
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
Large Model
2026-04-15
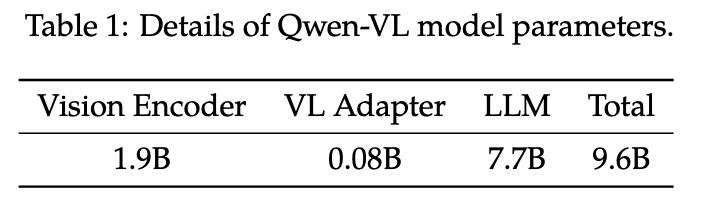
Qwen-VL 模型框架 Qwen-VL的整体网络架构由三个组件组成: LLM:使用 Qwen-7B 的预训练权重进行初始化。 视觉编码器:Qwen-VL 的可视化编码器使用ViT 架构,使用 Openclip 的 ViT-bigG 的预训练权重进行初始化。在训练和推理过程中,输入图像的大小都会调整为特定分辨率。视觉编码器通过以 14 步幅将图像分割成块来处理图像,生成一组图像特征。 位置感知视觉语言适配器:为了缓解长图像特征序列带来的效率问题,Qwen-VL 引入了一种视觉语言适配器来压缩图像特征。类似QFormer,该适配器包括一个随机初始化的单层交叉注意力模块。使用一组可训练向量(嵌入)作为query,并将视觉编码器中的图像特征作为交叉注意力作的key。该机制将视觉特征序列压缩到固定长度 256。 图像输入 图像不会直接以像素形式喂给语言模型(LLM)。 典型流程是: Visual Encoder :把图片编码成一串视觉特征(embedding/feature sequence)。 Adapter :把视觉特征映射到语言模型可接入的表征空间/维度。 最终得到:...
Large Model
2026-04-15

总览 由于是“图文多模态”,还是要从“图”和“文”的表征方法讲起,然后讲清楚图文表征的融合方法。这里只讲两件事情: 视觉表征 :分为两个部分问题,一是如何合理建模视觉输入特征,二是如何通过预训练手段进行充分学习表征,这两点是基于视觉完成具体算法任务的基础; 视觉与自然语言的对齐(Visul Language Alignment)或融合 :目的是将视觉和自然语言建模到同一表征空间并进行融合,实现自然语言和视觉语义的互通,这点同样离不开预训练这一过程。模态对齐是处理多模态问题的基础,也是现在流行的多模态大模型技术前提。 对于视觉表征,从发展上可以分为卷积神经网络(CNN)和Vision Transformer(VIT)两大脉络,二者分别都有各自的表征、预训练以及多模态对齐的发展过程。而对于VIT线,另有多模态大模型如火如荼的发展,可谓日新月异。 CNN:视觉理解的一代先驱 点击展开 卷积视觉表征模型和预训练...
Large Model
2026-04-15

SigLIP 概述 CLIP自提出以来在zero-shot分类、跨模态搜索、多模态对齐等多个领域得到广泛应用。得益于其令人惊叹的能力,激起了研究者广泛的关注和优化。 目前对CLIP的优化主要可以分为两大类: 其一是如何降低CLIP的训练成本; 其二是如何提升CLIP的performance。 对于第一类优化任务的常见思路有3种。 优化训练架构,如 LiT 通过freezen image encoder,单独训练text encoder来进行text 和image的对齐来加速训练; 减少训练token,如 FLIP 通过引入视觉mask,通过只计算非mask区域的视觉表征来实现加速(MAE中的思路) 优化目标函数,如 CatLIP 将caption转为class label,用分类任务来代替对比学习任务来实现加速。 对于第二类提升CLIP的performance最常用和有效的手段就是数据治理,即构建高质量、大规模、高多样性的图文数据,典型的工作如:DFN。 SigLIP这篇paper 提出用sigmoid...
杂七杂八
2026-04-15

分布式深度学习里的通信严重依赖于规则的集群通信,诸如 all-reduce, reduce-scatter, all-gather 等,因此,实现高度优化的集群通信,以及根据任务特点和通信拓扑选择合适的集群通信算法至关重要。 本文以数据并行经常使用的 all-reduce 为例来展示集群通信操作的数学性质。 All-reduce 在干什么? 图 1:all-reduce 如图 1 所示,一共 4个设备,每个设备上有一个矩阵(为简单起见,我们特意让每一行就一个元素), all-reduce 操作的目的是,让每个设备上的矩阵里的每一个位置的数值都是所有设备上对应位置的数值之和。 图2 如图 2 所示, all-reduce 可以通过 reduce-scatter 和 all-gather 这两个更基本的集群通信操作来实现。基于 ring 状通信可以高效的实现 reduce-scatter 和 all-gather,下面我们分别用示意图展示其过程。 reduce-scatter 的实现和性质 图 3:通过环状通信实现 reduce-scatter 从图 2...

一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。 线程 进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。 与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。 Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。 public class MultiThread {
public static void main(String[] args) {
// 获取 Java 线程管理 MXBean
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
// 不需要获取同步的 monitor 和...