
160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...
线性结构与技巧 基础容器 数组 (Array) 链表 (Linked List) 字符串 (String) KMP算法 核心技巧 双指针 滑动窗口 二分查找 栈与队列 栈 & 队列 (Stack & Queue) 单调队列 树与图论 树与堆 (Tree & Heap) 树的遍历 二叉树 堆(大顶堆&小顶堆) 优先队列 图 (Graph) 搜索(BFS/DFS) 最小生成树 核心算法思想 动态规划 (DP) 基础 DP 背包问题 排序 基础排序算法 排序算法 数据处理 哈希表 Math

236. 二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百 度百科中最近公共祖先的定义为:“对于有根树 \(T\) 的两个节点 \(p\) 、 \(q\) ,最近公共祖先表示为一个节点 \(x\) ,满足 \(x\) 是 \(p\) 、 \(q \) 的祖先且 \(x\) 的深度尽可能大( 一个节点也可以是它自己的祖先 )。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root = [1,2], p = 1, q = 2
输出:1 提示: 树中节点数目在范围 [2, 10 5 ] 内。 -10 9 <= Node.val <= 10 9 所有 Node.val...
二叉树结构 class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None 递归 时间复杂度: \(O(n)\) , \(n\) 为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度: \(O(h)\) , \(h\) 为树的高度。最坏情况下需要空间 \(O(n)\) ,平均情况为 \(O(logn)\) 递归1: 二叉树遍历最易理解和实现版本 class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
# 前序递归
return [root.val] + self.preorderTraversal(root.left) + self.preorderTraversal(root.right)
...

48. 旋转图像 题目 给定一个 \(n × n\) 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。 请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]] 示例 2: 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]] 提示: n == matrix.length == matrix[i].length 1 <= n <= 20 -1000 <= matrix[i][j] <= 1000 题解 这是一个经典的矩阵操作问题。要在原地(In-place)将图像顺时针旋转 90 度,我们可以利用矩阵的几何性质。 最直观且易于实现的方法是将...
Machine Learning
2026-04-15
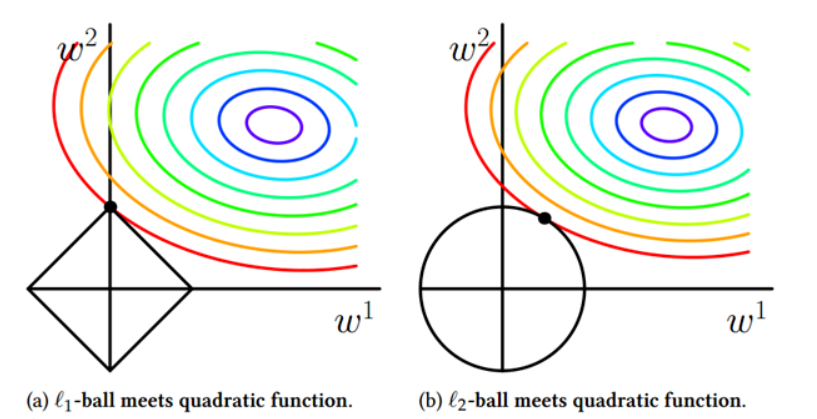
正则化 正则化是一个通用的算法和思想,所有会产生过拟合现象的算法都可以使用正则化来避免过拟合。 在经验风险最小化的基础上(也就是训练误差最小化),尽可能采用简单的模型,可以有效提高泛化预测精度。如果模型过于复杂,变量值稍微有点变动,就会引起预测精度问题。正则化之所以有效,就是因为其降低了特征的权重,使得模型更为简单。 正则化一般会采用 L1 范式或者 L2 范式,其形式分别为 \(\Phi(w)=||x||_1\) 和 \(\Phi(w)=||x||_2\) 。 L1正则化 LASSO 回归,相当于为模型添加了这样一个先验知识: \(w\) 服从零均值拉普拉斯分布。 首先看看拉普拉斯分布长什么样子: \[f(w|\mu,b)=\frac{1}{2b}exp(-\frac{|w-\mu|}{b})\] 由于引入了先验知识,所以似然函数这样写:...
