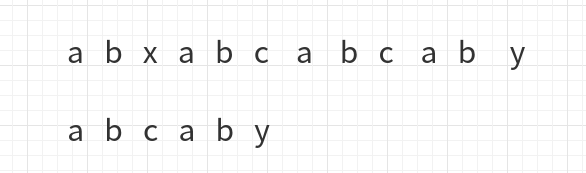
kmp算法用于字符串的模式匹配,也就是找到模式字符串在目标字符串的第一次出现的位置比如 abababc 那么 bab 在其位置1处, bc 在其位置5处,我们首先想到的最简单的办法就是蛮力的一个字符一个字符的匹配,但那样的时间复杂度会是 \(O(m*n)\) 。kmp算法保证了时间复杂度为 \(O(m+n)\) 。 基本原理 举个例子: 发现 x 与 c 不同后,进行移动 a 与 x 不同,再次移动 此时比较到了 c 与 y , 于是下一步移动成了下面这样 这一次的移动与前两次的移动不同,之前每次比较到上面长字符串的字符位置后,直接把模式字符串的首字符与它对齐,这次并没有,原因是这次移动之前, y 与 c 对齐,但是 y 前边的 ab 是与自己的前缀 ab 一样,于是 ab 并不用再比较,直接从第三个位置开始比较,如图: 所以说 kmp算法对于这种情况就直接使用当前比较字符之前的最长相同的前后缀,然后将前缀与上面的长字符串对齐,继续比较后面的字符串 。 这里kmp算法中的一个重要点就来了,如何找到 模式字符串中每位字符之前的最长相同前后缀呢 这里继续用一个例子举例: 下面的数字记录...

160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...
线性结构与技巧 基础容器 数组 (Array) 链表 (Linked List) 字符串 (String) KMP算法 核心技巧 双指针 滑动窗口 二分查找 栈与队列 栈 & 队列 (Stack & Queue) 单调队列 树与图论 树与堆 (Tree & Heap) 树的遍历 二叉树 堆(大顶堆&小顶堆) 优先队列 图 (Graph) 搜索(BFS/DFS) 最小生成树 核心算法思想 动态规划 (DP) 基础 DP 背包问题 排序 基础排序算法 排序算法 数据处理 哈希表 Math

236. 二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百 度百科中最近公共祖先的定义为:“对于有根树 \(T\) 的两个节点 \(p\) 、 \(q\) ,最近公共祖先表示为一个节点 \(x\) ,满足 \(x\) 是 \(p\) 、 \(q \) 的祖先且 \(x\) 的深度尽可能大( 一个节点也可以是它自己的祖先 )。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root = [1,2], p = 1, q = 2
输出:1 提示: 树中节点数目在范围 [2, 10 5 ] 内。 -10 9 <= Node.val <= 10 9 所有 Node.val...
二叉树结构 class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None 递归 时间复杂度: \(O(n)\) , \(n\) 为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度: \(O(h)\) , \(h\) 为树的高度。最坏情况下需要空间 \(O(n)\) ,平均情况为 \(O(logn)\) 递归1: 二叉树遍历最易理解和实现版本 class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
# 前序递归
return [root.val] + self.preorderTraversal(root.left) + self.preorderTraversal(root.right)
...

48. 旋转图像 题目 给定一个 \(n × n\) 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。 请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]] 示例 2: 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]] 提示: n == matrix.length == matrix[i].length 1 <= n <= 20 -1000 <= matrix[i][j] <= 1000 题解 这是一个经典的矩阵操作问题。要在原地(In-place)将图像顺时针旋转 90 度,我们可以利用矩阵的几何性质。 最直观且易于实现的方法是将...
3D Model
2026-04-15

Temporal action detection可以分为两种setting, 一是offline的,在检测时视频是完整可得的,也就是可以利用完整的视频检测动作发生的时间区间(开始时间+结束时间)以及动作的类别; 二是 online的,即处理的是一个视频流,需要在线的检测(or 预测未来)发生的动作类别,但无法知道检测时间点之后的内容。online的问题设定更符合surveillance的需求,需要做实时的检测或者预警;offline的设定更符合视频搜索的需求,比如youtube可能用到的 highlight detection / preview generation。 问题演化 Early action detection -> Online action detection -> Online action anticipation: 在学术界关注online action detection之前,有一个相似的问题叫做 early event detection ,问题定义是 “detect the event as soon as possible, after it...
3D Model
2026-04-15

