基本概念 方向导数:是一个数;反映的是 \(f(x,y)\) 在 \(P_0\) 点沿方向 \(v\) 的变化率。 偏导数:是多个数(每元有一个);是指多元函数沿坐标轴方向的 方向导数 ,因此二元函数就有两个偏导数。 偏导函数:是一个函数;是一个关于点的偏导数的函数。 梯度:是一个向量;每个元素为函数对一元变量的偏导数;它既有大小(其大小为最大方向导数),也有方向。 方向导数 反映的是 \(f(x,y)\) 在 \(P_0\) 点沿方向 \(v\) 的变化率。 例子如下: 题目 设二元函数 \( f(x, y) = x^2 + y^2\) ,分别计算此函数在点 \((1, 2)\) 沿方向 \(w=\{3, -4\}\) 与方向 \(u=\{1, 0\}\) 的方向导数。 解: 由于 \(w\) 不是单位向量,因此首先应对其进行单位化: \[v = w^0 = \frac{w}{|w|} = \left\{ \frac{3}{5}, -\frac{4}{5} \right\}\] 计算函数增量: \[\begin{aligned}
\therefore f(x_0 + tv_1,...
问题表示 有很多概率问题,尤其是独立重复实验问题,如果用生成函数的方法来做,会显得特别方便。本文要讲的“随机游走”问题便是其中一例,它又被形象地叫做“醉汉问题”,其本质上是一个二项分布,但是由于取了极限,出现了很多新的性质和应用。我们先考虑如下问题: 考虑实数轴上的一个粒子,在 \(t=0\) 时刻它位于原点,每过一秒,它要不向前移动一格( \(+1\) ),要不就向后移动一格( \(-1\) ),问 \(n\) 秒后它所处位置的概率分布。 不难发现,这个问题跟二项分布是雷同的。如果把这个粒子形象比喻成一个“喝醉酒的人”,那么上面的走法就类似于一个完全不省人事的醉汉走路问题了。(当然,醉汉是在三维空间走路的,这里简单起见,只描述了一维的。)这是一个独立重复实验,每秒的行走可用函数描述为 \(\frac{1}{2}(z+z^{-1})\) ,于是 \(n\) 秒后的运动分布情况可以用 \[\frac{1}{2^n}(z+z^{-1})^n\] 来描述, \(z^i(i=-n,-n+1,\dots,n-1,n)\) 的系数表示粒子位于 \(i\) 的概率。 💡...
Math
2026-04-15

引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 \(X\) ,其取值来自有限集合 \(\mathcal{X}\) 。我们的目标是估计 \(E[X]\) 。假设我们有一个独立同分布的样本序列 \(\{x_i\}_{i=1}^n\) ,那么 \(X\) 的期望值可以近似为: \[E[X] \approx \bar{x} = \frac{1}{n}\sum_{i=1}^n x_i\] 非增量方法与增量方法 非增量方法 :先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法 :定义 \[w_{k+1} = \frac{1}{k}\sum_{i=1}^k x_i, k = 1, 2, ...\] 可以推导出递归公式: \[{w}_{k + 1} =...
Generative Model
2026-04-15

简介 如果以概率的视角看待世界的生成模型。 在这样的世界观中,我们可以将任何类型的观察数据(例如 \(D\) )视为来自底层分布(例如 \( p_{data}\) )的有限样本集。 任何生成模型的目标都是在访问数据集 \(D\) 的情况下近似该数据分布。 如果我们能够学习到一个好的生成模型,我们可以将学习到的模型用于下游推理。 我们主要对数据分布的参数近似感兴趣,在一组有限的参数中,它总结了关于数据集 \(D\) 的所有信息。 与非参数模型相比,参数模型在处理大型数据集时能够更有效地扩展,但受限于可以表示的分布族。 在参数的设置中,我们可以将学习生成模型的任务视为在模型分布族中挑选参数,以最小化模型分布和数据分布之间的距离。 如上图,给定一个狗的图像数据集,我们的目标是学习模型族 \(M\) 中生成模型 θ 的参数,使得模型分布 \(p_θ\) 接近 \(p_{data}\) 上的数据分布。 在数学上,我们可以将我们的目标指定为以下优化问题: \[\mathop{min}\limits_{\theta\in M}d(p_\theta,p_{data})\] 其中, \(d()\)...
