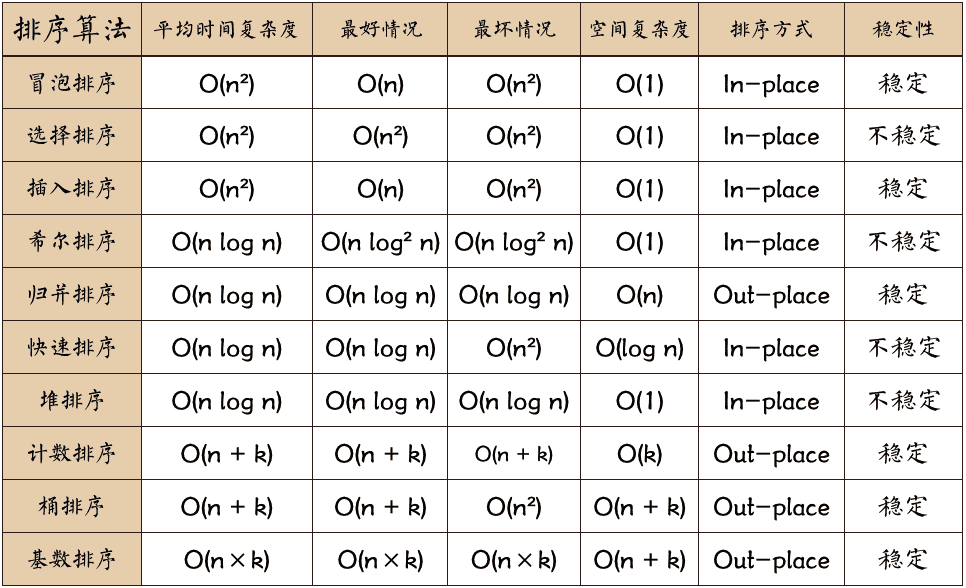
排序算法是《数据结构与算法》中最基本的算法之一。 排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。用一张图概括: 冒泡排序 冒泡排序(Bubble Sort)是一种简单的排序算法,它通过重复地遍历待排序的列表,比较相邻的元素并交换它们的位置来实现排序。该算法的名称来源于较小的元素会像"气泡"一样逐渐"浮"到列表的顶端。 算法步骤 比较相邻元素 :从列表的第一个元素开始,比较相邻的两个元素。 交换位置 :如果前一个元素比后一个元素大,则交换它们的位置。 重复遍历 :对列表中的每一对相邻元素重复上述步骤,直到列表的末尾。这样,最大的元素会被"冒泡"到列表的最后。 缩小范围 :忽略已经排序好的最后一个元素,重复上述步骤,直到整个列表排序完成。 假设有一个待排序的列表 [5, 3, 8, 4, 6] ,冒泡排序的过程如下: 第一轮遍历 : 比较 5 和 3,交换位置,列表变为 [3,...
