补充知识 表示学习 (Representation Learning): 学习数据的表征,以便在构建分类器或其他预测器时更容易提取有用的信息 ,无监督学习也属于表示学习。 互信息 (Mutual Information):表示两个变量 \(X\) 和 \(Y\) 之间的关系,定义为: \[I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x|y)}{p(x)}\] 对比损失(contrastive loss) :计算成对样本的匹配程度,主要用于降维中。计算公式为: \[L=\frac{1}{2N}\sum_{n-1}^N[yd^2+(1-y)max(margin-d, 0)^2]\] 其中, \(d=\sqrt{(a_n-b_n)^2}\) 为两个样本的欧式距离, \(y=\{0,1\}\) 代表两个样本的匹配程度, \(margin\) 代表设定的阈值。这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。当 \( y=1\) (即样本相似)时,损失函数只剩下 \(∑d^2\)...
Self-Supervised
2026-04-15
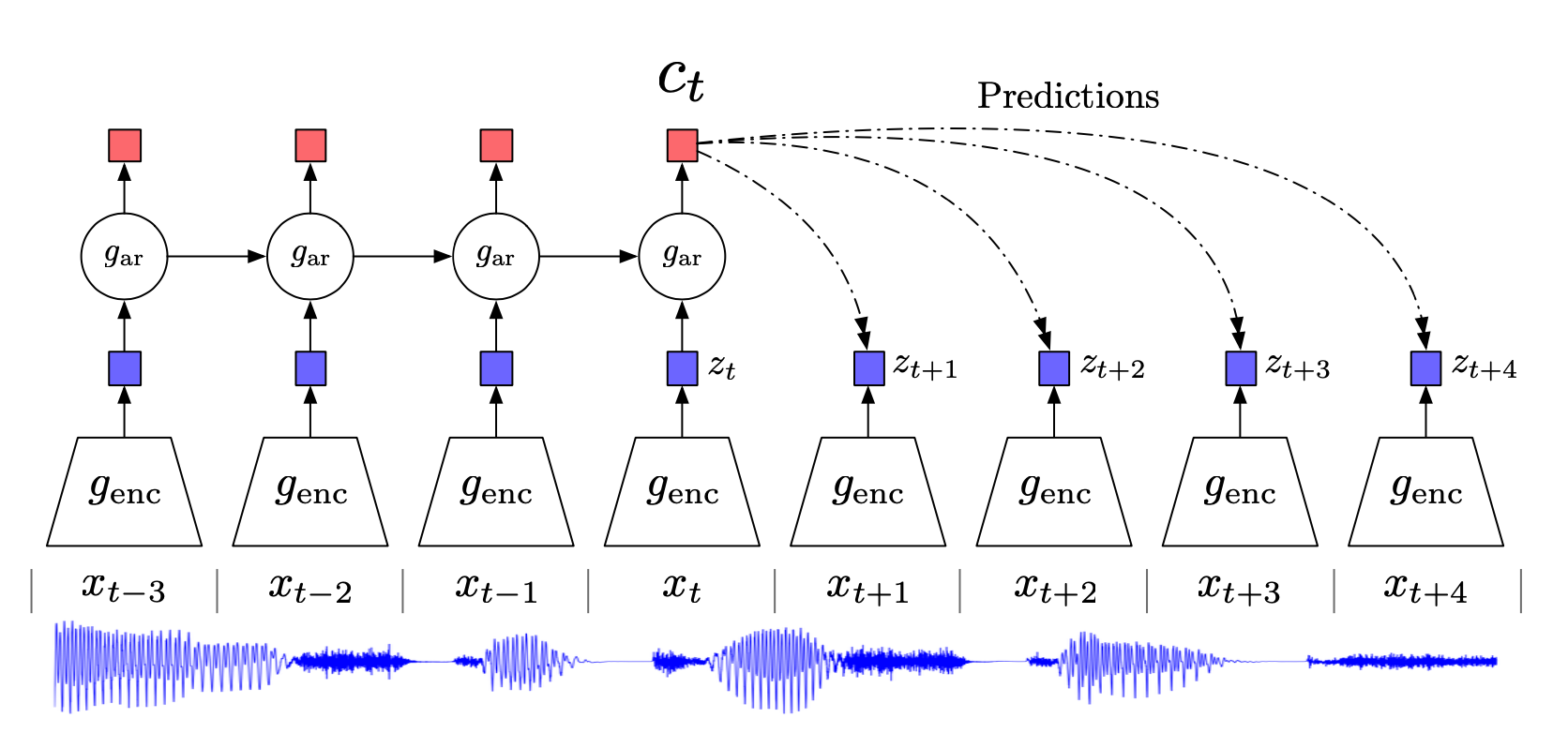
相关内容 自监督学习 (Self-supervised):属于无监督学习,其核心是自动为数据打标签(伪标签或其他角度的可信标签,包括图像的旋转、分块等等),通过让网络按照既定的规则,对数据打出正确的标签来更好地进行特征表示,从而应用于各种下游任务。 互信息 (Mutual Information):表示两个变量 \(X\) 和 \(Y\) 之间的关系,定义为: \[I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x|y)}{p(x)}\] 噪声对抗估计 (Noise Contrastive Estimation, NCE):在NLP任务中一种降低计算复杂度的方法,将语言模型估计问题简化为一个二分类问题。 Introduction 无监督学习一个重要的问题就是学习有用的 representation,本文的目的就是训练一个 representation learning 函数(即编码器encoder) ,其通过最大编码器输入和输出之间的互信息(MI)来学习对下游任务有用的 representation,而互信息可以通过 MINE...