Computer Vision
2026-04-15

上图是Yolo v4中,对各种detector部件的总结:包含Input、backbone、neck、head、... Backbone 轻量级网络系列 Neck 例如:SPP 、 ASPP 、 RFB、 SAM 用来增加感受野 特征融合,主要是指不同输出层直接的特征融合,主要包括FPN、PAN、SFAM、ASFF和BiFPN。 结构 Path Aggregation Blcok Deformable Convolution系列 One stage Yolo系列 Focal Loss & RetinaNet Two-Stage Faster R-CNN R-FCN Anchor Free Anchor-Free Transformer DETR Problems 目标检测中的多尺度问题 NMS及其改进 IoU loss系列 目标检测中mAP计算

论文地址: https://arxiv.org/pdf/2107.11291 代码地址: https://github.com/Jeff-sjtu/res-loglikelihood-regression 前言 一般来说, 我们可以把姿态估计任务分成两个流派:Heatmap-based和Regression-based。 其主要区别在于监督信息的不同,Heatmap-based方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或soft-argmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression-based方法则非常简单粗暴,直接监督模型学习坐标值,计算坐标值的L1或L2...
NLP
2026-04-15
概述 HiPPO(High-order Polynomial Projection Operators)是目前大热的structured state space model (S4)及其后续工作的backbone. State space mode主要是控制学科里的内容,最近被引入深度学习领域来解决长距离依赖问题。长距离依赖建模的核心问题是如何通过有限的memory来尽可能记住之前所有的历史信息。当前的主流序列建模模型(即Transformer和RNN) 存在着普遍的遗忘问题 fixed-size context windows: Transformer的window size通常是有限的,一般来说quadratic的attention最多建模到大约10k的token就到计算极限了 vanishing gradient: RNN通过hidden state来存储历史信息,理论上能记住之前所有内容,但实际上的effective memory大概是<1k个token的level,可能的原因是gradient vanishing HiPPO 通过数学方法分析来得到closed-form...
Computer Vision
2026-04-15

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zero-shot 和 few-shot能力,结合prompt engineering和fine tuning等技术可以将基座模型应用在各种下游任务中并实现惊人的效果。 SAM就是想构建一个这样的图像分割基座模型,即使是一个未见过的数据集,模型也能自动或半自动(基于prompt)地完成下游的分割任务。为了实现这个目标,SAM定义了一种可提示化的分割任务(promptable...
Large Model
2026-04-15

引言 Structured Generation with LLM,是指 让LLM按照预先定义的schema,输出符合schema的结构化结果 。 常见的应用场景有: 数据处理 。主要功能为a -> b,即从源文本中 抽取/生成 符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等; Agent 。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参。 将 LLM 限制为始终生成符合特定模式的、有效的 JSON 或 YAML,是许多应用的关键功能。 Kor Kor ,一个 基于prompt的技术方案 ;Kor比较适合 数据处理 场景,且原理简单、易于理解,适合作为入门, 并且Kor适用于那些不支持function calling的比较旧的模型。 使用Kor进行structured generation的流程如下: 定义schema,包括结构、注释还有例子; Kor用特定的 prompt template ,将用户提供的schema和待处理的raw text,组装成prompt; 将prompt发送给LLM,借助其通用的In...
Large Model
2026-04-15

引言与背景 FlashAttention的关键创新在于使用类似于在线Softmax的思想来对自注意力计算进行分块(tiling),从而能够融合整个多头注意力层的计算,而无需访问GPU全局内存来存储中间的logits和注意力分数 在深度学习中,Transformer模型的自注意力机制是计算密集型操作。传统实现需要在GPU全局内存中存储大量中间结果,这导致: 内存瓶颈 :中间矩阵占用大量显存 I/O开销 :频繁的全局内存访问降低效率 扩展性限制 :难以处理超长序列 FlashAttention通过算法创新解决了这些问题。 Self-Atention 自注意力机制的计算可以总结为(为简化说明,忽略头数和批次维度,也省略注意力掩码和缩放因子 \(\frac{1}{\sqrt{D}}\) ): \[O = \text{softmax}(QK^T)V\] 其中: \(Q, K, V, O\) 都是形状为 \((L, D)\) 的二维矩阵 \(L\) 是序列长度 \(D\) 是每个头的维度(头维度) softmax应用于最后一个维度(列) 标准计算流程, 传统方法将自注意力计算分解为几个阶段:...
