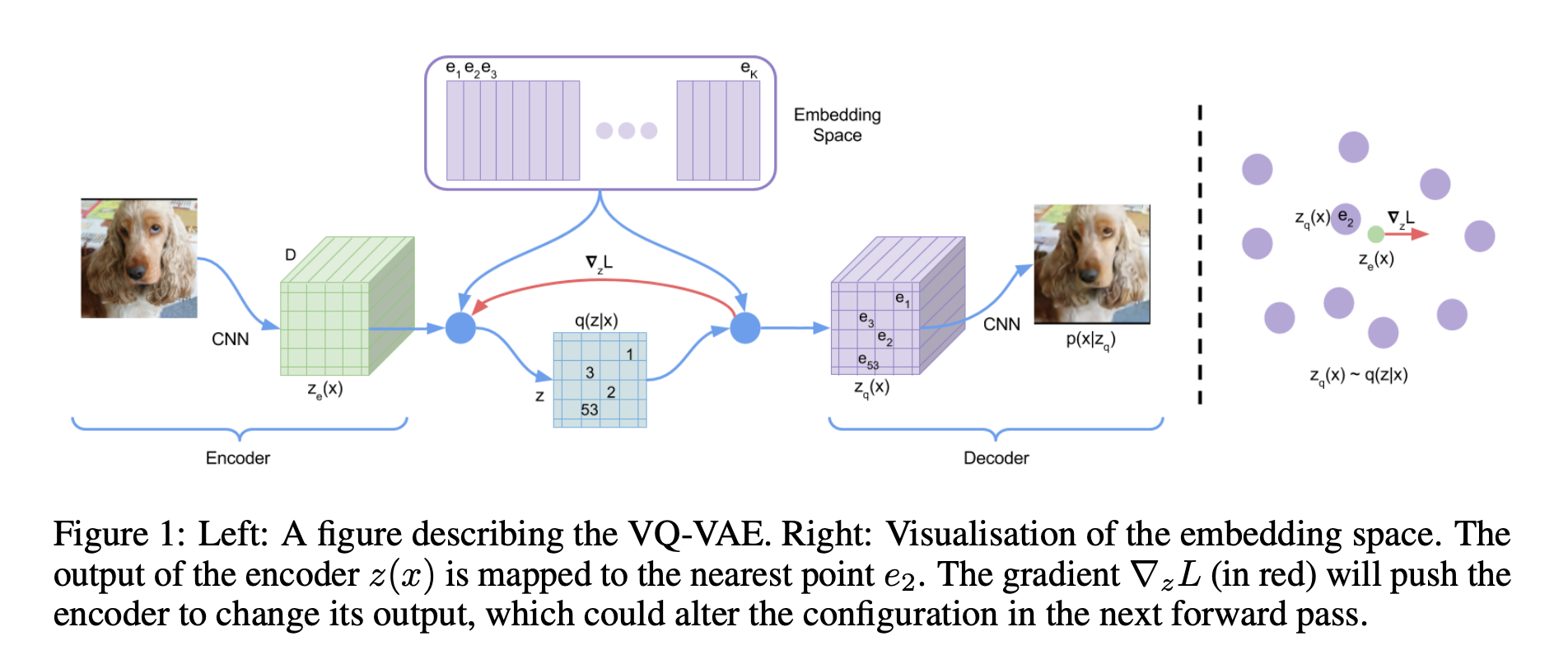
Generative Model
2026-04-15

- SMLD 和 DDPM 中使用的噪声扰动可以看作是两个不同 SDE 的离散化 - 扩散模型和评分模型在连续时间极限下完全等价,也就是说将有限次数的加噪过程推广到无穷次, 也就是推广到连续的情况下,可以得到一个更加一般的扩散过程,这个过程可以用SDE来表示,求解更加方便 - 两种方法的目标函数可以互相转换 随机微分 在DDPM中,扩散过程被划分为了固定的T步,还是用DDPM中的类比来说,就是“拆楼”和“建楼”都被事先划分为了T步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。 为此,我们用下述SDE描述前向过程(“拆楼”): \[d\boldsymbol{x} = \boldsymbol{f}_t(\boldsymbol{x}) dt + g_t d\boldsymbol{w}\tag{1}\]...