补充知识 表示学习 (Representation Learning): 学习数据的表征,以便在构建分类器或其他预测器时更容易提取有用的信息 ,无监督学习也属于表示学习。 互信息 (Mutual Information):表示两个变量 \(X\) 和 \(Y\) 之间的关系,定义为: \[I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x|y)}{p(x)}\] 对比损失(contrastive loss) :计算成对样本的匹配程度,主要用于降维中。计算公式为: \[L=\frac{1}{2N}\sum_{n-1}^N[yd^2+(1-y)max(margin-d, 0)^2]\] 其中, \(d=\sqrt{(a_n-b_n)^2}\) 为两个样本的欧式距离, \(y=\{0,1\}\) 代表两个样本的匹配程度, \(margin\) 代表设定的阈值。这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。当 \( y=1\) (即样本相似)时,损失函数只剩下 \(∑d^2\)...
Self-Supervised
2026-04-15
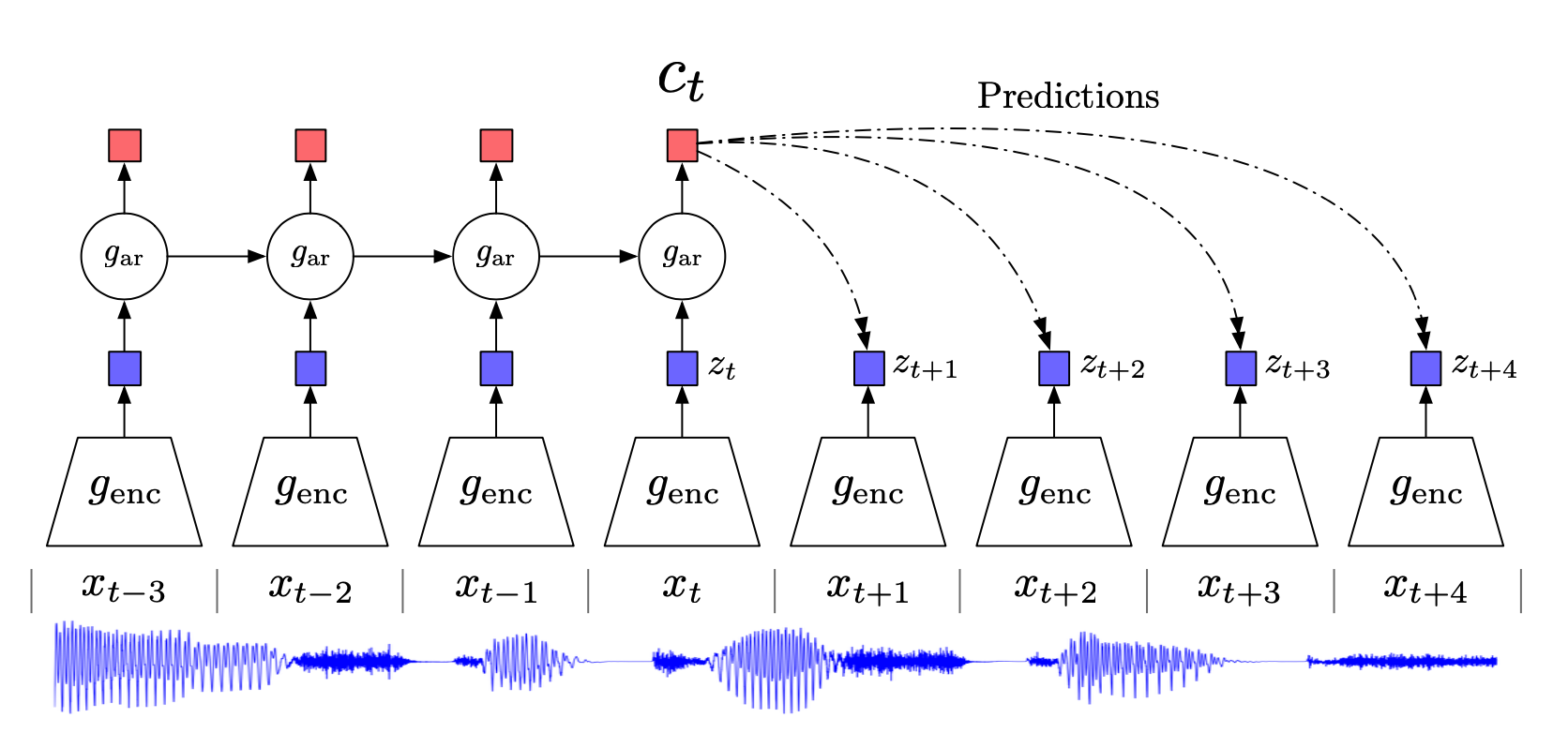
相关内容 自监督学习 (Self-supervised):属于无监督学习,其核心是自动为数据打标签(伪标签或其他角度的可信标签,包括图像的旋转、分块等等),通过让网络按照既定的规则,对数据打出正确的标签来更好地进行特征表示,从而应用于各种下游任务。 互信息 (Mutual Information):表示两个变量 \(X\) 和 \(Y\) 之间的关系,定义为: \[I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x|y)}{p(x)}\] 噪声对抗估计 (Noise Contrastive Estimation, NCE):在NLP任务中一种降低计算复杂度的方法,将语言模型估计问题简化为一个二分类问题。 Introduction 无监督学习一个重要的问题就是学习有用的 representation,本文的目的就是训练一个 representation learning 函数(即编码器encoder) ,其通过最大编码器输入和输出之间的互信息(MI)来学习对下游任务有用的 representation,而互信息可以通过 MINE...