Algorithm
2026-04-15
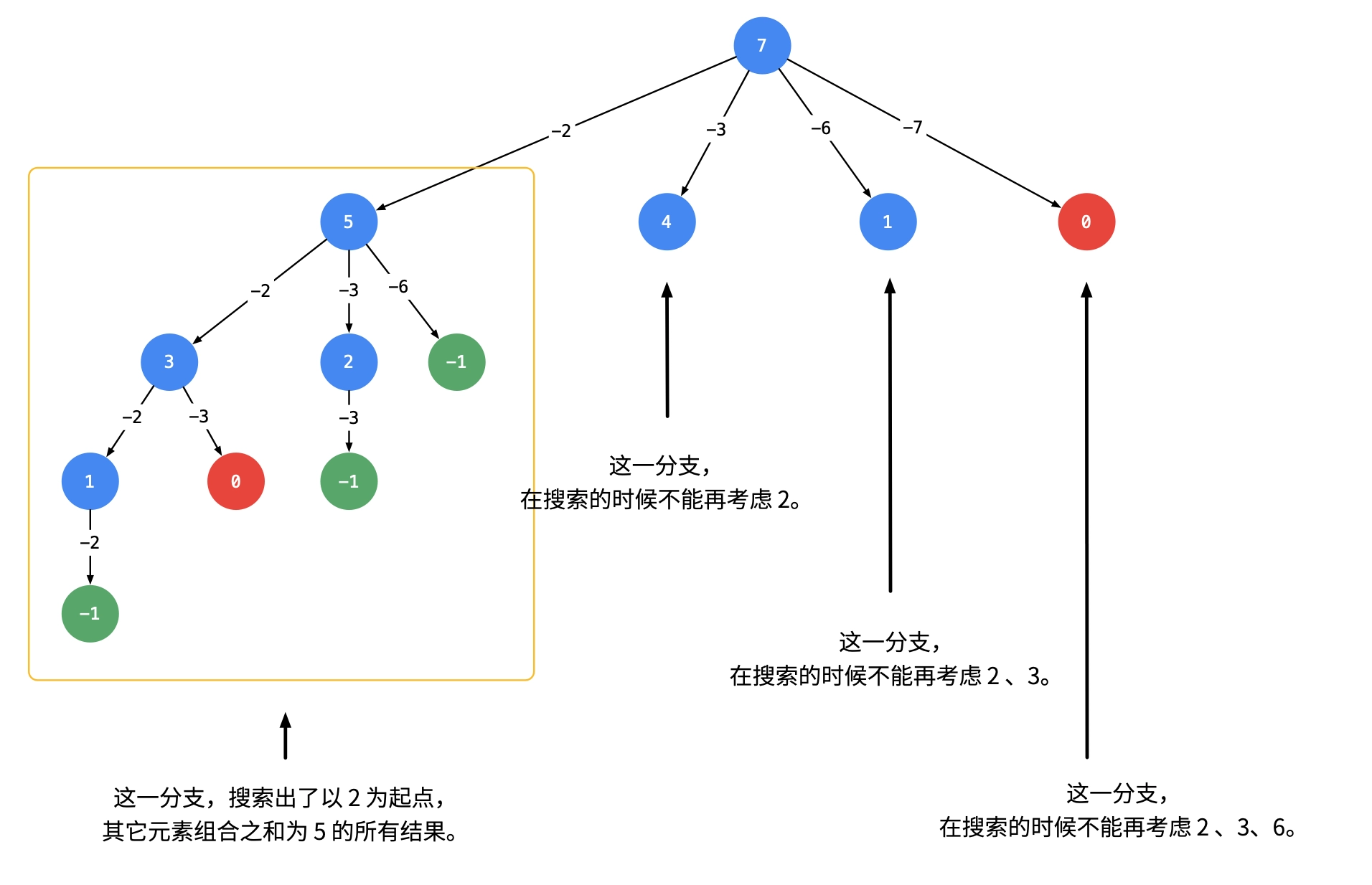
DFS 39&40. 组合总和 题目 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。 candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。 对于给定的输入,保证和为 target 的不同组合数少于 150 个。 示例 1: 输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。 示例 2: 输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]] 示例 3: 输入: candidates = [2], target = 1
输出: [] 提示: 1 <=...
堆和优先队列的关系 这是一个非常经典且核心的计算机科学概念问题。一言以蔽之: 优先队列(Priority Queue)是逻辑接口(ADT),而堆(Heap)是实现这个接口最高效的物理数据结构。 它们的关系可以类比为 “接口(Interface)” 与 “实现类(Implementation)” 的关系,或者 “汽车(功能)”与 “发动机(核心组件)” 的关系。 优先队列 (Priority Queue) —— 逻辑层 (ADT) 定义 :它是一种 抽象数据类型 (Abstract Data Type, ADT) 。它定义了数据的 行为 ,而不是数据的存储方式。 规则 :普通的队列是“先进先出”(FIFO),而优先队列是 “优先级最高的先出” 。 核心操作 : insert(item, priority) : 插入一个带优先级的元素。 deleteMax() 或 deleteMin() : 取出并删除优先级最高(或最低)的元素。 peek() : 查看优先级最高的元素。 堆 (Heap) —— 物理层 (Data Structure) 定义 :它是一种具体的 数据结构 。通常指 二叉堆...