Computer Vision
2026-04-15
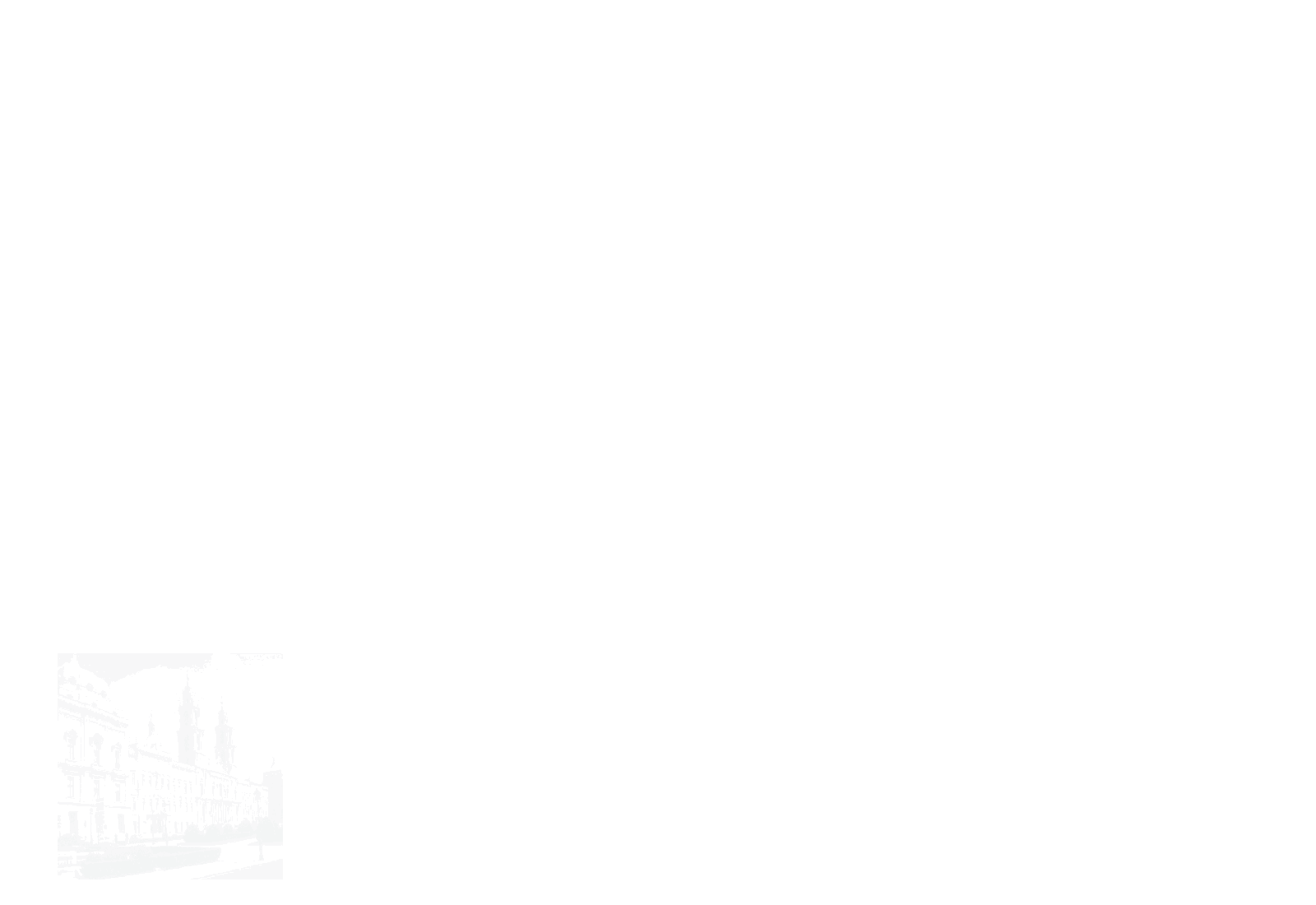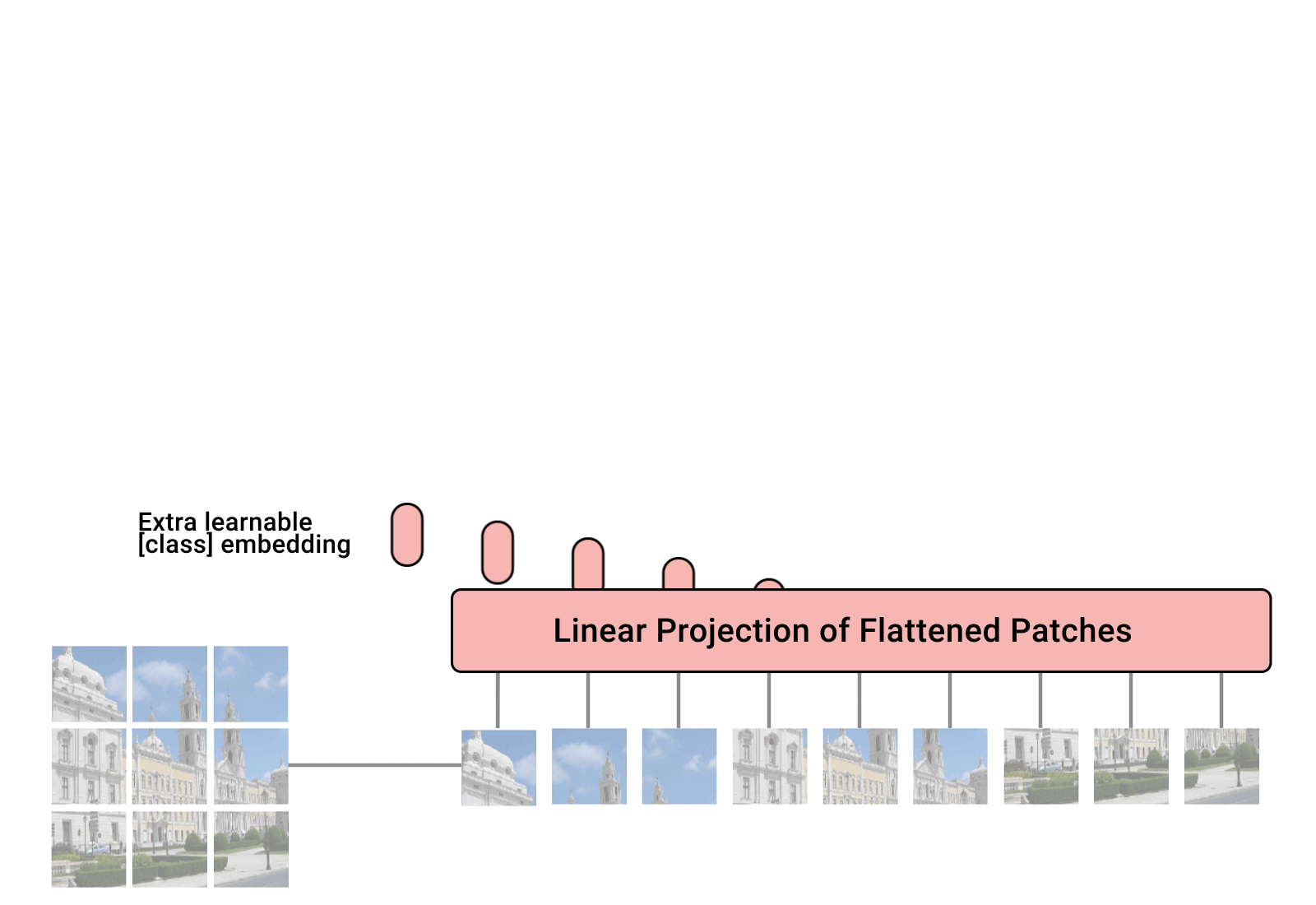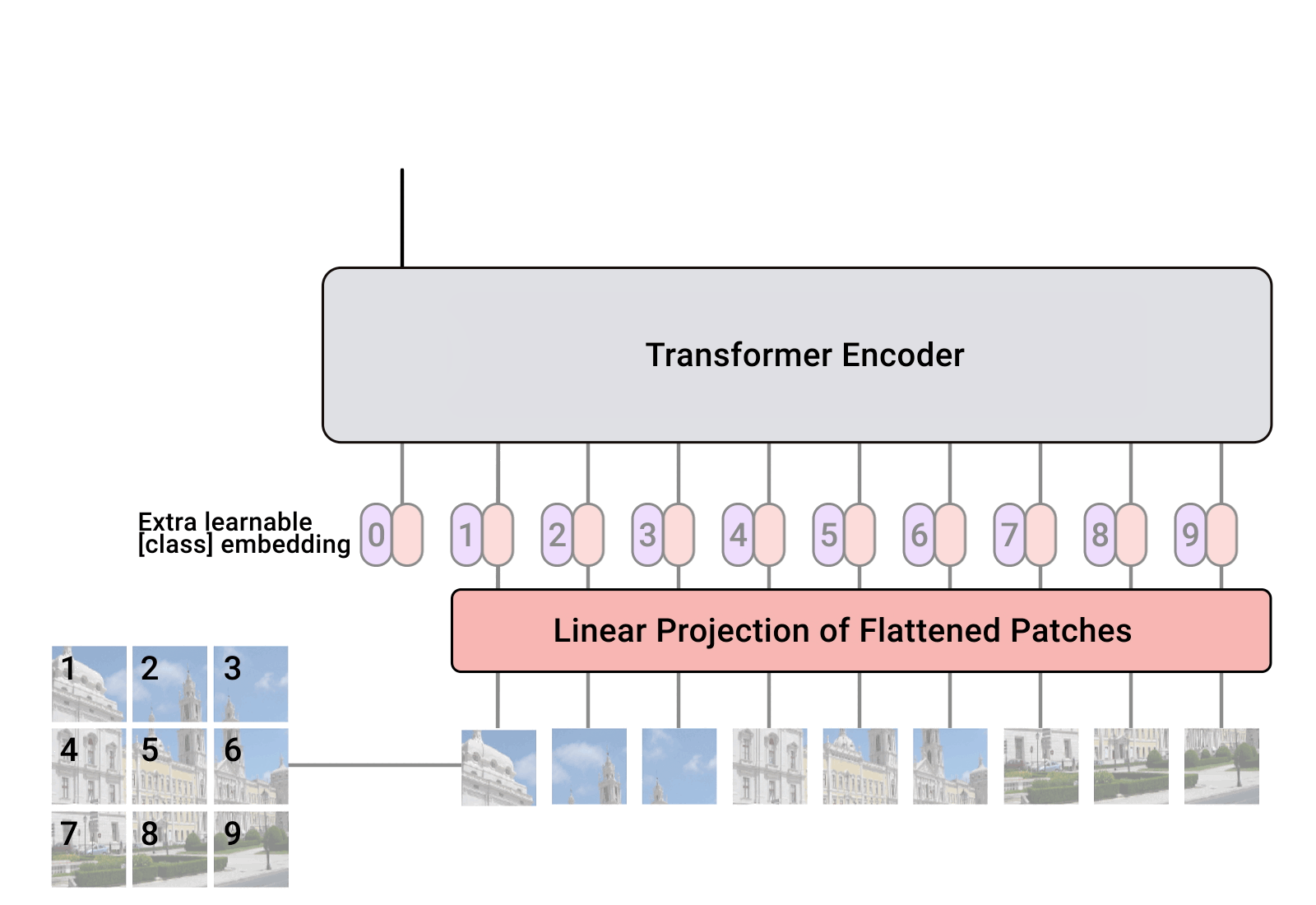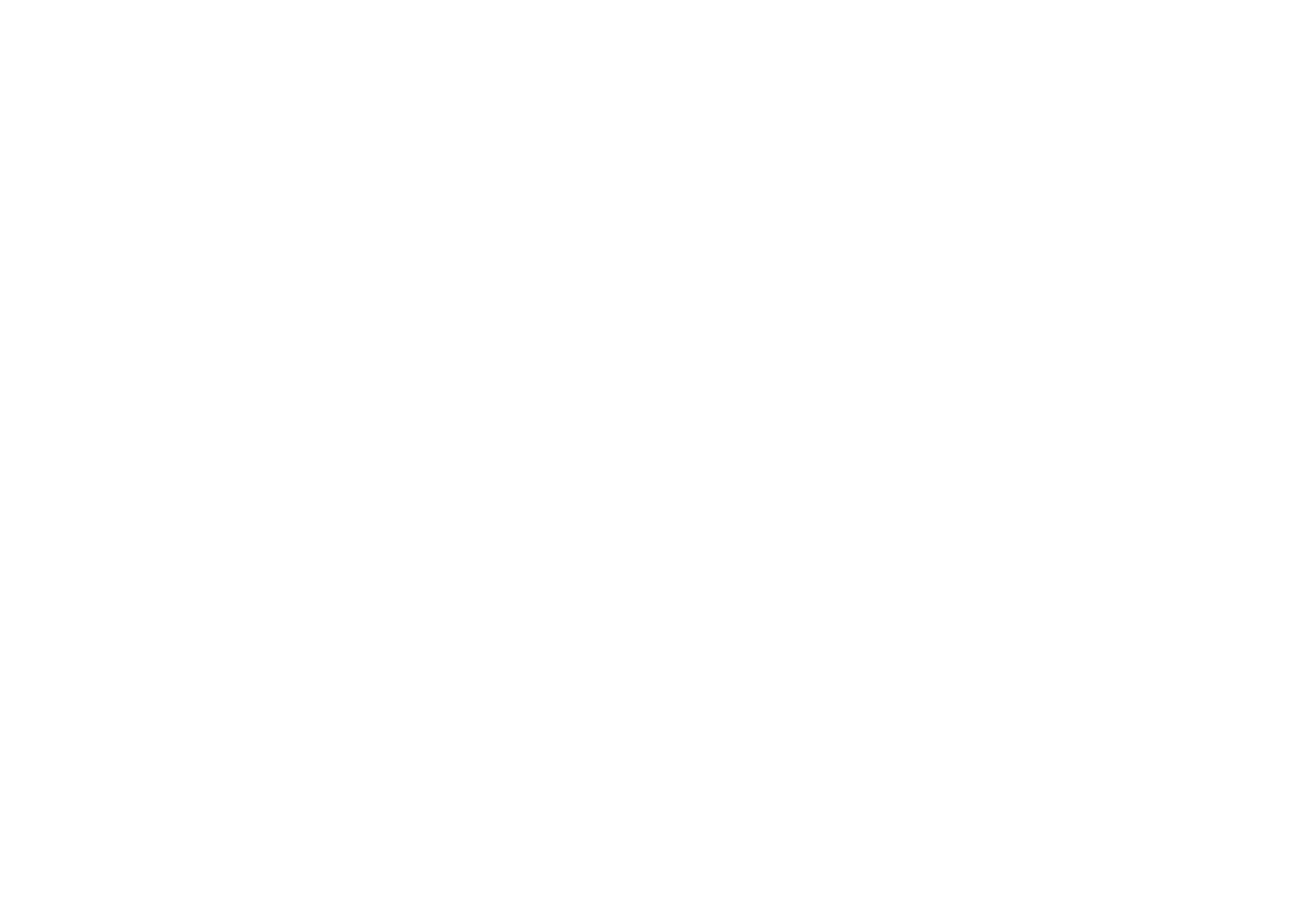
概述 在计算机视觉领域(CV),对视觉特征的理解CNN是长期处于主导地位的。而在NLP领域,Transformer框架的巨大成功,也激发了不少研究者探索将Transformer用于计算机视觉任务。