
236. 二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百 度百科中最近公共祖先的定义为:“对于有根树 \(T\) 的两个节点 \(p\) 、 \(q\) ,最近公共祖先表示为一个节点 \(x\) ,满足 \(x\) 是 \(p\) 、 \(q \) 的祖先且 \(x\) 的深度尽可能大( 一个节点也可以是它自己的祖先 )。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root = [1,2], p = 1, q = 2
输出:1 提示: 树中节点数目在范围 [2, 10 5 ] 内。 -10 9 <= Node.val <= 10 9 所有 Node.val...
二叉树结构 class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None 递归 时间复杂度: \(O(n)\) , \(n\) 为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度: \(O(h)\) , \(h\) 为树的高度。最坏情况下需要空间 \(O(n)\) ,平均情况为 \(O(logn)\) 递归1: 二叉树遍历最易理解和实现版本 class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
# 前序递归
return [root.val] + self.preorderTraversal(root.left) + self.preorderTraversal(root.right)
...

48. 旋转图像 题目 给定一个 \(n × n\) 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。 请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]] 示例 2: 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]] 提示: n == matrix.length == matrix[i].length 1 <= n <= 20 -1000 <= matrix[i][j] <= 1000 题解 这是一个经典的矩阵操作问题。要在原地(In-place)将图像顺时针旋转 90 度,我们可以利用矩阵的几何性质。 最直观且易于实现的方法是将...
Large Model
2026-04-15

简介 该工作建立了一个 GCG(Grounded Conversation Generation ) 的数据集和对应多模态大模型,与之前的工作主要的区别在于针对输入图像,可以生成grounding pixel-level理解的语言对话,如下图示例所示: Model Automated Dataset Annotation Pipeline level 1: Object locatlization and attributes 1. Landmark Categorization 基于 LLaVA 模型对图像做场景的分类, 包含主要场景和细粒度场景。 就是对数据集整体做一个大的类别标签和子类别标签,做场景的划分 def get_main_prompt(model, conv_mode="llava_v1"):
options = ["Indoor scene", "Outdoor scene", "Transportation scene", "Sports and recreation scene"]
qs = (f"Categorize the image...
Deep Learning
2026-04-15
一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。 还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到 \(\text{argmax}\) 等操作),所以没法直接用。 这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀鸡”的方案; 另外一种是试图给正确率找一个光滑可导的近似公式 。本文就来探讨一下常见的不可导函数的光滑近似,有时候我们称之为“光滑化”,有时候我们也称之为“软化”。 max 后面谈到的大部分内容,基础点就是max操作的光滑近似,我们有:...
Deep Learning
2026-04-15

文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。 基本概念 重参数(Reparameterization) 实际上是处理如下期望形式的目标函数的一种技巧: \[L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\tag{1}\] 这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现( \(f(z)\) 对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于 \(z\) 的连续性,它对应不同的形式: \[\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\tag{2}\] 当然,离散情况下我们更喜欢将记号 \(z\) 换成 \(y\) 或者 \(c\) 。 为了最小化...
Large Model
2026-04-15

CLIP算法原理 CLIP 不预先定义图像和文本标签类别,直接利用从互联网爬取的 400 million 个image-text pair 进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉分类。简单的说,CLIP 无需利用 ImageNet 的数据和标签进行训练,就可以达到 ResNet50 在 ImageNet数据集上有监督训练的结果,所以叫做 Zero-shot。 CLIP(contrastive language-image pre-training)主要的贡献就是 利用无监督的文本信息,作为监督信号来学习视觉特征 。 CLIP 作者先是回顾了并总结了和上述相关的两条表征学习路线: 构建image和text的联系,比如利用已有的image-text pair数据集,从text中学习image的表征; 获取更多的数据(不要求高质量,也不要求full...
Large Model
2026-04-15

项目: https://llava-vl.github.io/ github: https://github.com/haotian-liu/LLaVA 一句话 优点 : 极大简化了VLM的训练方式:Pre-training + Instruction Tuning 训练量得到简化:1M量级数据+ 8卡A100 → 一天完成训练 LLaVA LLaVA是2023的连续工作,包含了LLaVA 1.0, 1.5, 1.6几个版本(后续会有更多),也是2023年多模态领域妥妥的顶流。发表9个月620的stars,GitHub超过12K的stars。 LLaVA它的网络结构简单、微调成本比较低,任何研究组、企业甚至个人都可以基于它构建自己的领域的多模态模型。 非常建议对多模态大模型感兴趣的朋友关注LLaVA这篇工作。 简介...
Large Model
2026-04-15