Self-Supervised
2026-04-15
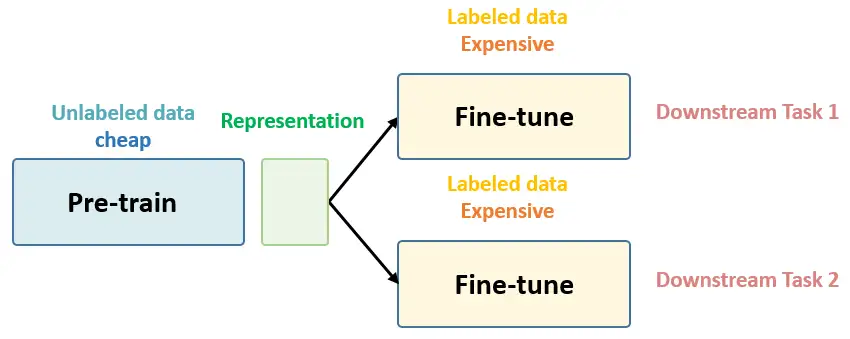
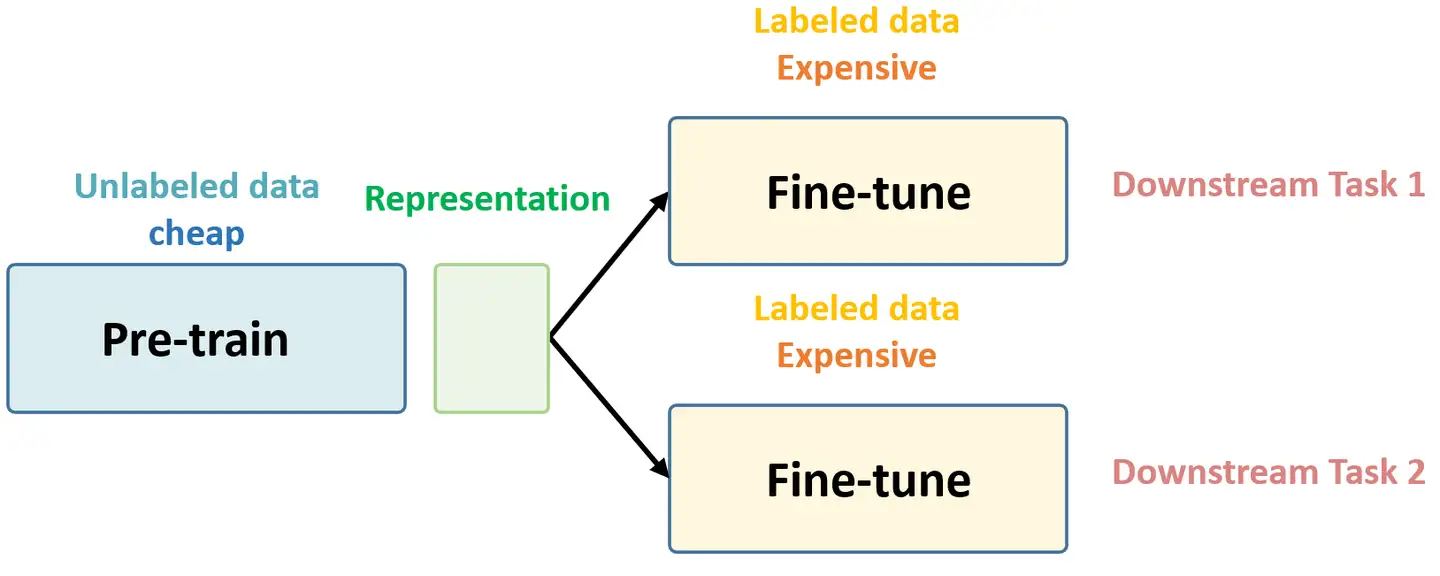
总结下 Self-Supervised Learning 的方法,用 4 个英文单词概括一下就是: Unsupervised Pre-train, Supervised Fine-tune. 在预训练阶段我们使用 无标签的数据集 (unlabeled data) ,因为有标签的数据集 很贵 ,打标签得要多少人工劳力去标注,那成本是相当高的,所以这玩意太贵。相反,无标签的数据集网上随便到处爬,它 便宜 。在训练模型参数的时候,我们不追求把这个参数用带标签数据从 初始化的一张白纸 给一步训练到位,原因就是数据集太贵。于是 Self-Supervised Learning 就想先把参数从 一张白纸 训练到 初步成型 ,再从 初步成型 训练到 完全成型 。注意这是2个阶段。这个 训练到初步成型的东西 ,我们把它叫做 Visual Representation 。预训练模型的时候,就是模型参数从 一张白纸 到 初步成型 的这个过程,还是用无标签数据集。等我把模型参数训练个八九不离十,这时候再根据你 下游任务 (Downstream Tasks) 的不同去用带标签的数据集把参数训练到 完全成型...