Self-Supervised
2026-04-15
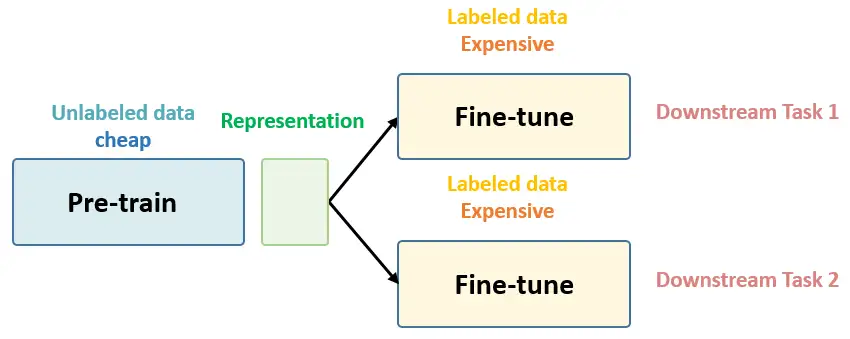
总结下 Self-Supervised Learning 的方法,用 4 个英文单词概括一下就是: Unsupervised Pre-train, Supervised Fine-tune. 在预训练阶段我们使用 无标签的数据集 (unlabeled data) ,因为有标签的数据集 很贵 ,打标签得要多少人工劳力去标注,那成本是相当高的,所以这玩意太贵。相反,无标签的数据集网上随便到处爬,它 便宜 。在训练模型参数的时候,我们不追求把这个参数用带标签数据从 初始化的一张白纸 给一步训练到位,原因就是数据集太贵。于是 Self-Supervised Learning 就想先把参数从 一张白纸 训练到 初步成型 ,再从 初步成型 训练到 完全成型 。注意这是2个阶段。这个 训练到初步成型的东西 ,我们把它叫做 Visual Representation 。预训练模型的时候,就是模型参数从 一张白纸 到 初步成型 的这个过程,还是用无标签数据集。等我把模型参数训练个八九不离十,这时候再根据你 下游任务 (Downstream Tasks) 的不同去用带标签的数据集把参数训练到 完全成型...
Self-Supervised
2026-04-15
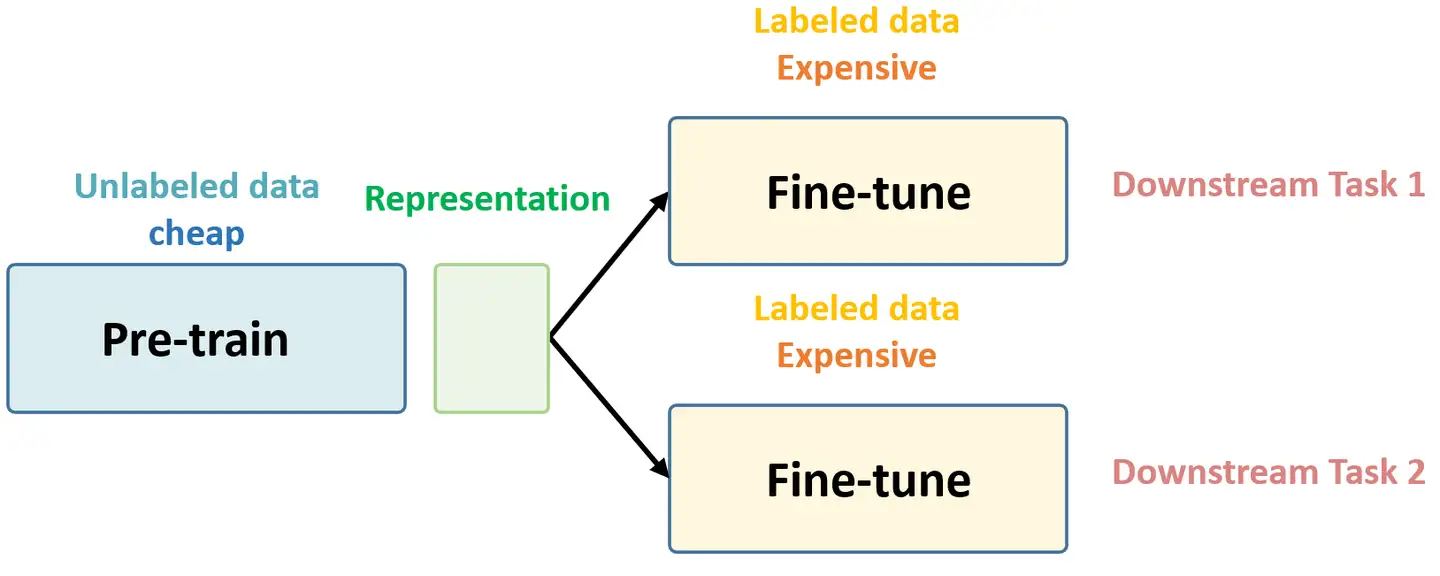
Self-Supervised Learning ,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种 通用的特征表达 用于 下游任务 (Downstream Tasks) 。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。 总结下 Self-Supervised Learning 的方法,用 4 个英文单词概括一下就是: Unsupervised Pre-train, Supervised Fine-tune. 这段话先放在这里,可能你现在还不一定完全理解,后面还会再次提到它。 在预训练阶段我们使用 无标签的数据集 (unlabeled data) ,因为有标签的数据集 很贵...
Self-Supervised
2026-04-15

如果把 近几年对比学习在视觉领域有代表性的工作做一下总结,那么对比学习的发展历程大概可以分为四个阶段: 百花齐放 这个阶段代表性工作有InstDisc(instance discrimination,)、CPC、CMC等。在这个阶段中,方法、模型、目标函数、代理任务都还没有统一,所以说是一个百花齐放的时代 CV双雄 代表作有MoCo v1、SimCLR v1、MoCo v2、SimCLR v2;CPC、CMC的延伸工作、SwAV等。这个阶段发展非常迅速,有的工作间隔甚至不到一个月,ImageNet上的成绩基本上每个月都在被刷新。 不用负样本 BYOL及其改进工作、SimSiam(CNN在对比学习中的总结性工作) transformer MoCo v3、DINO。这个阶段,无论是对比学习还是最新的掩码学习,都是用Vision Transformer做的。 第一阶段:百花齐放(2018-2019Mid) InstDisc(instance discrimination) 这篇文章提出了个体判别任务(代理任务)以及 memory bank ,非常经典,后人给它的方法起名为InstDisc。...
Computer Vision
2026-04-15
