Computer Vision
2026-04-15
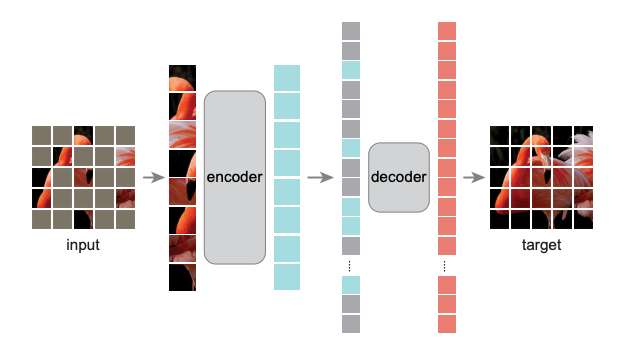
导言 自监督学习(Self-Supervised Learning)能利用大量无标注的数据进行表征学习,然后在特定下游任务上对参数进行微调。通过这样的方式,能够在较少有标注数据上取得优于有监督学习方法的精度。近年来,自监督学习受到了越来越多的关注,如Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。在CV领域涌现了如SwAV、MOCO、DINO、MoBY等一系列工作。MAE是kaiming继MOCO之后在自监督学习领域的又一力作。首先,本文会对MAE进行解读,然后基于EasyCV库的精度复现过程及其中遇到的一些问题作出解答。 概述 MAE的做法很简单:随机mask掉图片中的一些patch,然后通过模型去重建这些丢失的区域。包括两个核心的设计:1.非对称编码-解码结构 2.用较高的掩码率(75%)。通过这两个设计MAE在预训练过程中可以取得3倍以上的训练速度和更高的精度,如ViT-Huge能够通过ImageNet-1K数据上取得87.8%的准确率。 模型拆解...