问题背景 首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗? 其实没那么简单。先看文本生成,事实上文本生成自始至终都只有一条主流路线,那就是语言模型,即建模条件概率 \(p(x_t|x_1,\cdots,x_{t-1})\) ,不论是最初的 n-gram语言模型,还是后来的Seq2Seq、GPT,都是这个条件概率的近似。也就是说,一直以来,人们对“实现文本生成需要往哪个方向走”是很明确的,只是背后所用的模型有所不同,比如LSTM、CNN、Attention乃至最近复兴的线性RNN等。所以, 文本生成确实可以All in Transformer来大力出奇迹,因为方向是标准的、清晰的。 然而,对于图像生成,并没有这样的“标准方向”。就本站所讨论过的图像生成模型,就有 VAE 、 GAN 、 Flow 、 Diffusion ,还有小众的 EBM...
Large Model
2026-04-15
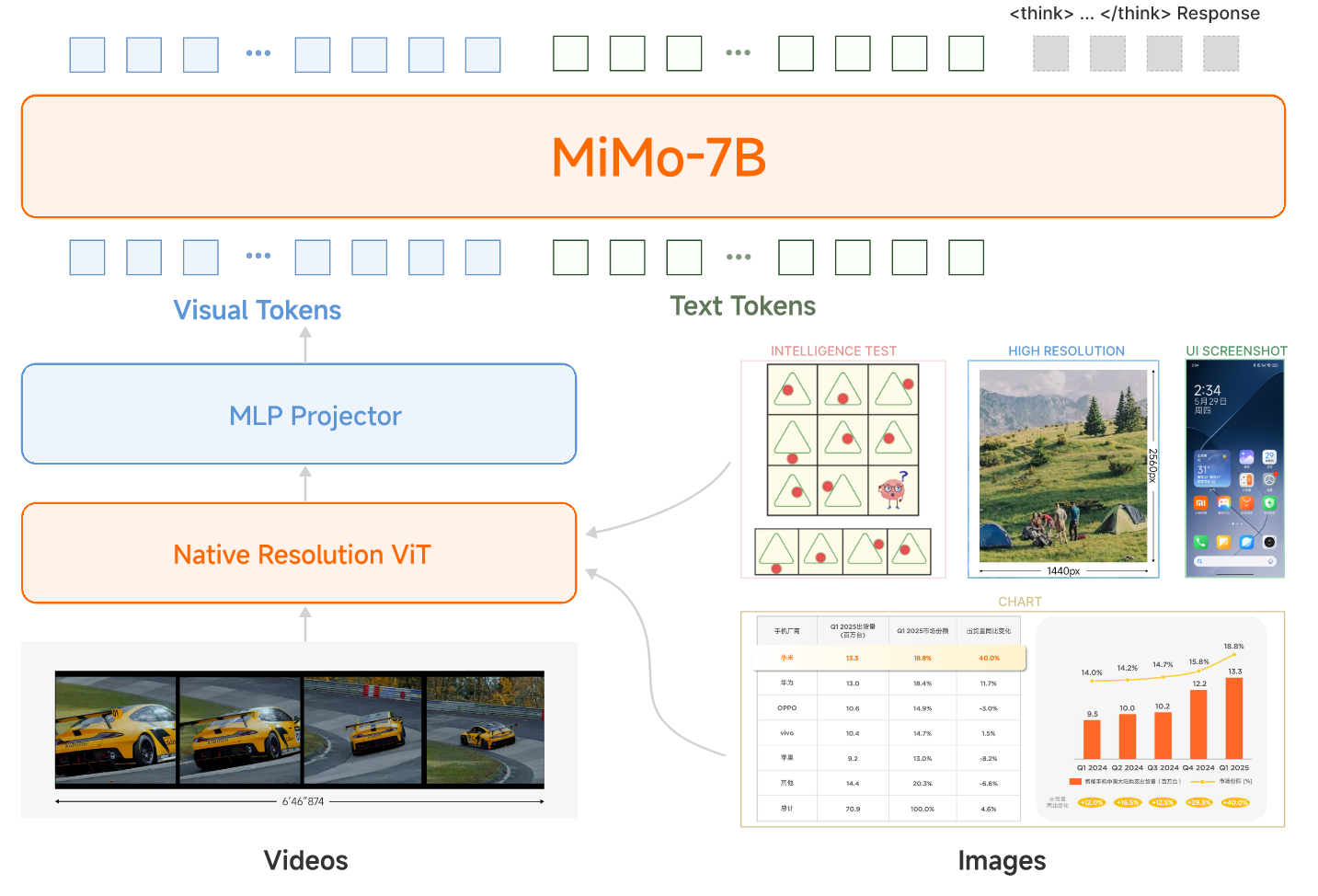
概述 小米团队近日发布了MIMO-VL-7B-SFT和MIMO-VL-7B-RL,这是两个强大的视觉语言模型,MIMO-VL-7B-RL在40个评估任务中的35个上优于QWEN2.5-VL-7B,对于GUI Grounding任务,它在OSWorld-G上设置了一个新标准,甚至超过了UI-TARS等专业模型。模型通过四个阶段的预训练(2.4T Token)与Mixed On-policy 强化(MORL)整合了多样化的奖励信号。 在文章中,作者提到了两个重要的发现: 从Pre-Traing 训练阶段中加入高质量且覆盖广的推理数据对于强化模型性能至关重要。 Mixed On-policy 强化学习进一步增强了模型的性能,同时实现了稳定的同时改进仍然在性能方面具有挑战性。 Pre-Training 模型结构 整个模型还是采用了VIT-MLP-LLM的结构,具体来说,视觉模型采用了Qwen2.5-VL中的视觉encoder,LLM采用了自家的语言模型MiMo-7B-Base。 整个Pretraining采用了四个阶段的训练,每个阶段采用的数据,模型训练参数和模型参数如下面两表所示...
Large Model
2026-04-15