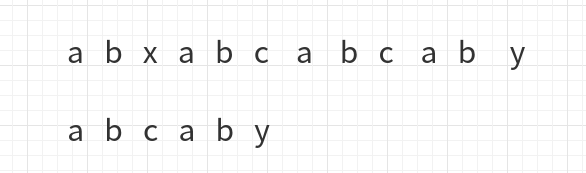
kmp算法用于字符串的模式匹配,也就是找到模式字符串在目标字符串的第一次出现的位置比如 abababc 那么 bab 在其位置1处, bc 在其位置5处,我们首先想到的最简单的办法就是蛮力的一个字符一个字符的匹配,但那样的时间复杂度会是 \(O(m*n)\) 。kmp算法保证了时间复杂度为 \(O(m+n)\) 。 基本原理 举个例子: 发现 x 与 c 不同后,进行移动 a 与 x 不同,再次移动 此时比较到了 c 与 y , 于是下一步移动成了下面这样 这一次的移动与前两次的移动不同,之前每次比较到上面长字符串的字符位置后,直接把模式字符串的首字符与它对齐,这次并没有,原因是这次移动之前, y 与 c 对齐,但是 y 前边的 ab 是与自己的前缀 ab 一样,于是 ab 并不用再比较,直接从第三个位置开始比较,如图: 所以说 kmp算法对于这种情况就直接使用当前比较字符之前的最长相同的前后缀,然后将前缀与上面的长字符串对齐,继续比较后面的字符串 。 这里kmp算法中的一个重要点就来了,如何找到 模式字符串中每位字符之前的最长相同前后缀呢 这里继续用一个例子举例: 下面的数字记录...

160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...
线性结构与技巧 基础容器 数组 (Array) 链表 (Linked List) 字符串 (String) KMP算法 核心技巧 双指针 滑动窗口 二分查找 栈与队列 栈 & 队列 (Stack & Queue) 单调队列 树与图论 树与堆 (Tree & Heap) 树的遍历 二叉树 堆(大顶堆&小顶堆) 优先队列 图 (Graph) 搜索(BFS/DFS) 最小生成树 核心算法思想 动态规划 (DP) 基础 DP 背包问题 排序 基础排序算法 排序算法 数据处理 哈希表 Math

236. 二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百 度百科中最近公共祖先的定义为:“对于有根树 \(T\) 的两个节点 \(p\) 、 \(q\) ,最近公共祖先表示为一个节点 \(x\) ,满足 \(x\) 是 \(p\) 、 \(q \) 的祖先且 \(x\) 的深度尽可能大( 一个节点也可以是它自己的祖先 )。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root = [1,2], p = 1, q = 2
输出:1 提示: 树中节点数目在范围 [2, 10 5 ] 内。 -10 9 <= Node.val <= 10 9 所有 Node.val...
二叉树结构 class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None 递归 时间复杂度: \(O(n)\) , \(n\) 为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度: \(O(h)\) , \(h\) 为树的高度。最坏情况下需要空间 \(O(n)\) ,平均情况为 \(O(logn)\) 递归1: 二叉树遍历最易理解和实现版本 class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
# 前序递归
return [root.val] + self.preorderTraversal(root.left) + self.preorderTraversal(root.right)
...

48. 旋转图像 题目 给定一个 \(n × n\) 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。 请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]] 示例 2: 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]] 提示: n == matrix.length == matrix[i].length 1 <= n <= 20 -1000 <= matrix[i][j] <= 1000 题解 这是一个经典的矩阵操作问题。要在原地(In-place)将图像顺时针旋转 90 度,我们可以利用矩阵的几何性质。 最直观且易于实现的方法是将...