Classification,Detection Classification:给定预先裁剪好的视频片段,预测其所属的行为类别 Detection:视频是未经过裁剪的,需要先进行人的检测where和行为定位(分析行为的始末时间)when,再进行行为的分类what。 通常所说的行为识别更偏向于对时域预先分割好的序列进行行为动作的分类,即 Trimmed Video Action Classification。 Two-Stream Two-stream convolutional networks 简介 Two-Stream CNN网络顾名思义分为两个部分, 空间流 处理 RGB图像 ,得到形状信息; 时间流/光流 处理 光流图像 ,得到运动信息。 两个流最后经过softmax后,做分类分数的融合,可以采用平均法或者是SVM。不过这两个流都是二维卷积操作。最终联合训练,并分类。 如图所示,其实做法非常的简单,相当于训练两个CNN的分类器。一个是专门对于 RGB 图的, 一个专门对于光流图的, 然后将两者的结果进行一个 fushion 的过程。...
Reinforcement Learning
2026-04-15

引言 DDPG同样使用了Actor-Critic的结构,Deterministic的确定性策略是和随机策略相对而言的,对于某一些动作集合来说,它可能是连续值,或者非常高维的离散值,这样动作的空间维度极大。如果我们使用随机策略,即像DQN一样研究它所有的可能动作的概率,并计算各个可能的动作的价值的话,那需要的样本量是非常大才可行的。于是有人就想出使用确定性策略来简化这个问题。 作为随机策略,在相同的策略,在同一个状态 \(s\) 处,采用的动作 \(\pi_\theta(a|s)\) 是基于一个概率分布的,即是不确定的。而确定性策略则决定简单点,虽然在同一个状态处,采用的动作概率不同,但是最大概率只有一个,如果我们只取最大概率的动作,去掉这个概率分布,那么就简单多了。即作为确定性策略,相同的策略,在同一个状态处,动作是唯一确定的,即策略变成 \[a = \mu(s, \theta)\] 所以DDPG基于确定性策略梯度(DPG)算法,结合了DQN的成功经验。 使用回放缓冲区中的样本进行离策略训练,以减少样本之间的相关性 使用目标Q网络在时序差分更新过程中提供一致的目标...
Generative Model
2026-04-15

简介 如果以概率的视角看待世界的生成模型。 在这样的世界观中,我们可以将任何类型的观察数据(例如 \(D\) )视为来自底层分布(例如 \( p_{data}\) )的有限样本集。 任何生成模型的目标都是在访问数据集 \(D\) 的情况下近似该数据分布。 如果我们能够学习到一个好的生成模型,我们可以将学习到的模型用于下游推理。 我们主要对数据分布的参数近似感兴趣,在一组有限的参数中,它总结了关于数据集 \(D\) 的所有信息。 与非参数模型相比,参数模型在处理大型数据集时能够更有效地扩展,但受限于可以表示的分布族。 在参数的设置中,我们可以将学习生成模型的任务视为在模型分布族中挑选参数,以最小化模型分布和数据分布之间的距离。 如上图,给定一个狗的图像数据集,我们的目标是学习模型族 \(M\) 中生成模型 θ 的参数,使得模型分布 \(p_θ\) 接近 \(p_{data}\) 上的数据分布。 在数学上,我们可以将我们的目标指定为以下优化问题: \[\mathop{min}\limits_{\theta\in M}d(p_\theta,p_{data})\] 其中, \(d()\)...
Large Model
2026-04-15

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
Reinforcement Learning
2026-04-15

概述与理论背景 Actor-Critic方法是强化学习中的一类重要算法, 它巧妙地结合了基于策略(policy-based)和基于价值(value-based)的方法 。在这种结构中, "Actor"指策略更新步骤,负责根据策略执行动作;而"Critic"指价值更新步骤,负责评估Actor的表现 。从另一个角度看,Actor-Critic方法本质上仍是策略梯度算法,可以通过扩展策略梯度算法获得。 Actor-Critic方法在强化学习中的位置非常重要,它既保留了策略梯度方法直接优化策略的优势,又利用了值函数方法的效率。这种结合使得Actor-Critic方法成为解决复杂强化学习问题的强大工具。 最简单的Actor-Critic算法(QAC) QAC算法通过扩展策略梯度方法得到。策略梯度方法的核心思想是通过最大化标量度量 \(J(\theta)\) 来搜索最优策略。其梯度上升算法为: \[\begin{equation}\begin{aligned}\theta_{t+1} &= \theta_t + \alpha\nabla_\theta J(\theta_t)\\&=...