Machine Learning
2026-04-15
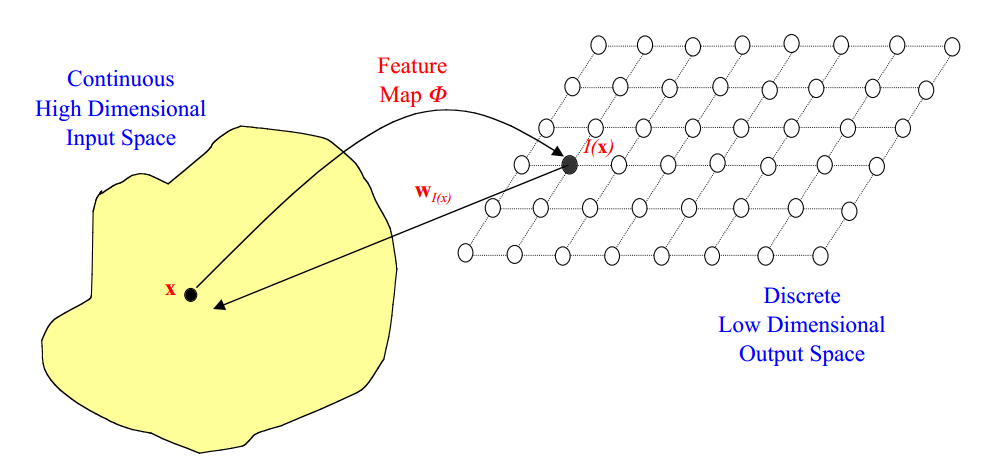
什么是自组织映射? 一个特别有趣的无监督系统是基于 竞争性学习 ,其中输出神经元之间竞争激活,结果是在任意时间只有一个神经元被激活。这个激活的神经元被称为 胜者神经元(winner-takes-all neuron) 。这种竞争可以通过在神经元之间具有 横向抑制连接 (负反馈路径)来实现。其结果是神经元被迫对自身进行重新组合,这样的网络我们称之为 自组织映射(Self Organizing Map,SOM) 。 拓扑映射 神经生物学研究表明,不同的感觉输入(运动,视觉,听觉等)以 有序的方式 映射到大脑皮层的相应区域。 这种映射我们称之为 拓扑映射 ,它具有两个重要特性: 在表示或处理的每个阶段,每一条传入的信息都保存在适当的上下文(相邻节点)中 处理密切相关的信息的神经元之间保持密切,以便它们可以通过短突触连接进行交互 我们的兴趣是建立人工的拓扑映射,以神经生物学激励的方式通过自组织进行学习。 我们将遵循 拓扑映射形成的原则 :“拓扑映射中输出层神经元的空间位置对应于输入空间的特定域或特征”。 建立自组织映射 SOM的主要目标是将任意维度的输入信号模式 转换...
Machine Learning
2026-04-15
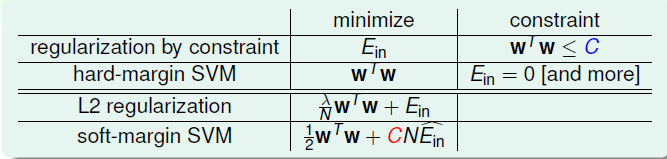
介绍如何将Kernel Trick引入到Logistic Regression,以及LR与SVM的结合 SVM与正则化 首先回顾Soft-Margin SVM的原始问题: \[\begin{aligned}\min\limits_{b,\mathbf{w}, \xi} \quad &\frac{1}{2} \mathbf{w}^T\mathbf{w} + C \cdot \sum\limits_{n=1}^{N}\xi_n \\ s.t. \quad & y_n(\mathbf{w}^T\mathbf{z}^n+b) \geq 1-\xi_n, for \ all\ n \end{aligned}\] 其中 \(ξ_n\) 是训练数据违反边界的多少,没有违反的话, \(ξ_n=0\) ,反之 \(ξ_n>0\) ,换句话说,目标函数的第二项就可以表示模型的损失。现在换一种方式来写,将二者结合起来: \(ξ_n=max(1−y_n(w^Tz^n+b),0)\) ,这一个等式就代表了上面的约束条件,这样上述问题,就与下面的无约束问题等价 \[\begin{aligned} &...
