Computer Vision
2026-04-15
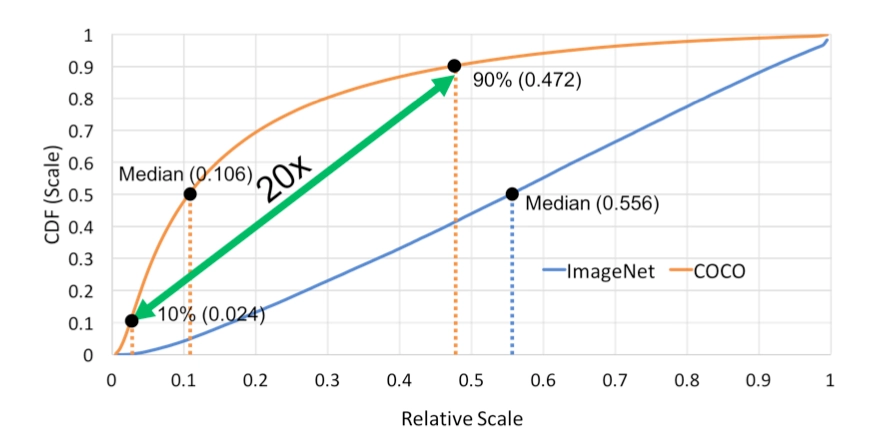
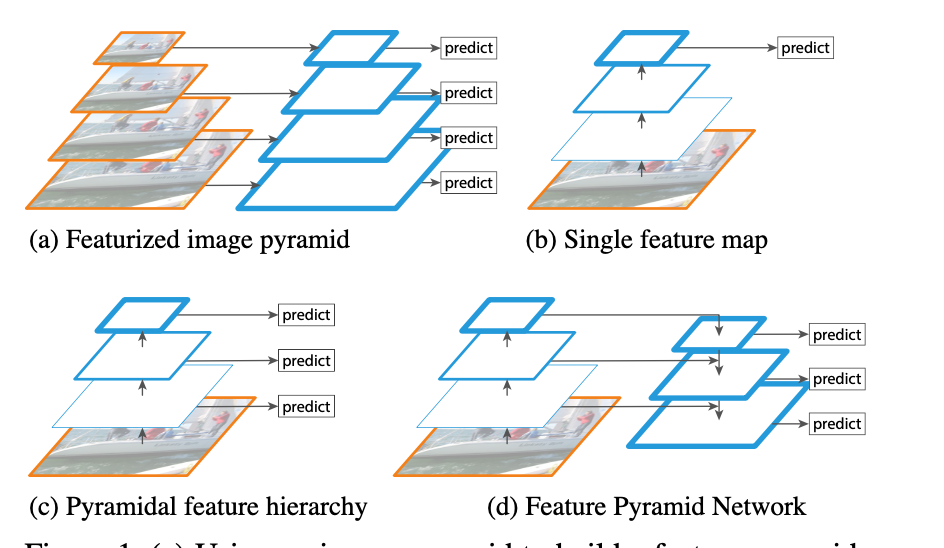
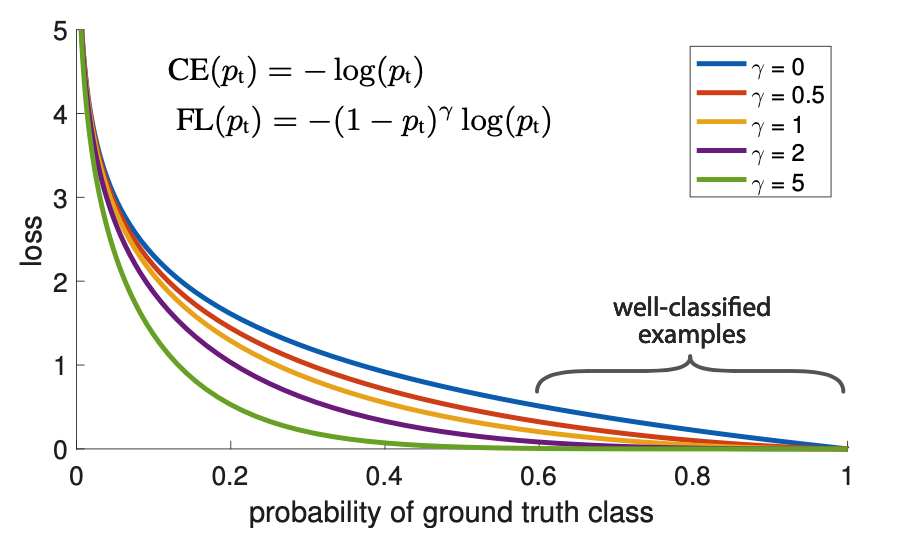
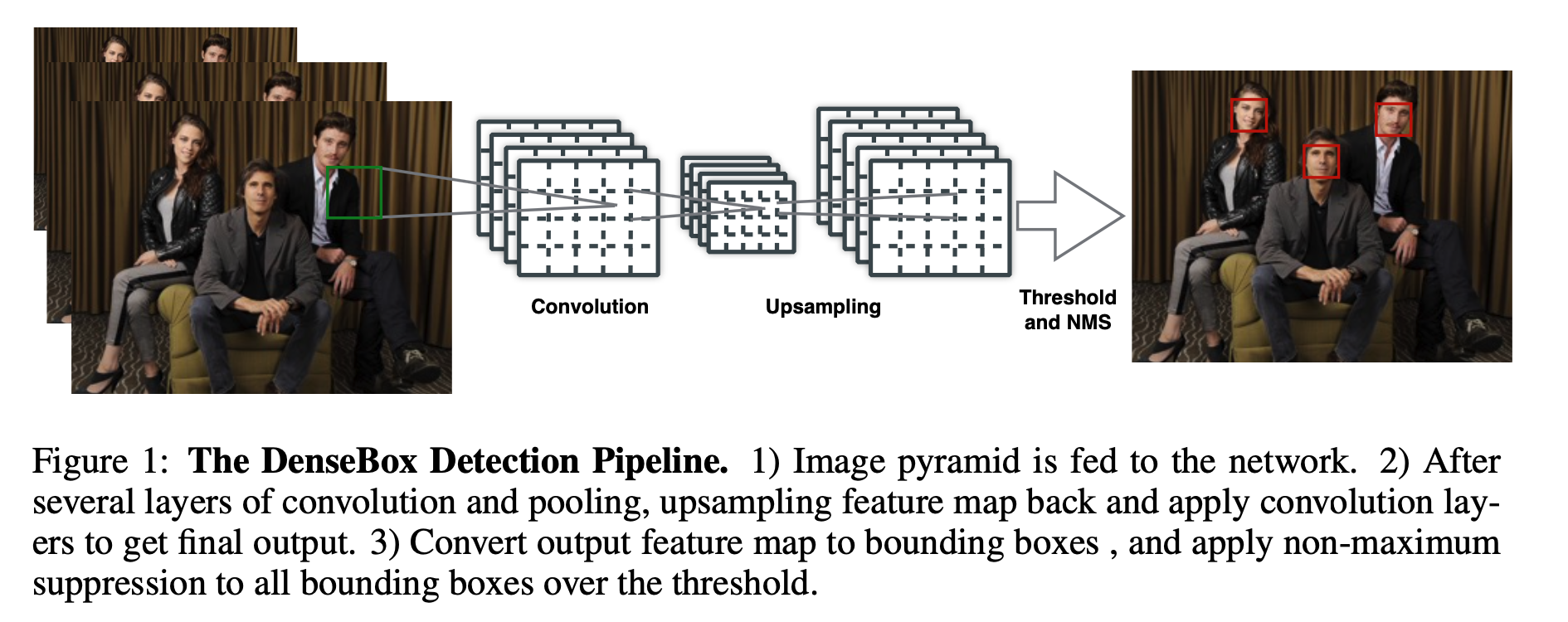
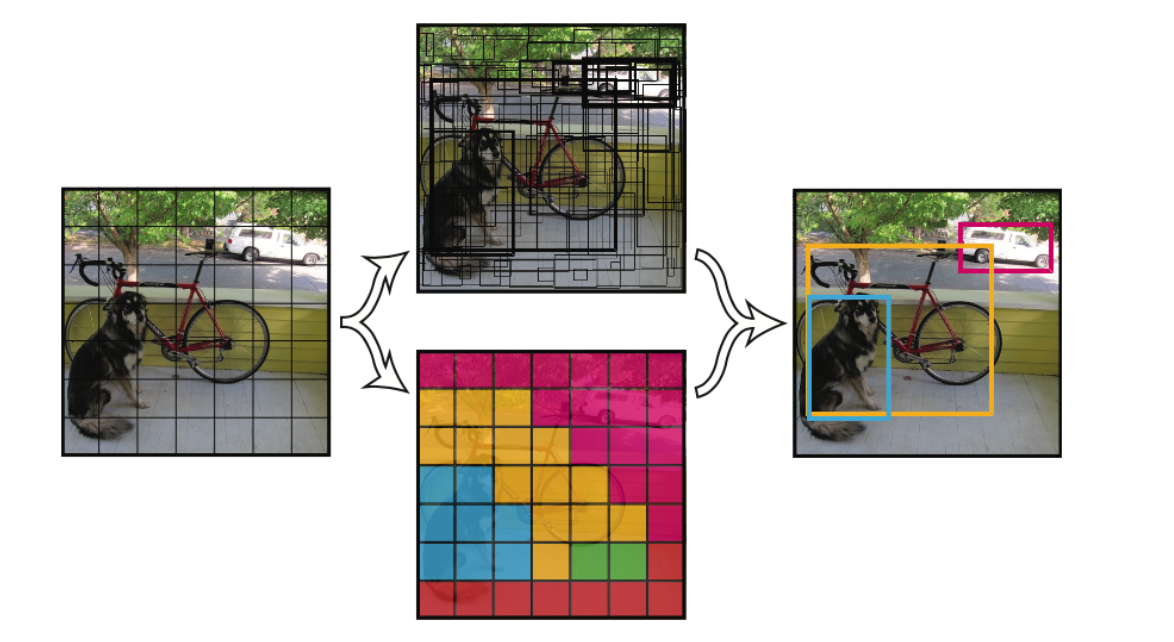
传统的图像金字塔 最开始在深度学习方法流行之前,对于不同尺度的目标,大家普遍使用将原图构建出不同分辨率的图像金字塔,再对每层金字塔用固定输入分辨率的分类器在该层滑动来检测目标,以求在金字塔底部检测出小目标;或者只用一个原图,在原图上, 用不同分辨率的分类器来检测目标,以求在比较小的窗口分类器中检测到小目标。 经典的 基于简单矩形特征(Haar)+级联Adaboost与Hog特征+SVM的DPM目标识别框架,均使用图像金字塔的方式处理多尺度目标 ,早期的CNN目标识别框架同样采用该方式,但对图像金字塔中的每一层分别进行CNN提取特征,耗时与内存消耗均无法满足需求。但 该方式毫无疑问仍然是最优的。 值得一提的是,其实目前大多数深度学习算法提交结果进行排名的时候,大多使用 多尺度测试 。同时类似于SNIP使用多尺度训练,均是图像金字塔的多尺度处理。 SNIP 图像分类算法,比如ResNeXt-101 32 × 48d网络结构,在Imagenet数据集上的Top5准确率已经98%左右,Top1为85%。对于图像检测算法,最好的模型在coco数据集上的效果 \(AP_{50}\)...