二叉树结构 class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None 递归 时间复杂度: \(O(n)\) , \(n\) 为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度: \(O(h)\) , \(h\) 为树的高度。最坏情况下需要空间 \(O(n)\) ,平均情况为 \(O(logn)\) 递归1: 二叉树遍历最易理解和实现版本 class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
# 前序递归
return [root.val] + self.preorderTraversal(root.left) + self.preorderTraversal(root.right)
...

48. 旋转图像 题目 给定一个 \(n × n\) 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。 请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]] 示例 2: 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]] 提示: n == matrix.length == matrix[i].length 1 <= n <= 20 -1000 <= matrix[i][j] <= 1000 题解 这是一个经典的矩阵操作问题。要在原地(In-place)将图像顺时针旋转 90 度,我们可以利用矩阵的几何性质。 最直观且易于实现的方法是将...
3D Model
2026-04-15
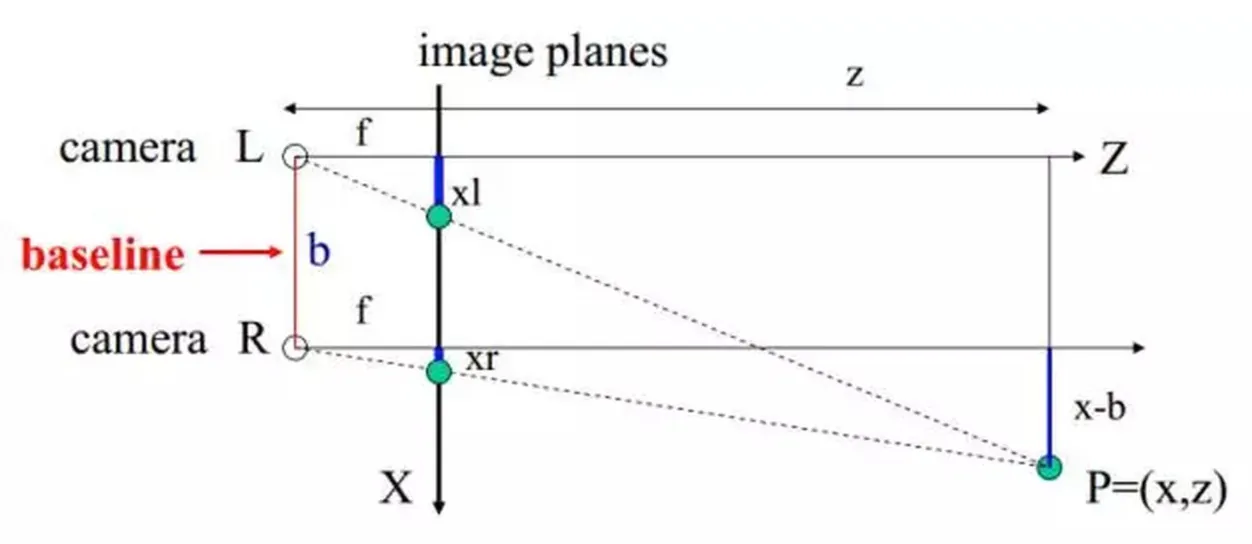
深度相机 “工欲善其事必先利其器‘’我们先从能够获取RGBD数据的相机开始谈起。首先我们来看一看其分类。 根据其工作原理主要分为三类: 1.双目方案 基于双目立体视觉的深度相机类似人类的双眼,和基于TOF、结构光原理的深度相机不同,它不对外主动投射光源,完全依靠拍摄的两张图片(彩色RGB或者灰度图)来计算深度,因此有时候也被称为被动双目深度相机。比较知名的产品有STEROLABS 推出的 ZED 2K Stereo Camera和Point Grey 公司推出的 BumbleBee。 双目立体视觉是基于视差原理,由多幅图像获取物体三维几何信息的方法。在机器视觉系统中, 双目视觉一般由双摄像机从不同角度同时获取周围景物的两幅数字图像,或有由单摄像机在不同时刻从不同角度获取周围景物的两幅数字图像 ,并基于视差原理即可恢复出物体三维几何信息,重建周围景物的三维形状与位置。 双目视觉有的时候我们也会把它称为体视,是人类利用双眼获取环境三维信息的主要途径。从目前来看,随着机器视觉理论的发展,双目立体视觉在机器视觉研究中发回来看了越来越重要的作用 为什么非得用双目相机才能得到深度?...