Machine Learning
2026-04-15
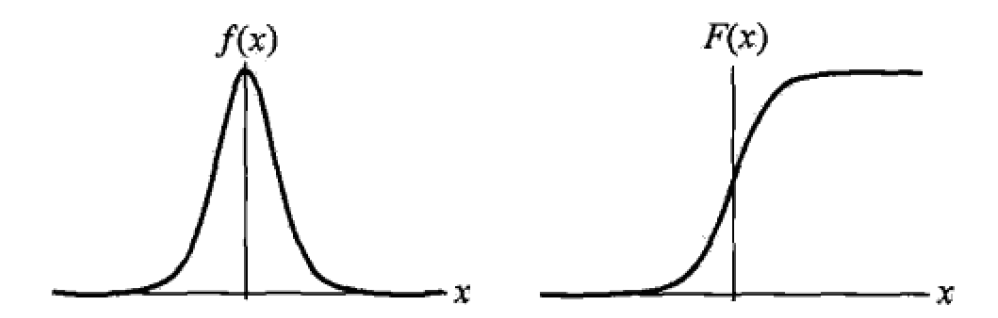
模型介绍 Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。 Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。 Logistic 分布 Logistic 分布是一种连续型的概率分布,其 分布函数 和 密度函数 分别为: \[F(x)=P(X\le x)=\frac{1}{1+e^{-(x-\mu)/\gamma}}\\ f(x)=F^{'}(x)=\frac{e^{-(x-\mu)/\gamma}}{\gamma(1+e^{-(x-\mu)/\gamma})^2}\] 其中, \(\mu\) 表示位置参数, \(\gamma\) 为形状参数。我们可以看下其图像特征: Logistic 分布是由其位置和尺度参数定义的连续分布。Logistic 分布的形状与正态分布的形状相似,但是 Logistic 分布的尾部更长,所以我们可以使用 Logistic...
Machine Learning
2026-04-15
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域算法的基础,比如隐式马尔科夫算法(HMM), LDA主题模型的变分推断等等。本文就对EM算法的原理做一个总结。 EM算法要解决的问题 我们经常会从样本观察数据中,找出样本的模型参数。 最常用的方法就是极大化模型分布的对数似然函数。 但是在一些情况下,我们得到的观察数据有未观察到的隐含数据, 此时我们未知的有隐含数据和模型参数,因而无法直接用极大化对数似然函数得到模型分布的参数 。怎么办呢?这就是EM算法可以派上用场的地方了。 EM算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们 可以先猜想隐含数据(EM算法的E步),接着基于观察数据和猜测的隐含数据一起来极大化对数似然,求解我们的模型参数(EM算法的M步)...
Machine Learning
2026-04-15
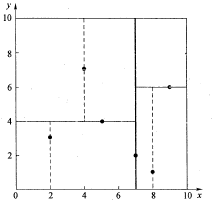
k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构。主要应用于 多维空间关键数据的搜索 (如:范围搜索和最近邻搜索)。 应用背景 SIFT算法中做特征点匹配的时候就会利用到k-d树。而特征点匹配实际上就是一个通过距离函数在高维矢量之间进行相似性检索的问题。针对如何快速而准确地找到查询点的近邻,现在提出了很多高维空间索引结构和近似查询的算法,k-d树就是其中一种。 索引结构中相似性查询有两种基本的方式:一种是范围查询(range searches),另一种是K近邻查询(K-neighbor searches)。范围查询就是给定查询点和查询距离的阈值,从数据集中找出所有与查询点距离小于阈值的数据;K近邻查询是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,就是最近邻查询(nearest neighbor searches)。...