mAP定义及相关概念 mAP: mean Average Precision, 即各类别AP的平均值 AP: PR曲线下面积,后文会详细讲解 PR曲线: Precision-Recall曲线 Precision: TP / (TP + FP) Recall: TP / (TP + FN) TP: IoU>0.5的检测框数量(同一Ground Truth只计算一次) FP: IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量 FN: 没有检测到的GT的数量 mAP的具体计算 由前面定义,我们可以知道,要计算mAP必须先绘出各类别PR曲线,计算出AP。而如何采样PR曲线,VOC采用过两种不同方法。 在VOC2010以前,只需要选取当Recall >= 0, 0.1, 0.2, ..., 1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值。 在VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值。 mAP计算示例 假设,对于...
Deep Learning
2026-04-15

Random erasing data augmentation 论文名称:Random erasing data augmentation 论文地址: https://arxiv.org/pdf/1708.04896v2.pdf 随机擦除增强,非常容易理解。作者提出的目的主要是模拟遮挡,从而提高模型泛化能力,这种操作其实非常make sense,因为我把物体遮挡一部分后依然能够分类正确,那么肯定会迫使网络利用局部未遮挡的数据进行识别,加大了训练难度,一定程度会提高泛化能力。其也可以被视为add noise的一种,并且与随机裁剪、随机水平翻转具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。具体操作就是:随机选择一个区域,然后采用随机值进行覆盖,模拟遮挡场景。 在细节上,可以通过参数控制擦除的面积比例和宽高比,如果随机到指定数目还无法满足设置条件,则强制返回。 一些可视化效果如下: Cutout 论文名称:Improved Regularization of Convolutional Neural Networks with Cutout...
Large Model
2026-04-15

Stanford Alpaca 结合英文语料通过Self Instruct方式微调LLaMA 7B Stanford Alpaca简介 2023年3月中旬,斯坦福的Rohan Taori等人发布Alpaca(中文名:羊驼):号称只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型(即LLaMA 7B), 具体做法是通过52k指令数据,然后在8个80GB A100上训练3个小时,使得Alpaca版的LLaMA 7B在单纯对话上的性能比肩GPT-3.5(text-davinci-003) ,这便是指令调优LLaMA的意义所在 论文《Alpaca: A Strong Open-Source Instruction-Following Model》 GitHub地址: https://github.com/tatsu-lab/stanford_alpaca 数据地址 (即斯坦福团队微调LLaMA 7B所用的52K英文指令数据): raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json...