Self-Supervised
2026-04-15
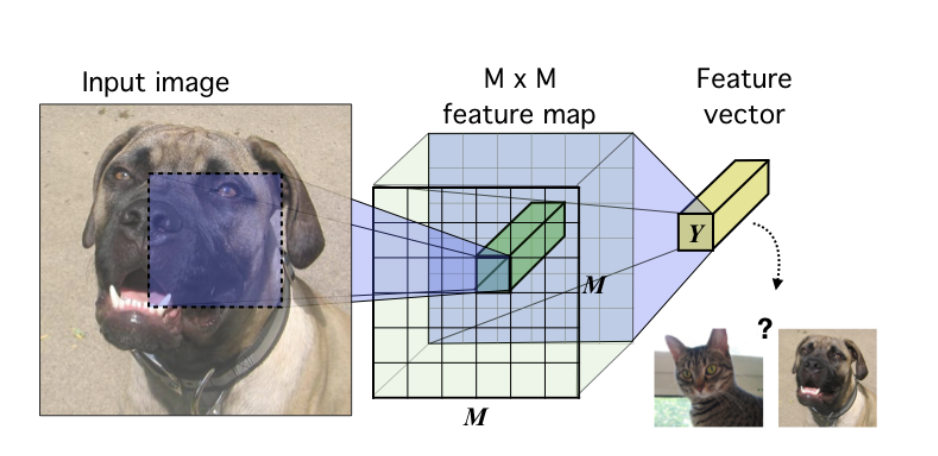
Self-Supervised Learning ,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种 通用的特征表达 用于 下游任务 (Downstream Tasks) 。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。 总结下 Self-Supervised Learning 的方法,用 4 个英文单词概括一下就是: Unsupervised Pre-train, Supervised Fine-tune. 这段话先放在这里,可能你现在还不一定完全理解,后面还会再次提到它。 在预训练阶段我们使用 无标签的数据集 (unlabeled data) ,因为有标签的数据集 很贵...
Self-Supervised
2026-04-15

如果把 近几年对比学习在视觉领域有代表性的工作做一下总结,那么对比学习的发展历程大概可以分为四个阶段: 百花齐放 这个阶段代表性工作有InstDisc(instance discrimination,)、CPC、CMC等。在这个阶段中,方法、模型、目标函数、代理任务都还没有统一,所以说是一个百花齐放的时代 CV双雄 代表作有MoCo v1、SimCLR v1、MoCo v2、SimCLR v2;CPC、CMC的延伸工作、SwAV等。这个阶段发展非常迅速,有的工作间隔甚至不到一个月,ImageNet上的成绩基本上每个月都在被刷新。 不用负样本 BYOL及其改进工作、SimSiam(CNN在对比学习中的总结性工作) transformer MoCo v3、DINO。这个阶段,无论是对比学习还是最新的掩码学习,都是用Vision Transformer做的。 第一阶段:百花齐放(2018-2019Mid) InstDisc(instance discrimination) 这篇文章提出了个体判别任务(代理任务)以及 memory bank ,非常经典,后人给它的方法起名为InstDisc。...
Computer Vision
2026-04-15

Introduction Inception 在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图: 于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。 Point-wise Conv 为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 \(1\times 1\) 卷积核,这就形成了 Inception V1 的最终网络结构,如下图。 这个 \(1\times1 \) 卷积就是 Pointwise Convolution ,简称 PW。利用它的目的主要是为了减少维度,还用于引入更多的非线性。 我们来简单计算下:假定上一层输出的 feature map 维度为 \(100\times 100 \times 128\) ,经过256个大小为 \(5\times5 \) 的卷积后,输出的 feature map...