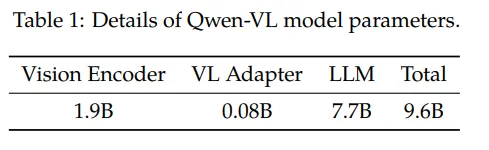
Qwen-VL系列 Qwen-VL 阿里巴巴的Qwen-VL是另一个比较经典的模型,十分值得作为案例介绍多模态大模型的训练要点。Qwen-VL使用Qwen-7B LLM作为语言模型基座,Openclip预训练的ViT-bigG作为视觉特征Encoder,随机初始化的单层Cross-Attention模块作为视觉和自然语言的的Adapter,总参数大小约9.6B。 如下图,Qwen-VL的训练过程分为三个阶段: Stage1 为预训练,目标是使用大量的图文Pair对数据对齐视觉模块和LLM的特征,这个阶段冻结LLM模块的参数; Stage2 为多任务预训练,使用更高质量的图文多任务数据(主要来源自开源VL任务,部分自建数据集),更高的图片像素输入,全参数训练; Stage3 为指令微调阶段,这个阶段冻结视觉Encoder模块,使用的数据主要来自大模型Self-Instruction方式自动生成,目标是提升模型的指令遵循和多轮对话能力。...
Large Model
2026-04-15

简介 bagel-ai.org BAGEL 模型原生支持统一的多模态理解和生成,是一个 decoder-only 的模型,BAGEL 在包含文本、图像、视频和网络数据的大量多模态数据上进行了预训练,包括数万亿 tokens。尽管有一些研究尝试扩展其统一模型,但它们 主要仍然依赖于标准图像生成和理解任务中的图像-文本配对数据 进行训练。 然而,最近的研究发现,学术模型与 GPT-4o 和 Gemini 2.0 等 专有系统在统一多模态理解和生成方面存在显著差距 ,而这些专有系统的底层技术并未公开。作者认为,弥合这一差距的关键在于 使用精心构建的多模态交错数据进行规模化训练 。这种多模态交错数据 整合了文本、图像、视频和网络来源 。通过使用这种多样化的多模态交错数据进行扩展时,模型展现出 复杂的、新兴的多模态推理能力 。这种规模化不仅增强了核心的多模态理解和生成能力,还促进了 复杂的组合能力 ,例如自由形式的视觉操作和需要长上下文推理的多模态生成。 论文主要贡献: 数据策略创新,融合多源数据。包含: 架构设计理念,采用 Mixture-of-Transformer-Experts...