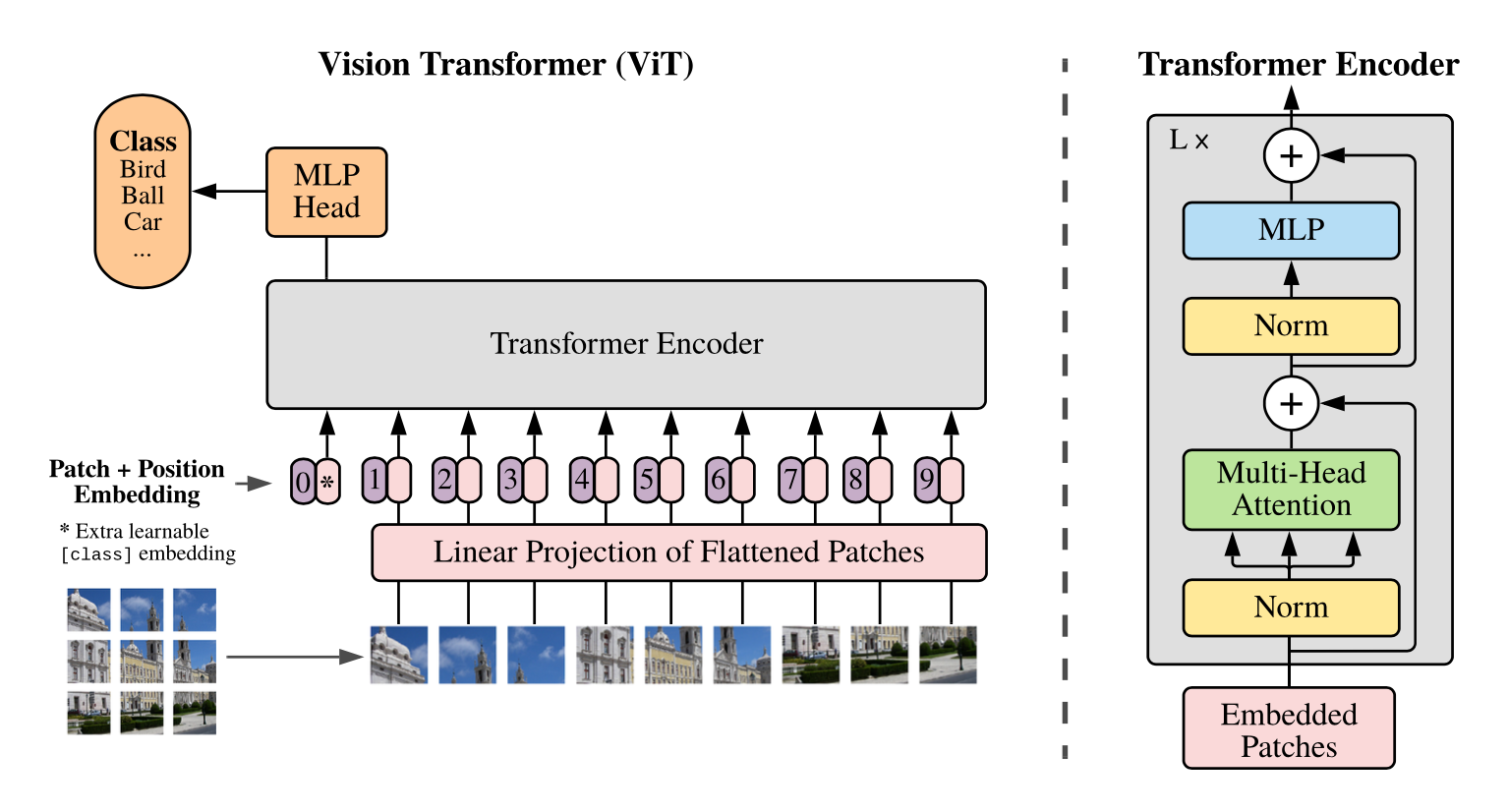
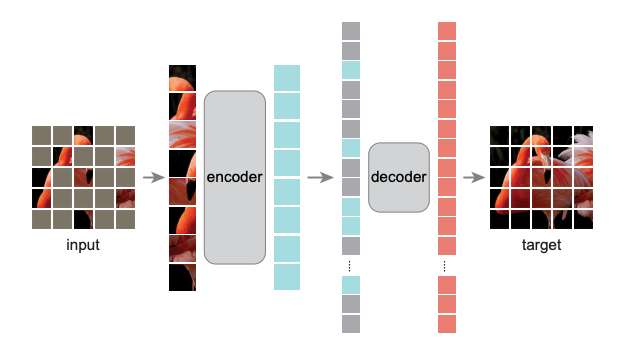
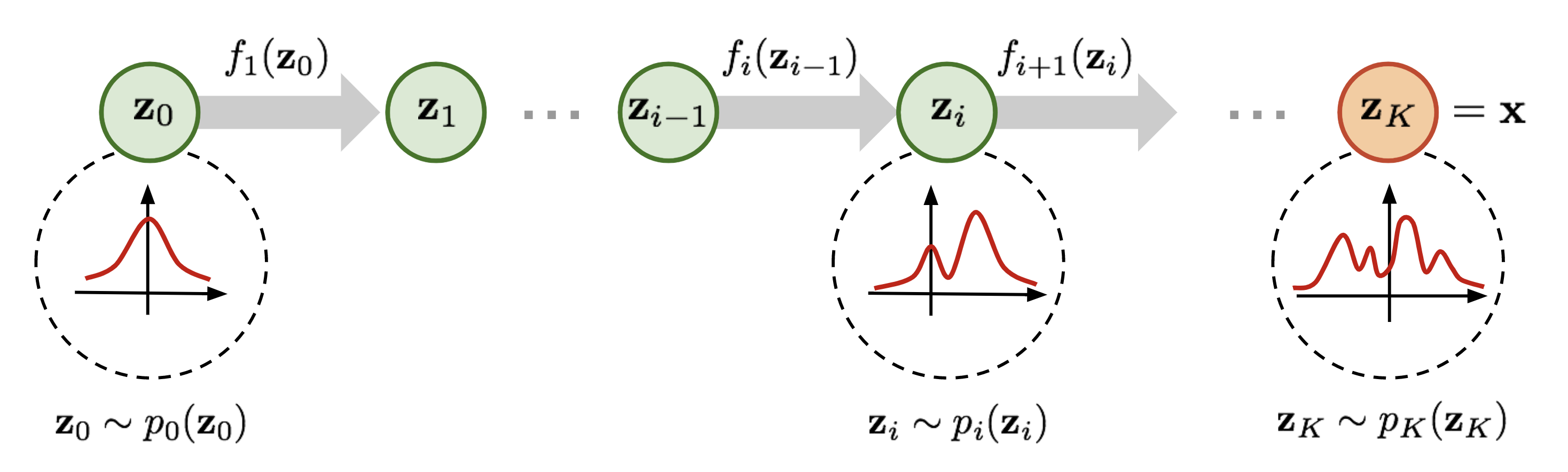
Computer Vision
2026-04-15
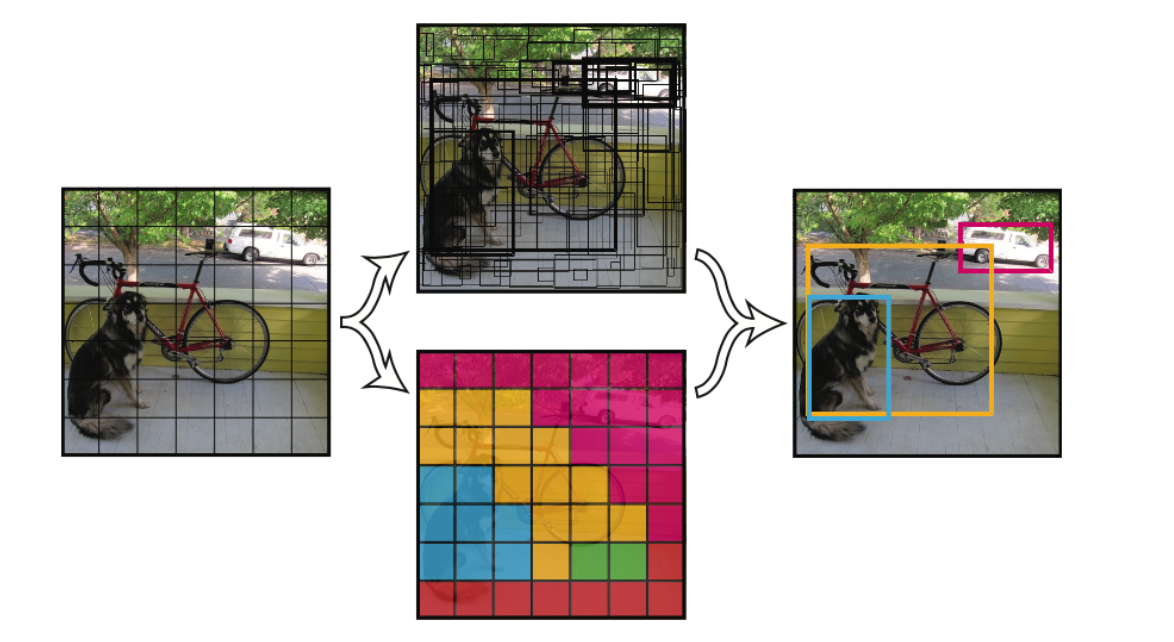
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。 Our system divides the input image into a S × S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object. faster RCNN中也直接用整张图作为输入,但是faster-RCNN整体还是采用了RCNN那种 proposal+classifier的思想,只不过是将提取proposal的步骤放在CNN中实现了,而YOLO则采用直接回归的思路。 YOLO v1 将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。 每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。...