Deep Learning
2026-04-15
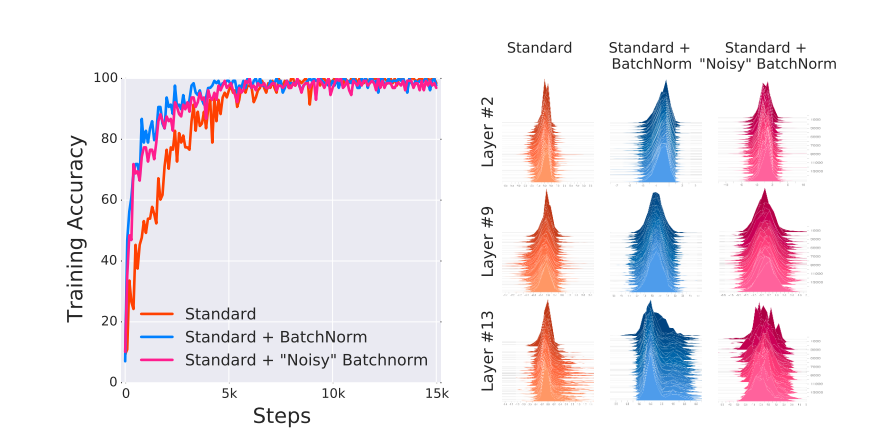
Batch Normalization 什么是批归一化(Batch Normalization) 以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是 输入数据经过 ** \(\sigma(WX+b)\) 这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大**。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。 这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化Batch Normalization(BN)。 其作用在整个mini-batch上,沿着 \(C\) 维度对 \(N,H,W\) 三个维度进行归一化。具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 ...... 加上第 \(N\) 个样本第1个通道,求平均,得到通道 1 的均值 (注意是除以 \(N×H×W\) 而不是单纯除以 \(N\) ,最后得到的是一个代表这个 batch...




