Algorithm
2026-04-15
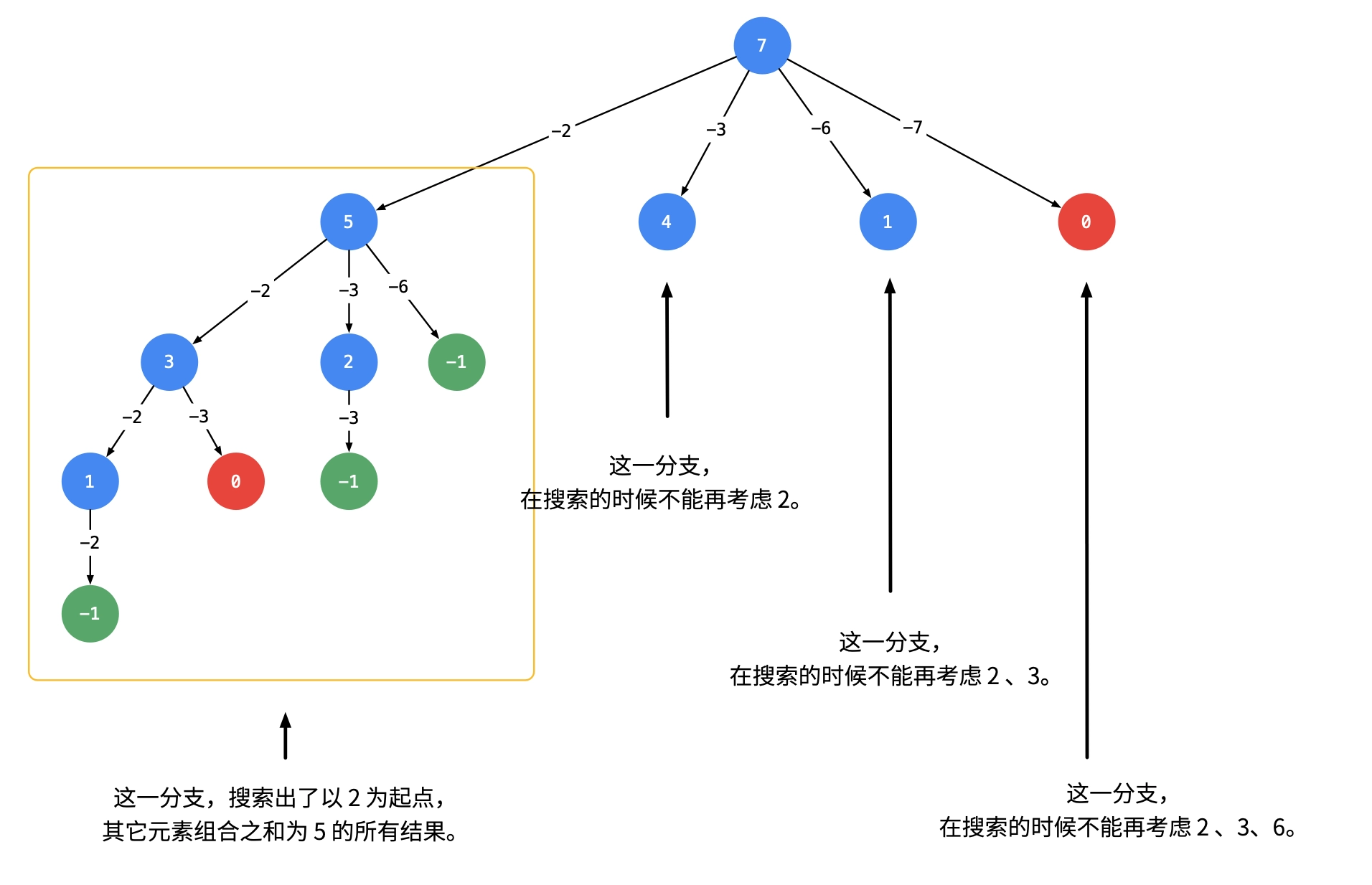
DFS 39&40. 组合总和 题目 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。 candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。 对于给定的输入,保证和为 target 的不同组合数少于 150 个。 示例 1: 输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。 示例 2: 输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]] 示例 3: 输入: candidates = [2], target = 1
输出: [] 提示: 1 <=...