
概括 这篇文章将卷积比较自然地拓展到点云的情形,思路很赞! 文章的主要创新点:“weight function”和“density function”,并能实现translation-invariance和permutation-invariance,可以实现层级化特征提取,而且能自然推广到其deconvolution的情形实现分割,在二维CIFAR-10图像分类任务中精度堪比CNN(表明能够充分近似卷积网络),达到了SOTA的性能。 缺点:每个kernel都需要由“kernel function”生成,而“kernel function”实质上是一个CNN网络,计算量比较大。 思想 察觉到:二维卷积中pixel的相对centroid位置与kernel vector的生成方式有关。 以二维卷积为例说明一下如何将卷积拓展到点云。这里只考虑使用一个kernel在一个location的一次卷积操作。 对于二维图像,我们可以将图像的pixels看作是一个点,那么图像就是整齐排列的点阵。每个point都有维度为 \(C_{in}\)...

Hough Voting 本文的标题是Deep Hough Voting,先来说一下Hough Voting。 用Hough变换检测直线大家想必都听过:对于一条直线,可以使用 \((r,θ)\) 两个参数进行描述,那么对于图像中的一点,过这个点的直线有很多条,可以生成一系列的 \((r,θ)\) ,在参数平面内就是一条曲线,也就是说,一个点对应着参数平面内的一个曲线。那如果有很多个点,则会在参数平面内生成很多曲线。那么,如果这些点是能构成一条直线的,那么这条直线的参数 \((r,θ)\) 就在每条曲线中都存在,所以看起来就像是多条曲线相交在 \((r,θ)\) 。可以用多条曲线投票的方式来看,其他点都是很少的票数,而 \((r,θ)\) 则票数很多,所以直线的参数就是 \((r,θ)\) 。 所以Hough变换的思想就是在于,在参数空间内进行投票,投票得数高的就是要得到的值。 文中提到的Hough Voting如下: A traditional Hough voting 2D detector comprises an offline and an online step....
3D Model
2026-04-15

三维空间中的旋转有很多种表示方式,欧拉角,旋转矩阵,旋转向量,四元数。由于在slam与机器人中会大量用到这方面的知识,所以在这里将此方面的知识总结一下,方便以后查阅。 欧拉角(Euler Angle) 欧拉角可以使用滑翔翼飞行器控制来理解,比如对于下面这张图,一般假设红色轴为z轴,则z轴表示空间的第三维,则去掉这一维度表示飞行器在一个二维平面上;蓝色轴为x轴,也是飞行器的朝向,因此绕此轴转动就像是飞行器在做翻滚动作,因此叫翻滚角(roll);绿色轴为y轴,绕这个轴转动其实就是飞机开始准备向上飞或者向下飞了,因此叫俯仰角(pitch);同理,绕红色轴也就是z轴转动代表飞机开始调整自身在二维平面上的朝向了,因此叫偏航角(yaw)。 在欧拉角的表示中,yaw、pitch、roll的顺序对旋转结果是有影响的。即 给定一组欧拉角角度值,比如yaw=45度,pitch=30度,roll=60度,按照yaw-pitch-roll的顺序旋转和按照yaw-roll-pitch的顺序旋转,最终刚体的朝向是不同的! 换言之,若刚体需要按照两种不同的旋转顺序旋转到相同的朝向,所需要的欧拉角角度值则是不同的!...
