Large Model
2026-04-15
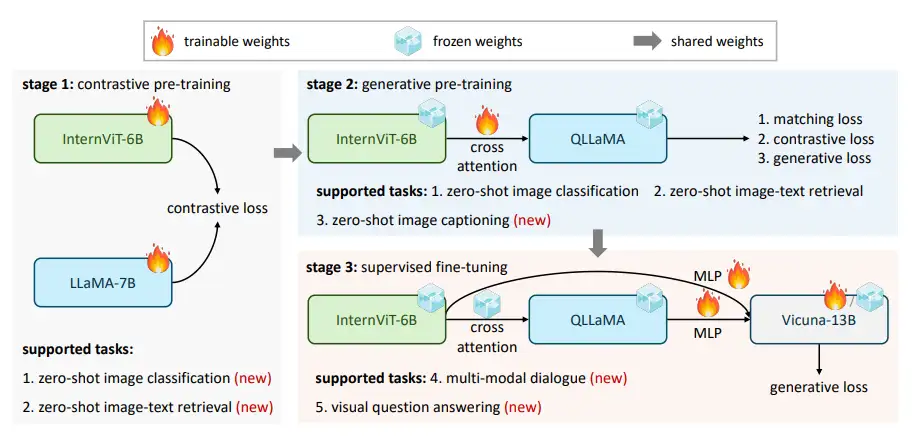
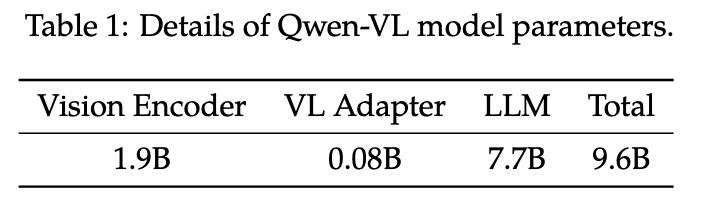
Qwen-VL系列 Qwen-VL 阿里巴巴的Qwen-VL是另一个比较经典的模型,十分值得作为案例介绍多模态大模型的训练要点。Qwen-VL使用Qwen-7B LLM作为语言模型基座,Openclip预训练的ViT-bigG作为视觉特征Encoder,随机初始化的单层Cross-Attention模块作为视觉和自然语言的的Adapter,总参数大小约9.6B。 如下图,Qwen-VL的训练过程分为三个阶段: Stage1 为预训练,目标是使用大量的图文Pair对数据对齐视觉模块和LLM的特征,这个阶段冻结LLM模块的参数; Stage2 为多任务预训练,使用更高质量的图文多任务数据(主要来源自开源VL任务,部分自建数据集),更高的图片像素输入,全参数训练; Stage3 为指令微调阶段,这个阶段冻结视觉Encoder模块,使用的数据主要来自大模型Self-Instruction方式自动生成,目标是提升模型的指令遵循和多轮对话能力。...