Machine Learning
2026-04-15
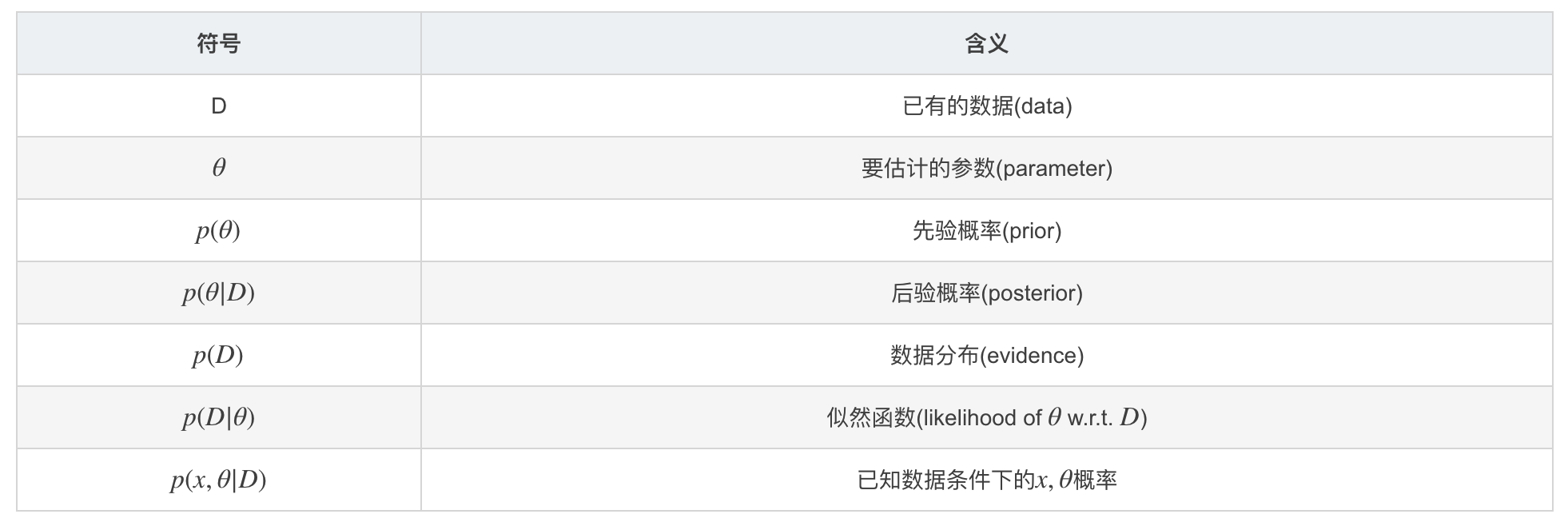
序言 极大似然估计与贝叶斯估计是统计中两种对模型的参数确定的方法,两种参数估计方法使用不同的思想。 前者来自于频率派,认为参数是固定的,我们要做的事情就是根据已经掌握的数据来估计这个参数;而后者属于贝叶斯派,认为参数也是服从某种概率分布的,已有的数据只是在这种参数的分布下产生的。 所以,直观理解上,极大似然估计就是假设一个参数 \(θ\) ,然后根据数据来求出这个 \(θ\) . 而贝叶斯估计的难点在于 \(p(θ)\) 需要人为设定,之后再考虑结合MAP(maximum a posterior)方法来求一个具体的 \(θ\) . 所以极大似然估计与贝叶斯估计最大的不同就在于是否考虑了先验,而两者适用范围也变成了:极大似然估计适用于数据大量,估计的参数能够较好的反映实际情况;而贝叶斯估计则在数据量较少或者比较稀疏的情况下,考虑先验来提升准确率。 预知识 为了更好的讨论,本节会先给出我们要解决的问题,然后给出一个实际的案例。这节不会具体涉及到极大似然估计和贝叶斯估计的细节,但是会提出问题和实例,便于后续方法理解。 问题前提 首先,我们有一堆数据...