Deep Learning
2026-04-15
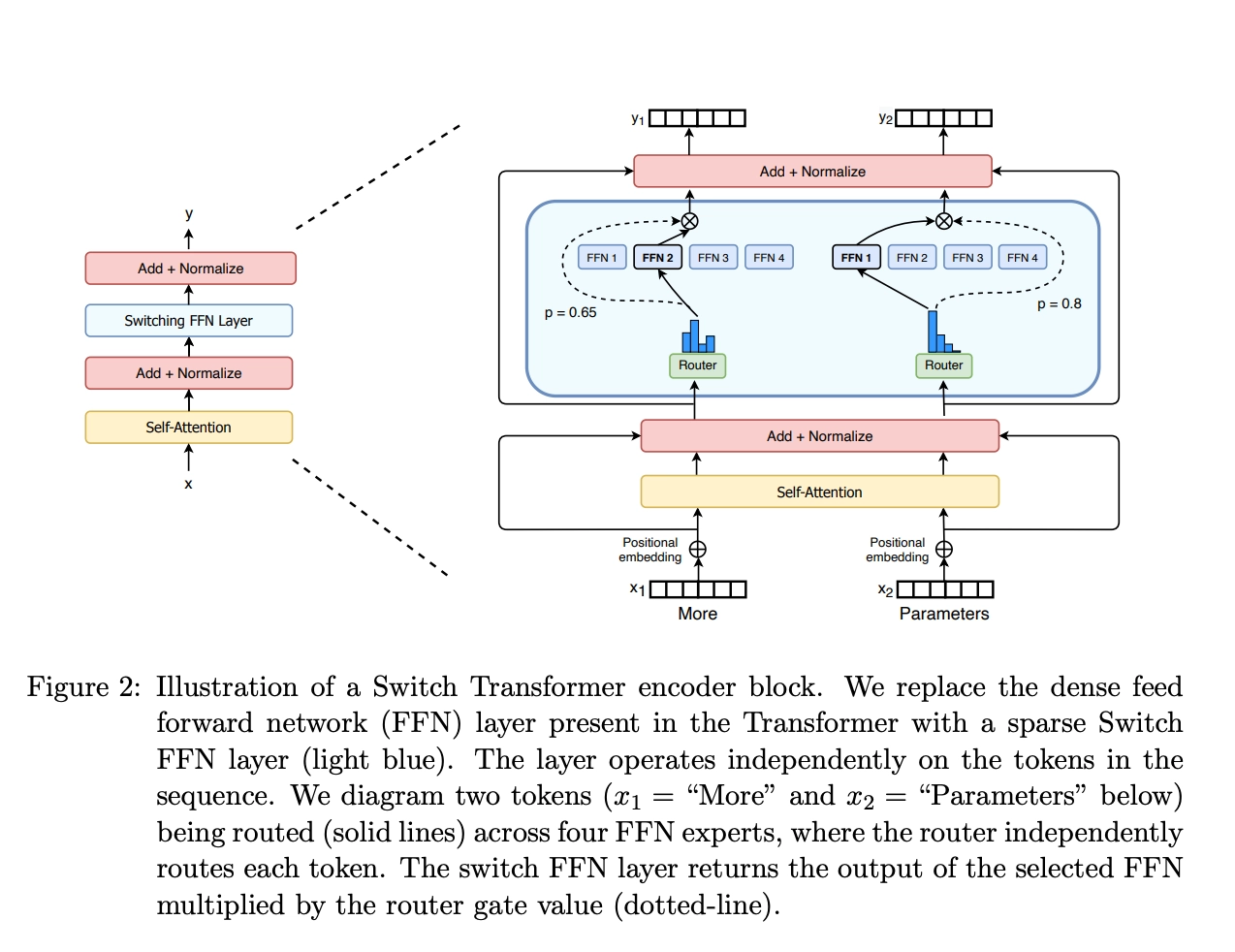
简短总结 混合专家模型 (MoEs): 与稠密模型相比, 预训练速度更快 与具有相同参数数量的模型相比,具有更快的 推理速度 需要 大量显存 ,因为所有专家系统都需要加载到内存中 在 微调方面存在诸多挑战 ,但 近期的研究 表明,对混合专家模型进行 指令调优具有很大的潜力 。 什么是混合专家模型? 模型规模是提升模型性能的关键因素之一。在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。 混合专家模型 (MoE) 的一个显著优势是它们能够在远少于稠密模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。 那么,究竟什么是一个混合专家模型 (MoE) 呢?作为一种基于 Transformer 架构的模型,混合专家模型主要由两个关键部分组成: 稀疏 MoE 层 : 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”(例如 8...