Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\end{equation}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times...
NLP
2026-04-15

概述 本文模型脉络图 本文介绍一个比较有意思的高效Transformer工作——来自Google的 《Transformer Quality in Linear Time》 , 什么样的结果值得我们用“惊喜”来形容?有没有言过其实?我们不妨先来看看论文做到了什么: 提出了一种新的Transformer变体,它依然具有二次的复杂度,但是相比标准的Transformer,它有着更快的速度、更低的显存占用以及更好的效果; 提出一种新的线性化Transformer方案,它不但提升了原有线性Attention的效果,还保持了做Decoder的可能性,并且做Decoder时还能保持高效的训练并行性。 说实话,笔者觉得做到以上任意一点都是非常难得的,而这篇论文一下子做到了两点,所以我愿意用“惊喜满满”来形容它。更重要的是,论文的改进总的来说还是比较自然和优雅的,不像很多类似工作一样显得很生硬。此外,笔者自己也做了简单的复现实验,结果显示论文的可复现性应该是蛮好的,所以真的有种“Transformer危矣”的感觉了。 门控注意(Gated Attention Unit)...

论文地址: https://arxiv.org/pdf/2107.11291 代码地址: https://github.com/Jeff-sjtu/res-loglikelihood-regression 前言 一般来说, 我们可以把姿态估计任务分成两个流派:Heatmap-based和Regression-based。 其主要区别在于监督信息的不同,Heatmap-based方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或soft-argmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression-based方法则非常简单粗暴,直接监督模型学习坐标值,计算坐标值的L1或L2...
NLP
2026-04-15

概述 众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是 \(\mathcal{O}(n^2)\) 级别的, \(n\) 是序列长度,所以当 \(n\) 比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到 \(\mathcal{O}(n\log n)\) 甚至 \(\mathcal{O}(n)\) 。 改变这一复杂度的思路主要有两种: 一是走稀疏化的思路,比如OpenAI的 Sparse Attention ,通过“只保留小区域内的数值、强制让大部分注意力为零”的方式,来减少Attention的计算量。经过特殊设计之后,Attention矩阵的大部分元素都是0,因此理论上它也能节省显存占用量和计算量。后续类似工作还有 《Explicit Sparse Transformer: Concentrated Attention Through Explicit...
Computer Vision
2026-04-15

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zero-shot 和 few-shot能力,结合prompt engineering和fine tuning等技术可以将基座模型应用在各种下游任务中并实现惊人的效果。 SAM就是想构建一个这样的图像分割基座模型,即使是一个未见过的数据集,模型也能自动或半自动(基于prompt)地完成下游的分割任务。为了实现这个目标,SAM定义了一种可提示化的分割任务(promptable...
NLP
2026-04-15
问题引入 前几天在训练一个新的Transformer模型的时候,发现怎么训都不收敛了。经过一番debug,发现是在做Self Attention的时候 \(\boldsymbol{Q}\boldsymbol{K}^{\top}\) 之后忘记除以 \(\sqrt{d}\) 了,于是重新温习了一下为什么除以 \(\sqrt{d}\) 如此重要的原因。当然,Google的T5确实是没有除以 \(\sqrt{d}\) 的,但它依然能够正常收敛,那是因为它在初始化策略上做了些调整,所以这个事情还跟初始化有关。 藉着这个机会,本文跟大家一起梳理一下模型的初始化、参数化和标准化等内容,相关讨论将主要以Transformer为心中展开。 参数初始化 采样分布 初始化自然是随机采样的的,所以这里先介绍一下常用的采样分布。一般情况下,我们都是从指定均值和方差的随机分布中进行采样来初始化。其中常用的随机分布有三个:正态分布(Normal)、均匀分布(Uniform)和截尾正态分布(Truncated Normal)。 显然,正态分布和均匀分布都是很常见的分布。其中正态分布通常记为...
