Search&Rec
2026-04-15
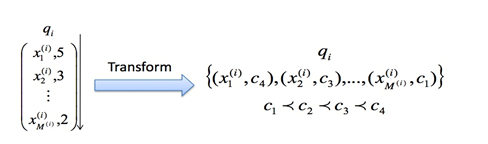
Learning to rank 排序学习是推荐、搜索、广告的核心方法。排序结果的好坏很大程度影响用户体验、广告收入等。排序学习可以理解为机器学习中用户排序的方法,这里首先推荐一本微软亚洲研究院刘铁岩老师关于LTR的著作,Learning to Rank for Information Retrieval,书中对排序学习的各种方法做了很好的阐述和总结。我这里是一个超级精简版。 排序学习是一个有监督的机器学习过程,对每一个给定的查询-文档对,抽取特征,通过日志挖掘或者人工标注的方法获得真实数据标注。然后通过排序模型,使得输入能够和实际的数据相似。常用的排序学习分为三种类型:PointWise,PairWise和ListWise。 PointWise 单文档方法的处理对象是单独的一篇文档,将文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档打分,打分结果即是搜索结果...