ViT(Vision Transformer)的出现标志着在CV领域Transformer架构迈出了重要的一步。尤其在当前结合LLM的多模态探索上(MM-LLM),都是以LLM大语言模型为骨干架构的模型,多种模态的信息需要先做token化处理,再输入到LLM模型。ViT天然具有序列化特征的建模能力,自然在MM-LLM探索中大放异彩~ ViT在多模态模型中的角色类似于自然语言建模中的Tokenizer组件,对图像进行视觉特征编码,产出图像的序列特征。只不过ViT的编码过程本身也是采用了Transformer的模型结构。 本文主要结合几篇paper和源码讲讲ViT和针对ViT的一些优化方法~ ViT(Vision Transformer)...
Large Model
2026-04-15

通常我们训练神经网络模型的时候默认使用的数据类型为单精度FP32。近年来,为了加快训练时间、减少网络训练时候所占用的内存,并且保存训练出来的模型精度持平的条件下,业界提出越来越多的混合精度训练的方法。 这里的混合精度训练是指在训练的过程中,同时使用单精度(FP32)和半精度(FP16) 。 浮点数据类型 浮点数据类型主要分为双精度(FP64)、单精度(FP32)、半精度(FP16)。在神经网络模型的训练过程中,一般默认采用单精度(FP32)浮点数据类型,来表示网络模型权重和其他参数。在了解混合精度训练之前,这里简单了解浮点数据类型。 根据IEEE二进制浮点数算术标准(IEEE 754)的定义,浮点数据类型分为双精度(FP64)、单精度(FP32)、半精度(FP16)三种,其中每一种都有三个不同的位来表示。 FP64表示采用8个字节共64位,来进行的编码存储的一种数据类型; FP32表示采用4个字节共32位来表示; FP16则是采用2字节共16位来表示。 如图所示: 从图中可以看出,与FP32相比,FP16的存储空间是FP32的一半,FP32则是FP16的一半。主要分为三个部分:...