NLP
2026-04-15

这篇文章主要去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。 问题定义 顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即“Train Short, Test Long”。那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列Loss或者PPL不会爆炸,更加符合实践的评测则是输入足够长的Context,让模型去预测答案,然后跟真实答案做对比,算BLEU、ROUGE等, LongBench 就是就属于这类榜单。 但要注意的是,长度外推应当不以牺牲远程依赖为代价——否则考虑长度外推就没有意义了,倒不如直接截断文本——这意味着通过显式地截断远程依赖的方案都需要谨慎选择,比如ALIBI,还有带显式Decay的 线性RNN ,这些方案当序列长度足够大时都表现为局部注意力,即便有可能实现长度外推,也会有远程依赖不足的风险,需要根据自己的场景斟酌使用。 如何判断在长度外推的同时有没有损失远程依赖呢?比较严谨的是像 ReRoPE...
Computer Vision
2026-04-15
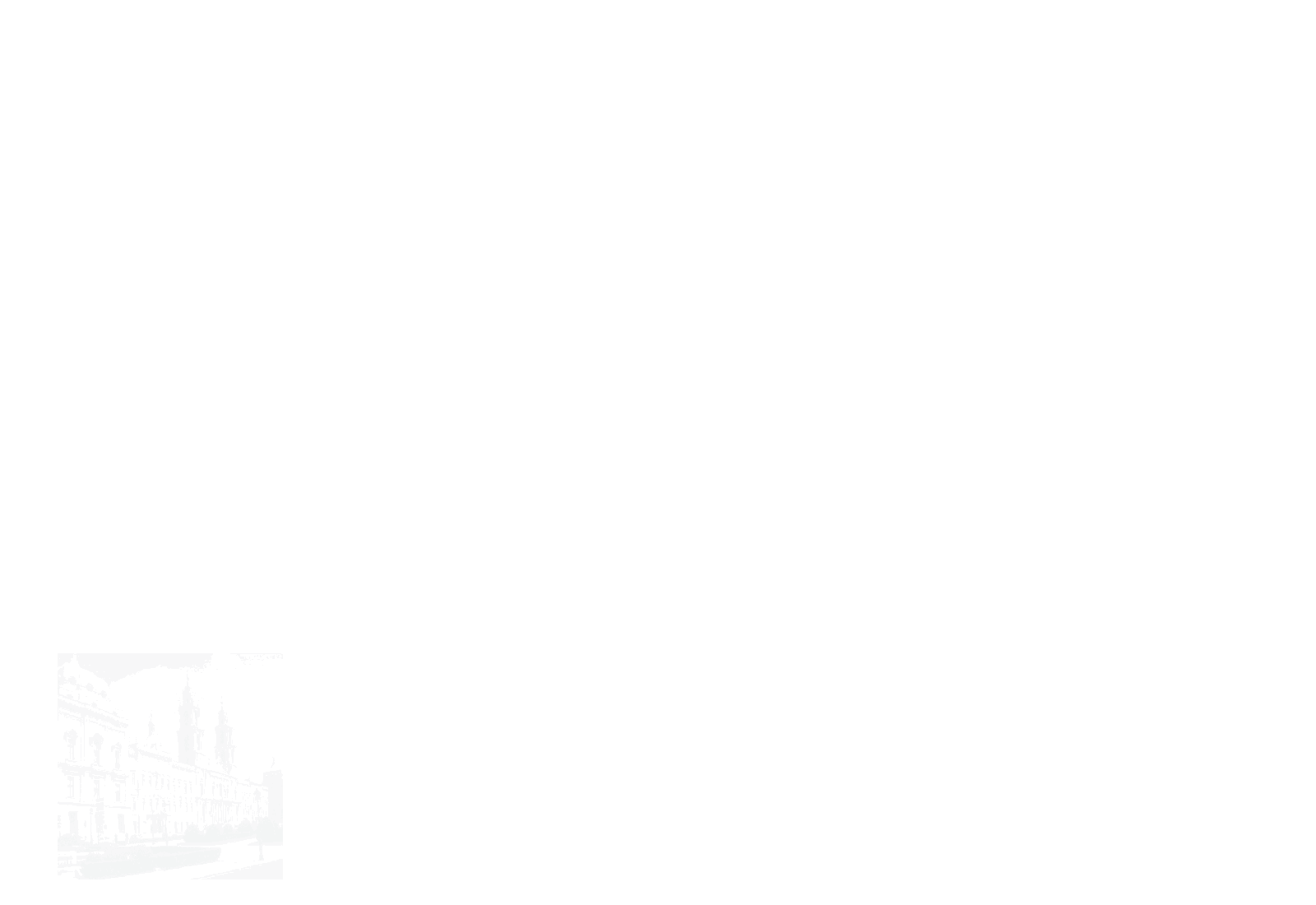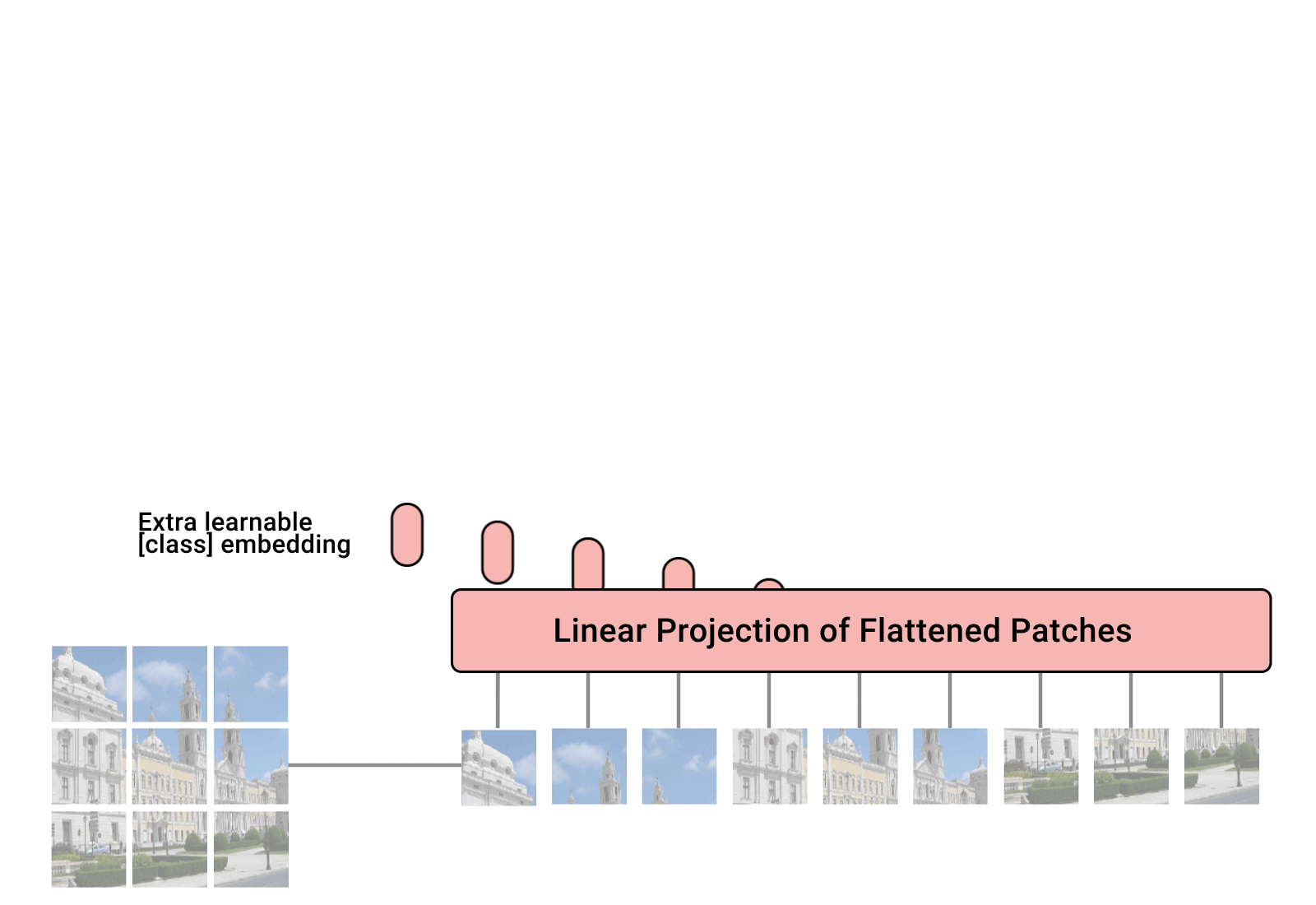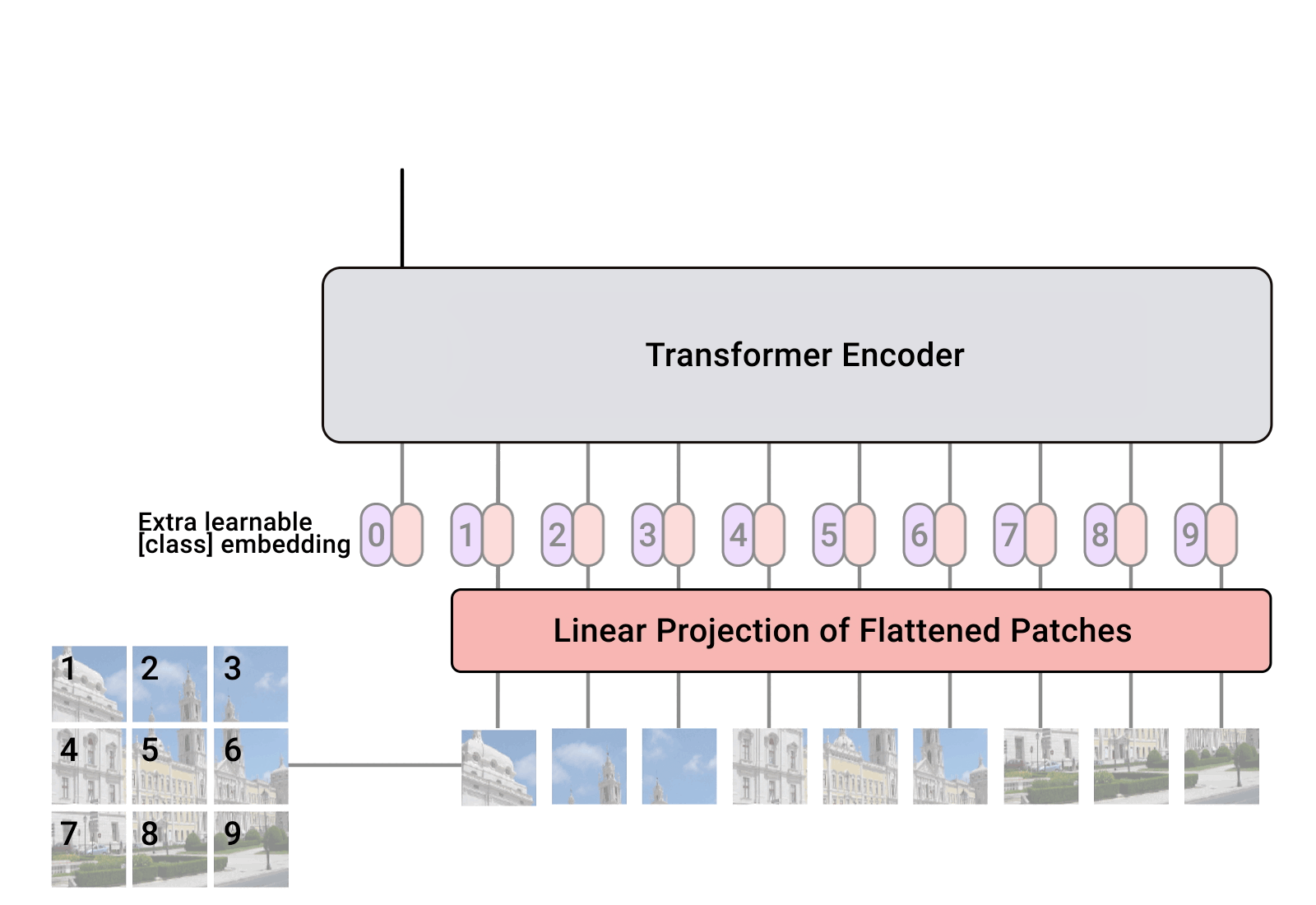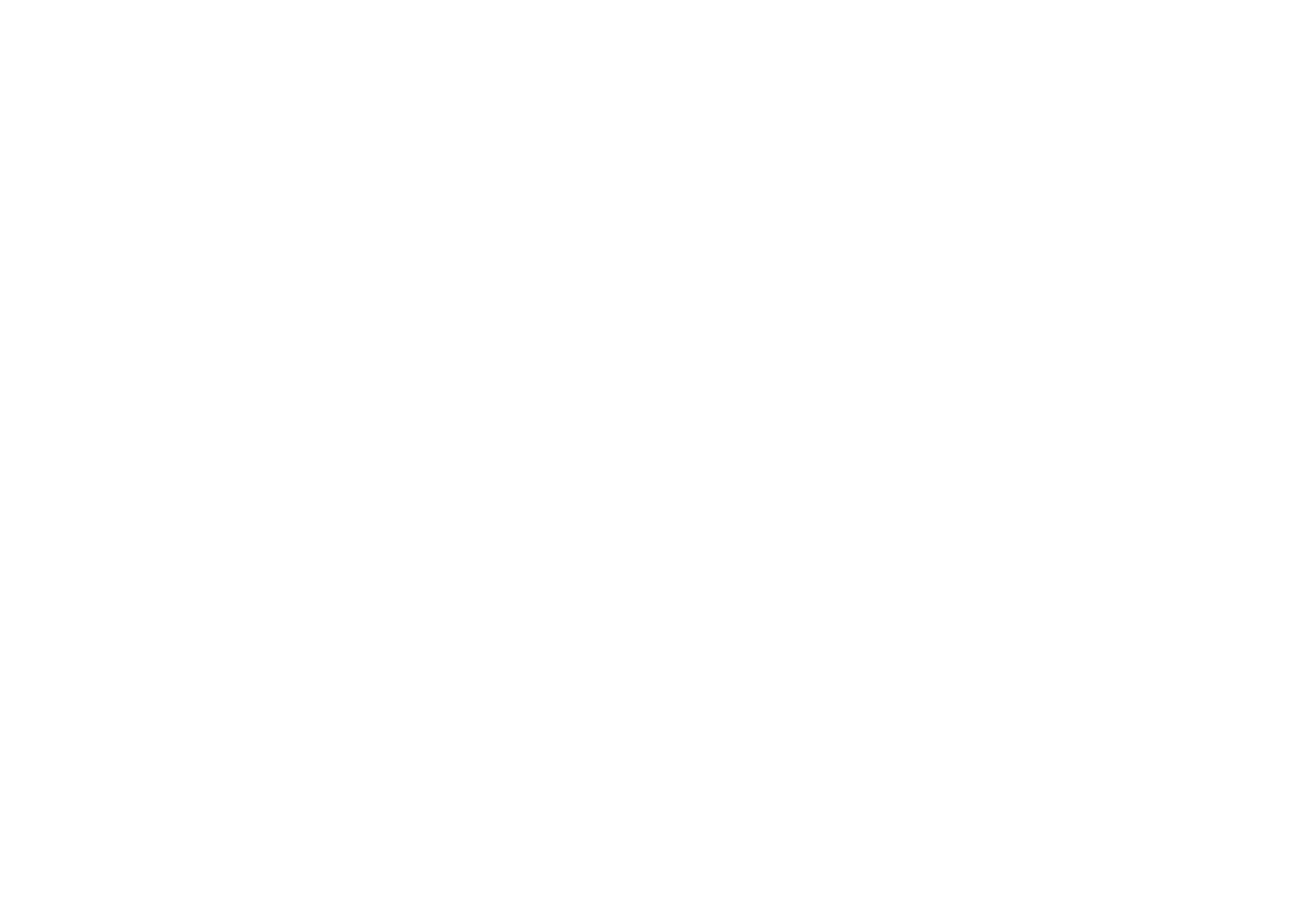
概述 在计算机视觉领域(CV),对视觉特征的理解CNN是长期处于主导地位的。而在NLP领域,Transformer框架的巨大成功,也激发了不少研究者探索将Transformer用于计算机视觉任务。ViT(Vision Transformer)的出现标志着在CV领域Transformer架构迈出了重要的一步。尤其在当前结合LLM的多模态探索上(MM-LLM),都是以LLM大语言模型为骨干架构的模型,多种模态的信息需要先做token化处理,再输入到LLM模型。ViT天然具有序列化特征的建模能力,自然在MM-LLM探索中大放异彩~ ViT在多模态模型中的角色类似于自然语言建模中的Tokenizer组件,对图像进行视觉特征编码,产出图像的序列特征。