3D Model
2026-04-15
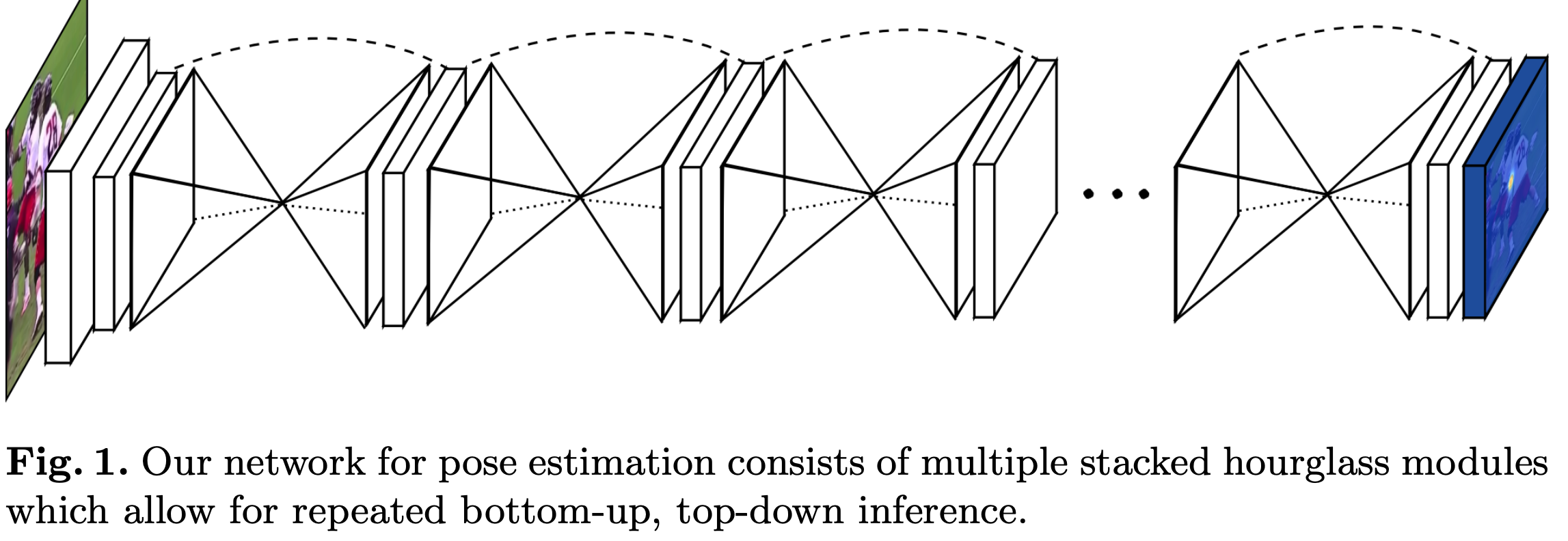
论文介绍了一种新的网络结构用于人体姿态检测,作者在论文中展现了不断重复bottom-up、top-down过程以及运用intermediate supervison(中间监督)对于网络性能的提升,下面来介绍Stacked Hourglass Networks. 简介 理解人类的姿态对于一些高级的任务比如行为识别来说特别重要,而且也是一些人机交互任务的基础。作者提出了一种新的网络结构Stacked Hourglass Networks来对人体的姿态进行识别,这个网络结构能够捕获并整合图像所有尺度的信息。之所以称这种网络为Stacked Hourglass Networks,主要是它长得很像堆叠起来的沙漏,如下图所示: 这种堆叠在一起的Hourglass模块结构是对称的,bottom-up过程将图片从高分辨率降到低分辨率,top-down过程将图片从低分辨率升到高分辨率,这种网络结构包含了许多pooling和upsampling的步骤,pooling可以将图片降到一个很低的分辨率,upsampling可以结合多个分辨率的特征。 下面介绍具体的网络结构。 Hourglass Module...
Generative Model
2026-04-15

1-Rectified Flow 可以认为是 flow matching的ot最优传输形式 Rectified Flow目的是将多对多无约束映射 转变成 一对一有约束映射。 ode会保证路径是“因果”的,也就是避免相交的情况 2-Rectified Flow或者叫Reflow 核心的实际上是加噪过程的样本交点数目降低,交点处模型无法精确学习向量场,交点数少了,模型在每个点预测都更准了,加噪过程是直线,所以能更少步数走到起点(但整体采样过程不是直线) 原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE 。 细想上述过程, 可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了 。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。 Rectified Flow 理论推导 微分方程...
