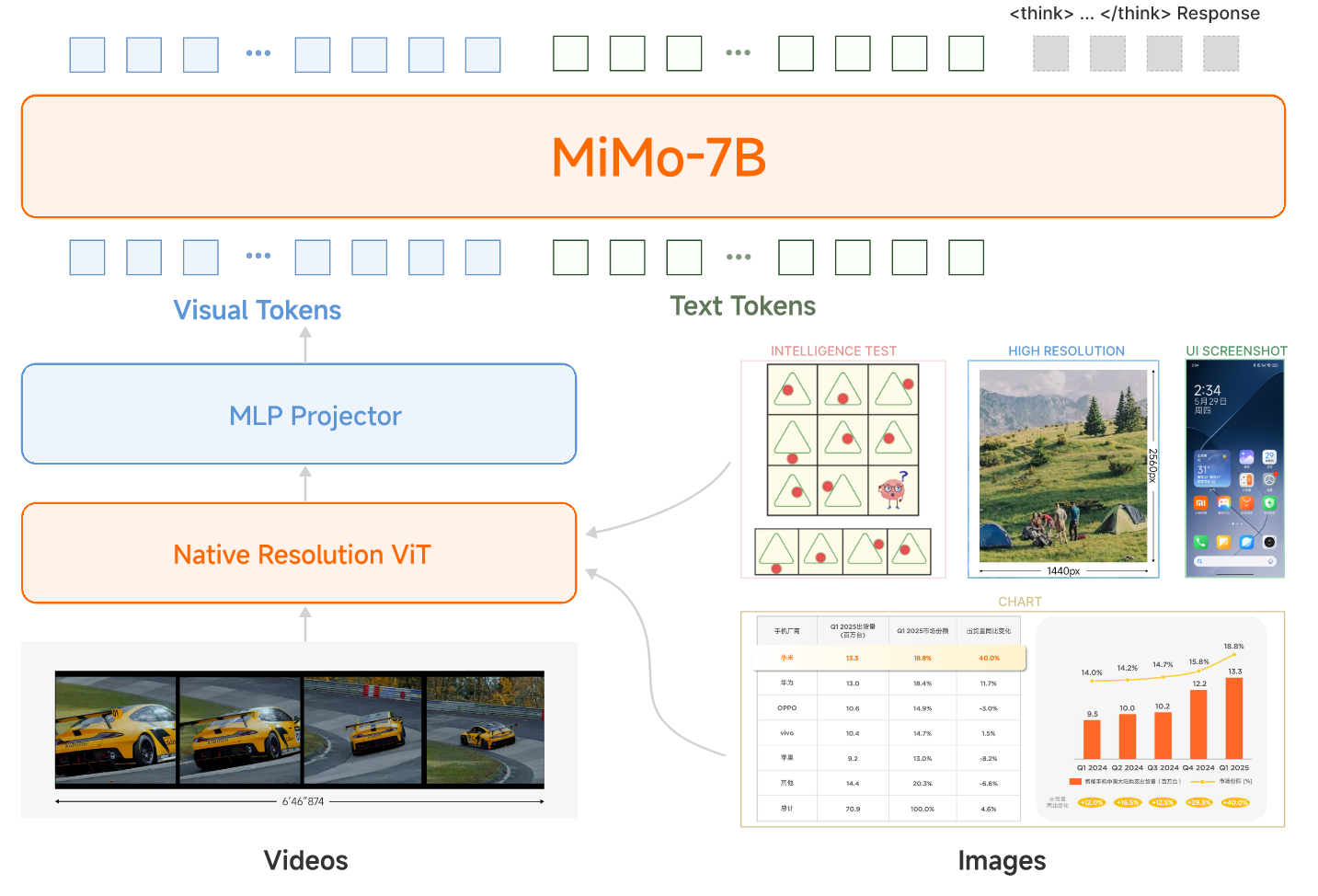
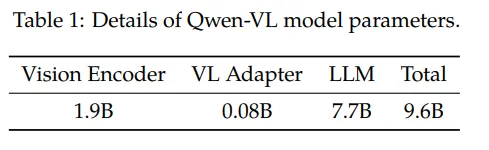
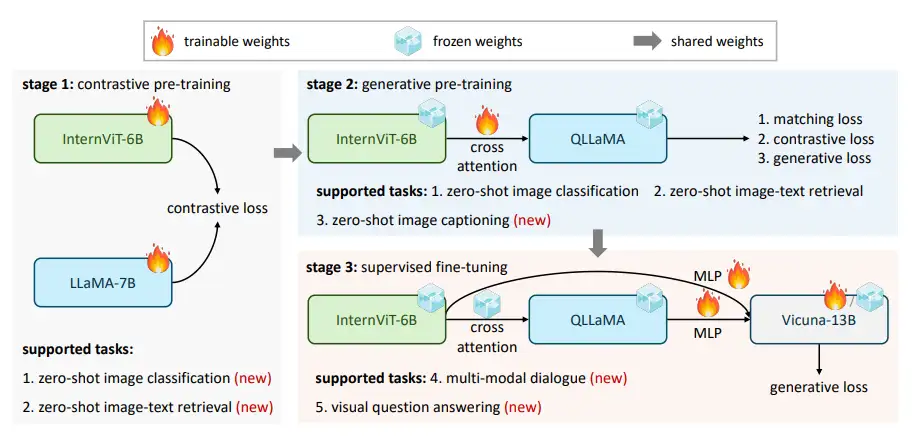
Large Model
2026-04-15

项目: https://llava-vl.github.io/ github: https://github.com/haotian-liu/LLaVA 一句话 优点 : 极大简化了VLM的训练方式:Pre-training + Instruction Tuning 训练量得到简化:1M量级数据+ 8卡A100 → 一天完成训练 LLaVA LLaVA是2023的连续工作,包含了LLaVA 1.0, 1.5, 1.6几个版本(后续会有更多),也是2023年多模态领域妥妥的顶流。发表9个月620的stars,GitHub超过12K的stars。 LLaVA它的网络结构简单、微调成本比较低,任何研究组、企业甚至个人都可以基于它构建自己的领域的多模态模型。 非常建议对多模态大模型感兴趣的朋友关注LLaVA这篇工作。 简介...