只不过ViT的编码过程本身也是采用了Transformer的模型结构。 本文主要结合几篇paper和源码讲讲ViT和针对ViT的一些优化方法~ ViT(Vision Transformer)...
Large Model
2026-04-15

比起两年前,NLG任务已经得到了非常有效的发展,transformers模块的使用广泛程度也达到前所未有的程度。在模型推理预测时,一个核心的语句就是 model.generate() ,本文就来详细介绍一下generate方法是如何运作的。在生成的过程中,包含了诸多生成策略,本文将以最常用的beam search为例,尽可能详细地展开介绍。 随着各种LLM的出现,transformers中与generate相关的代码发生了一些变化,主要区别在于: generate的源码位置发生了改变; generate方法中,采用一个 generation_config 参数来管理生成相关的各种配置,并优化了逻辑,使得逻辑更加清晰。 generate的代码位置 在之前版本的transformers中(transformers~=4.9),generate方法位于 transformers.generation_utils.py ,这个方法是 GenerationMixin 类的一个方法。 而在新版本的transformers中(transformers~=4.42),generate方法被转移到了...
NLP
2026-04-15
不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择: 想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法; 想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。 虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。 绝对位置编码 形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第 𝑘 个向量 \(𝑥_𝑘\) 中加入位置向量 \(𝑝_𝑘\) 变为 \(\boldsymbol{x}_k + \boldsymbol{p}_k\) ,其中 \(...
NLP
2026-04-15

旋转式位置编码(ROPE) 原始的Sinusoidal位置编码总的感觉是一种“想要成为相对位置编码的绝对位置编码”。一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。由此可见,如果可以通过绝对位置编码的方式实现相对位置编码,那么就是“集各家之所长”、“鱼与熊掌兼得”了。Sinusoidal位置编码隐约做到了这一点,但并不够好。 本文将会介绍我们自研的Rotary Transformer(RoFormer)模型,它的主要改动是应用了笔者构思的“旋转式位置编码(Rotary Position Embedding,RoPE)”,这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。而也正因为这种设计,它还是目前唯一一种可用于线性Attention的相对位置编码。 RoFormer:https://github.com/ZhuiyiTechnology/roformer 基本思路 这里简要介绍过RoPE: Transformer位置编码...