Large Model
2026-04-15
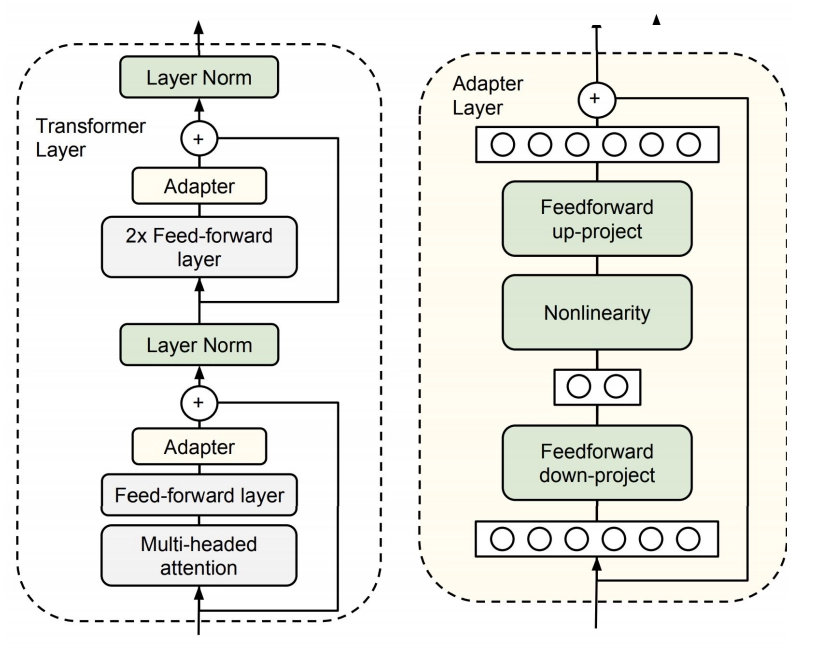
Adapter tuning Adapter Tuning试图在Transformer Layer的Self-Attetion+FFN之后插入一个先降维再升维的MLP(以及一层残差和LayerNormalization)来学习模型微调的知识。 在预训练模型每一层(或某些层)中添加Adapter模块(如上图左侧结构所示),微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。每个Adapter模块由两个前馈子层组成,第一个前馈子层将Transformer块的输出作为输入,将原始输入维度 \(d\) 投影到 \(m\) ,通过控制 \(m\) 的大小来限制Adapter模块的参数量,通常情况下 \(m\ll d\) 。在输出阶段,通过第二个前馈子层还原输入维度,将 \(m\) 重新投影到 \(d\)...
Large Model
2026-04-15
LLaMA 论文名称 :LLaMA: Open and Efficient Foundation Language Models 论文地址: https://arxiv.org/pdf/2302.13971.pdf 代码链接: https://github.com/facebookresearch/llama 模型参数量级的积累,或者训练数据的增加,哪个对性能提升帮助更大? 以 GPT-3 为代表的大语言模型 (Large language models, LLMs) 在海量文本集合上训练,展示出了惊人的涌现能力以及零样本迁移和少样本学习能力。GPT-3 把模型的量级缩放到了 175B,也使得后面的研究工作继续去放大语言模型的量级。大家好像有一个共识,就是: 模型参数量级的增加就会带来同样的性能提升。 但是事实确实如此吗? 最近的 "Training Compute-Optimal Large Language Models" 这篇论文提出一种 缩放定律 (Scaling Law): 训练大语言模型时,在计算成本达到最优情况下,模型大小和训练数据 (token)...
Deep Learning
2026-04-15
一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。 还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到 \(\text{argmax}\) 等操作),所以没法直接用。 这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀鸡”的方案; 另外一种是试图给正确率找一个光滑可导的近似公式 。本文就来探讨一下常见的不可导函数的光滑近似,有时候我们称之为“光滑化”,有时候我们也称之为“软化”。 max 后面谈到的大部分内容,基础点就是max操作的光滑近似,我们有:...
Deep Learning
2026-04-15

文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。 基本概念 重参数(Reparameterization) 实际上是处理如下期望形式的目标函数的一种技巧: \[L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\tag{1}\] 这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现( \(f(z)\) 对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于 \(z\) 的连续性,它对应不同的形式: \[\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\tag{2}\] 当然,离散情况下我们更喜欢将记号 \(z\) 换成 \(y\) 或者 \(c\) 。 为了最小化...