Reinforcement Learning
2026-04-15

引言 强化学习中,找到最优策略是核心目标。本文详细介绍三种能够找到最优策略的基础算法: 价值迭代、策略迭代和截断策略迭代 。这些算法属于动态规划范畴,需要系统模型,是后续无模型强化学习算法的重要基础。 在强化学习的发展路线中,这些算法处于"基础工具"到"算法/方法"的过渡阶段,是从"有模型"到"无模型"学习的重要桥梁。 价值迭代(Value iteration) 价值迭代算法 基于收缩映射定理求解贝尔曼最优方程 。其核心迭代公式为: \[\begin{equation}v_{k+1} = \max_{\pi \in \Pi} (r_\pi + \gamma P_\pi v_k), k = 0, 1, 2, ...\tag{1}\end{equation}\] 根据收缩映射定理,当 \(k \to \infty\) 时, \(v_k\) 和 \(\pi_k\) 分别收敛到最优状态值和最优策略。 每次迭代包含两个步骤: 策略更新步骤 (policy update step) :找到能解决以下优化问题的策略 \[\pi_{k+1} = \arg\max_\pi (r_\pi +...
Math
2026-04-15

引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 \(X\) ,其取值来自有限集合 \(\mathcal{X}\) 。我们的目标是估计 \(E[X]\) 。假设我们有一个独立同分布的样本序列 \(\{x_i\}_{i=1}^n\) ,那么 \(X\) 的期望值可以近似为: \[E[X] \approx \bar{x} = \frac{1}{n}\sum_{i=1}^n x_i\] 非增量方法与增量方法 非增量方法 :先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法 :定义 \[w_{k+1} = \frac{1}{k}\sum_{i=1}^k x_i, k = 1, 2, ...\] 可以推导出递归公式: \[{w}_{k + 1} =...
Reinforcement Learning
2026-04-15
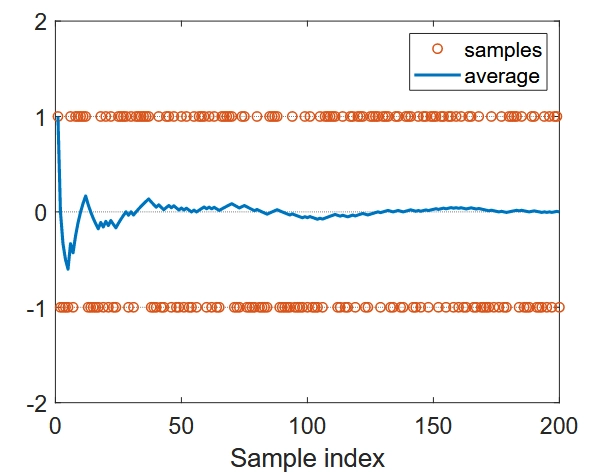
引言与背景 蒙特卡洛方法是强化学习中的重要算法类别,它标志着从基于模型到无模型算法的转变。这类算法不依赖环境模型,而是通过与环境的直接交互获取经验数据来学习最优策略。 蒙特卡洛方法在强化学习算法谱系中处于"无模型"方法的起始位置,是从基于模型的方法(如值迭代和策略迭代)向无模型方法过渡的第一步。 无模型强化学习的核心理念可以简述为: 如果没有模型,我们必须有数据;如果没有数据,我们必须有模型;如果两者都没有,我们就无法找到最优策略。在强化学习中,"数据"通常指智能体与环境交互的经验 。 均值估计问题 在介绍蒙特卡洛强化学习算法之前,我们首先需要理解均值估计问题,这是理解从数据而非模型中学习的基础。 考虑一个可以取有限实数集合 \(X\) 中值的随机变量 \(X\) ,我们的任务是计算 \(X\) 的均值或期望值: \(E[X]\) 有两种方法可以计算 \(E[X]\) : 基于模型的方法 :当已知随机变量的概率分布时,可以直接根据期望值的定义计算: \[E[X] = \sum_{x \in X} p(x) \cdot x\] 其中 \(p(x)\) 是 \(X\) 取值为 \(x\)...