3D Model
2026-04-15
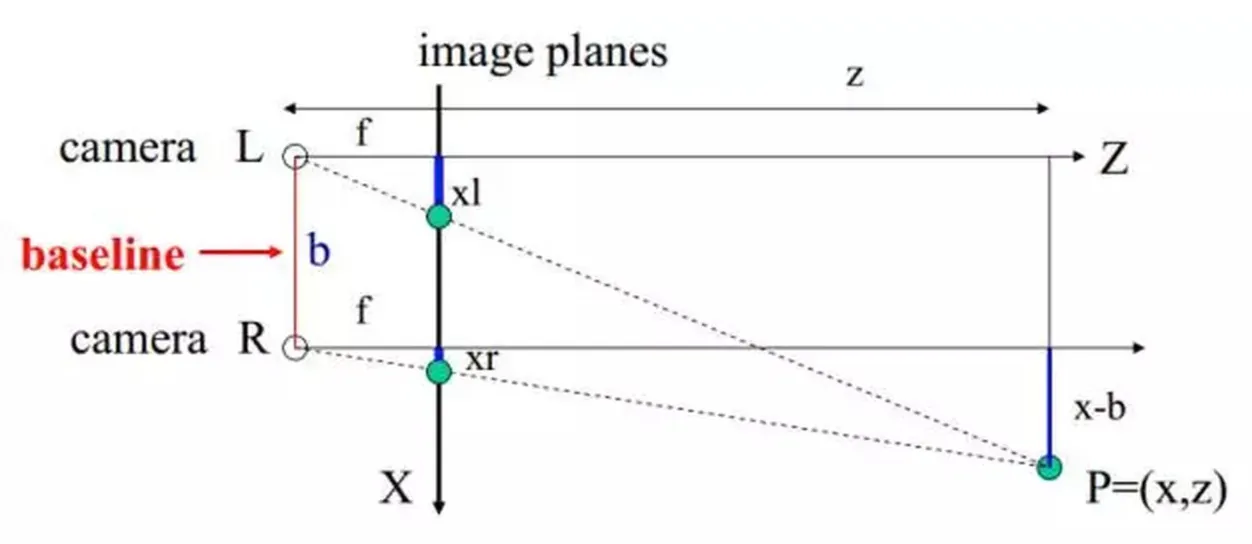
深度相机 “工欲善其事必先利其器‘’我们先从能够获取RGBD数据的相机开始谈起。首先我们来看一看其分类。 根据其工作原理主要分为三类: 1.双目方案 基于双目立体视觉的深度相机类似人类的双眼,和基于TOF、结构光原理的深度相机不同,它不对外主动投射光源,完全依靠拍摄的两张图片(彩色RGB或者灰度图)来计算深度,因此有时候也被称为被动双目深度相机。比较知名的产品有STEROLABS 推出的 ZED 2K Stereo Camera和Point Grey 公司推出的 BumbleBee。 双目立体视觉是基于视差原理,由多幅图像获取物体三维几何信息的方法。在机器视觉系统中, 双目视觉一般由双摄像机从不同角度同时获取周围景物的两幅数字图像,或有由单摄像机在不同时刻从不同角度获取周围景物的两幅数字图像 ,并基于视差原理即可恢复出物体三维几何信息,重建周围景物的三维形状与位置。 双目视觉有的时候我们也会把它称为体视,是人类利用双眼获取环境三维信息的主要途径。从目前来看,随着机器视觉理论的发展,双目立体视觉在机器视觉研究中发回来看了越来越重要的作用 为什么非得用双目相机才能得到深度?...
Search&Rec
2026-04-15
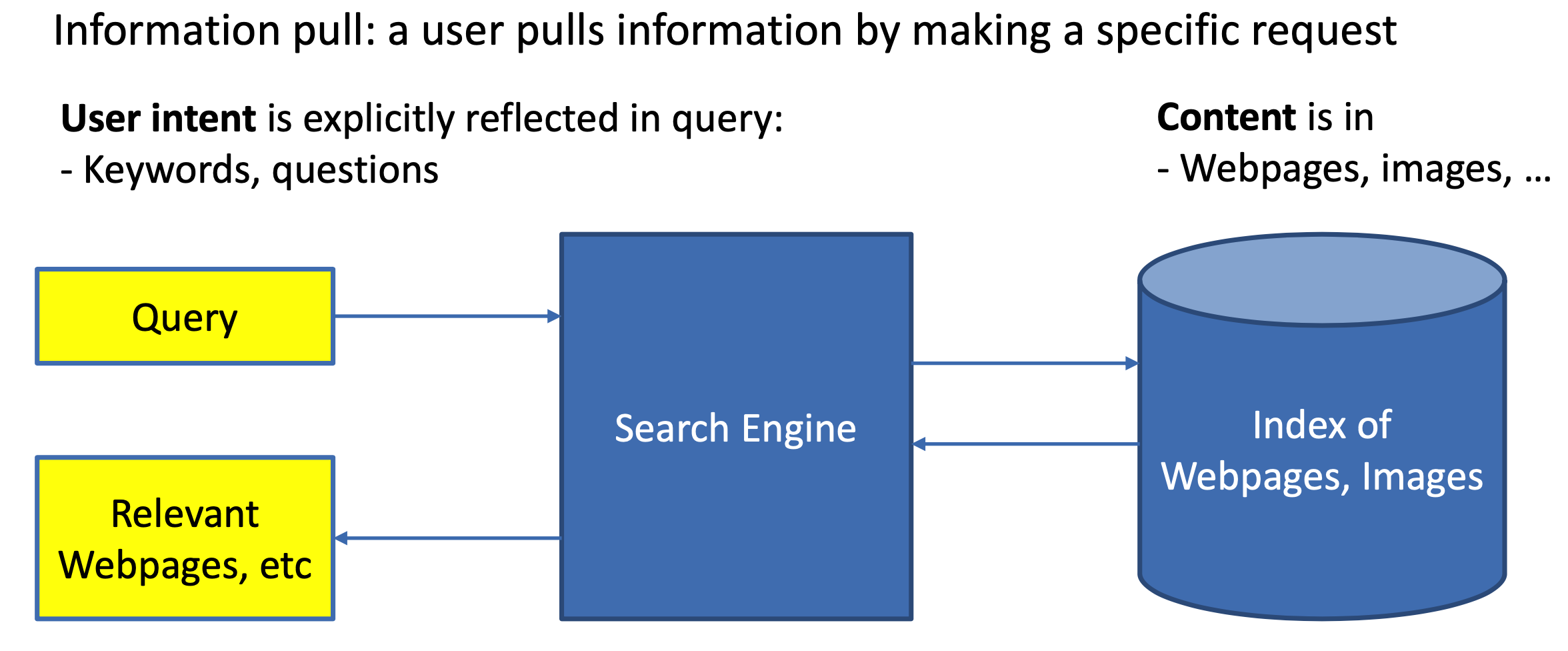
搜索引擎概述 推荐和搜索比较 推荐系统和搜索应该是机器学习乃至深度学习在工业界落地应用最多也最容易变现的场景。而无论是搜索还是推荐,本质其实都是匹配,搜索的本质是给定query,匹配doc;推荐的本质是给定user,推荐item。 对于搜索来说,搜索引擎的本质是对于用户给定query,搜索引擎通过query-doc的match匹配,返回用户最可能点击的文档的过程。从某种意义上来说,query代表的是一类用户,就是对于给定的query,搜索引擎要解决的就是query和doc的match,如图1.1所示。 图1.1 搜索引擎架构 对于推荐来说,推荐系统就是系统根据用户的属性(如性别、年龄、学历等),用户在系统里过去的行为(例如浏览、点击、搜索、收藏等),以及当前上下文环境(如网络、手机设备等),从而给用户推荐用户可能感兴趣的物品(如电商的商品、feeds推荐的新闻、应用商店推荐的app等),从这个过程来看,推荐系统要解决的就是user和item的match,如图1.2所示。 图1.2 推荐引擎架构 不同之处 意图不同...