Computer Vision
2026-04-15
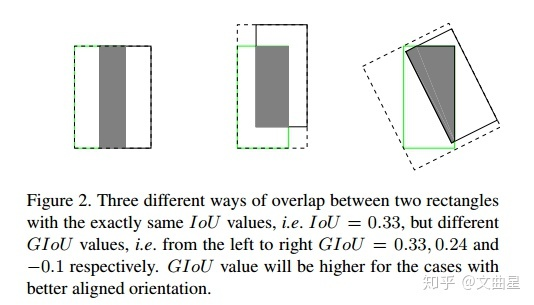
IOU(Intersection over Union) 特性(优点) IoU就是我们所说的 交并比 ,是目标检测中最常用的指标,在anchor-based的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和ground-truth的距离。 \[IoU = \frac{|A \cap B|}{|A \cup B|}
\] 可以说 它可以反映预测检测框与真实检测框的检测效果。 还有一个很好的特性就是 尺度不变性 ,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。 (满足非负性;同一性;对称性;三角不等性) import numpy as np
def Iou(box1, box2, wh=False):
if wh == False:
xmin1, ymin1, xmax1, ymax1 = box1
xmin2, ymin2, xmax2, ymax2 = box2
else:
xmin1, ymin1 =...
Computer Vision
2026-04-15

过程: 根据分类概率从小到大排序ABCDEF 从最大概率F开始,F与A~E的IOU是否大于阈值 大于的扔掉,从剩下的当中继续重复2~3 import numpy as np
def nms(bbox, scores, Nt):
if len(bbox) == 0:
return []
bboxes = np.array(bbox)
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
area = (x2 - x1 + 1) * (y2 - y1 + 1)
order = np.argsort(scores)
res = []
while order.size > 0:
index = order[-1]
res.append(bboxes[index])
x11 = np.maximum(x1[index], x1[order[:-1]])
...
Computer Vision
2026-04-15
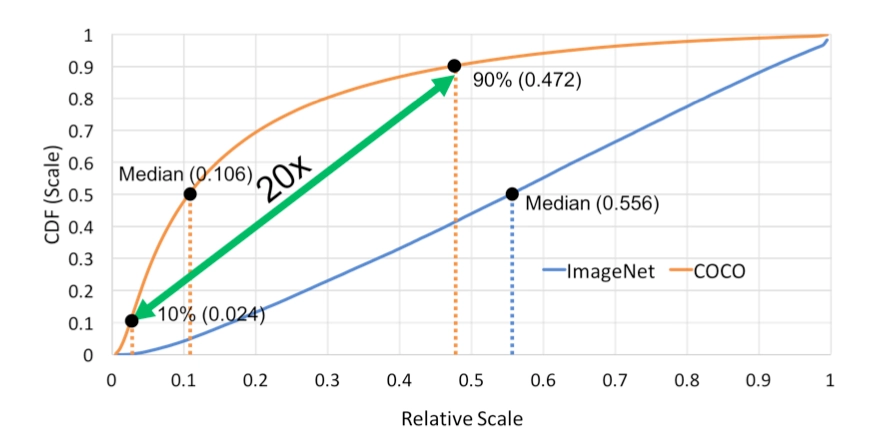
传统的图像金字塔 最开始在深度学习方法流行之前,对于不同尺度的目标,大家普遍使用将原图构建出不同分辨率的图像金字塔,再对每层金字塔用固定输入分辨率的分类器在该层滑动来检测目标,以求在金字塔底部检测出小目标;或者只用一个原图,在原图上, 用不同分辨率的分类器来检测目标,以求在比较小的窗口分类器中检测到小目标。 经典的 基于简单矩形特征(Haar)+级联Adaboost与Hog特征+SVM的DPM目标识别框架,均使用图像金字塔的方式处理多尺度目标 ,早期的CNN目标识别框架同样采用该方式,但对图像金字塔中的每一层分别进行CNN提取特征,耗时与内存消耗均无法满足需求。但 该方式毫无疑问仍然是最优的。 值得一提的是,其实目前大多数深度学习算法提交结果进行排名的时候,大多使用 多尺度测试 。同时类似于SNIP使用多尺度训练,均是图像金字塔的多尺度处理。 SNIP 图像分类算法,比如ResNeXt-101 32 × 48d网络结构,在Imagenet数据集上的Top5准确率已经98%左右,Top1为85%。对于图像检测算法,最好的模型在coco数据集上的效果 \(AP_{50}\)...