Search&Rec
2026-04-15

讨论一下推荐系统三板斧: 数据、特征和模型 ,因为搜索的排序套路和推荐十分类似,除了多了query维度特征,对相关性有一定的要求,其他很大程度上思想一致。 这里先行引用一个比较形象的推荐系统优化流程: 明确业务目标 将业务目标转化为机器学习可优化目标 样本收集 特征工程 模型选择和训练 离线评测验证 在线AB验证 通过离线验证和在线AB的结果反馈到2,形成一个增强回路慢慢起飞。 而在一般情况下,各个环节的贡献占比:样本>>特征工程>模型。另外如果离线验证集85分,线上很多时候也会略低,各种原因也不胜枚举:特征延迟、特征不一致、甚至在样本落盘时的数据丢失等等。 本篇先行介绍上述过程特征工程的一般方法,包括特征设计、清洗、变换以及特征选择,并在最后讨论深度学习背景下的特征工程。 特征设计 特征工程的第一步是要找到对模型预测有用的特征,最常用的方式是基于经验 分维度梳理 ,如电商领域第一层可以按场景元素分成 User特征、Item特征、Seller特征、Query特征、上下文特征等...
Search&Rec
2026-04-15
CTR预测问题简介 点击率(Click Through Rate, CTR)预估是程序化广告里的一个最基本而又最重要的问题。比如在竞价广告里,排序的依据就是 \(𝑐𝑡𝑟×𝑏𝑖𝑑\) 。通过选择 \(𝑐𝑡𝑟×𝑏𝑖𝑑\) 最大的广告就能最大化平台的eCPM。从机器学习的角度来说这是一个普通的回归问题,但是它的特殊性在于训练数据只有0/1的值——因为我们没有办法给同一个用户展示同一个广告1万次,然后统计点击的次数来估计真实的点击率。另外有人也许会有这样的看法:对于某一个特定的曝光,某个用户是否点击某个广告是确定的,第一次不点,第二次也不会点,因此点击率是一个0/1的固定值而不是一个0-1之间的概率值。这个说法有一些道理,原因是第二次实验和第一次使用不是独立同分布的。“真正”的做法是第二次做实验前要擦除用户第一次实验的记忆,然后在一模一样的场景(时间、地点……)下做 \(N\)...
Search&Rec
2026-04-15
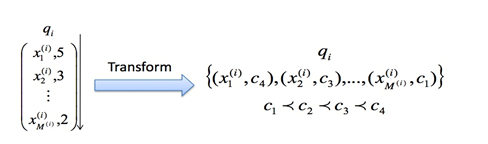
Learning to rank 排序学习是推荐、搜索、广告的核心方法。排序结果的好坏很大程度影响用户体验、广告收入等。排序学习可以理解为机器学习中用户排序的方法,这里首先推荐一本微软亚洲研究院刘铁岩老师关于LTR的著作,Learning to Rank for Information Retrieval,书中对排序学习的各种方法做了很好的阐述和总结。我这里是一个超级精简版。 排序学习是一个有监督的机器学习过程,对每一个给定的查询-文档对,抽取特征,通过日志挖掘或者人工标注的方法获得真实数据标注。然后通过排序模型,使得输入能够和实际的数据相似。常用的排序学习分为三种类型:PointWise,PairWise和ListWise。 PointWise 单文档方法的处理对象是单独的一篇文档,将文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档打分,打分结果即是搜索结果...
Search&Rec
2026-04-15
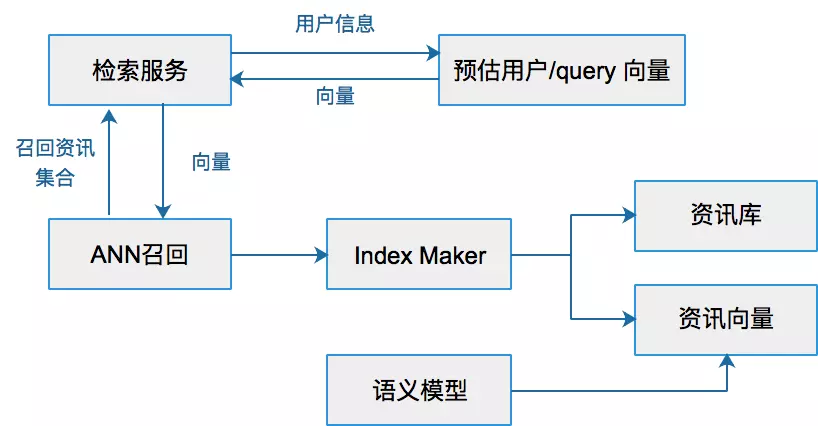
概述 新闻推荐系统从海量新闻中推荐出你感兴趣的新闻,百度从海量的搜索结果中找到最优的结果,短视频推荐出你每天都停不下来的视频流,这些里面都包含ANN方法。当然,在现在的检索系统中,往往是多分支并行触发的效果,虽然DNN 大行其道,但是 ANN 一直不可或缺。 通用理解上,ANN(Approximate Nearest Neighbor)是在向量空间中搜索向量最近邻的优化问题。目前业界常用nmslib、Annoy算法作为实现。在实际的工程应用中,ANN是作为一种向量检索技术应用,用于解决长尾Query召回问题。将一个资讯的ANN 召回系统抽象出来大概是下面的样子。 Ann(approximate nearest neighbor)是指一系列用于解决最近邻查找问题的近似算法。最近邻查找问题,即在给定的向量集合中查找出与目标向量距离最近的N个向量。...
Search&Rec
2026-04-15

一句话总结 正排索引:一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。 倒排索引:Inverted index,指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。 倒排索引创建索引的流程 形成文档列表 首先对原始文档数据进行编号(DocID),形成列表,就是一个文档列表。 创建倒排索引列表 对文档中数据进行分词,得到词条。对词条进行编号,以词条创建索引。保存包含这些词条的文档的编号信息。 搜索的过程 当用户输入任意的词条时,首先对用户输入的数据进行分词,得到用户要搜索的所有词条,然后拿着这些词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号。 然后根据这些编号去文档列表中找到文档 正排和倒排 正排索引(正向索引) 通过文档ID查文档中的各个词:url -> term,ID为关键字,后面的拉链为文档里面每个字的位置信息 正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。...