
Hough Voting 本文的标题是Deep Hough Voting,先来说一下Hough Voting。 用Hough变换检测直线大家想必都听过:对于一条直线,可以使用 \((r,θ)\) 两个参数进行描述,那么对于图像中的一点,过这个点的直线有很多条,可以生成一系列的 \((r,θ)\) ,在参数平面内就是一条曲线,也就是说,一个点对应着参数平面内的一个曲线。那如果有很多个点,则会在参数平面内生成很多曲线。那么,如果这些点是能构成一条直线的,那么这条直线的参数 \((r,θ)\) 就在每条曲线中都存在,所以看起来就像是多条曲线相交在 \((r,θ)\) 。可以用多条曲线投票的方式来看,其他点都是很少的票数,而 \((r,θ)\) 则票数很多,所以直线的参数就是 \((r,θ)\) 。 所以Hough变换的思想就是在于,在参数空间内进行投票,投票得数高的就是要得到的值。 文中提到的Hough Voting如下: A traditional Hough voting 2D detector comprises an offline and an online step....
Large Model
2026-04-15

Stanford Alpaca 结合英文语料通过Self Instruct方式微调LLaMA 7B Stanford Alpaca简介 2023年3月中旬,斯坦福的Rohan Taori等人发布Alpaca(中文名:羊驼):号称只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型(即LLaMA 7B), 具体做法是通过52k指令数据,然后在8个80GB A100上训练3个小时,使得Alpaca版的LLaMA 7B在单纯对话上的性能比肩GPT-3.5(text-davinci-003) ,这便是指令调优LLaMA的意义所在 论文《Alpaca: A Strong Open-Source Instruction-Following Model》 GitHub地址: https://github.com/tatsu-lab/stanford_alpaca 数据地址 (即斯坦福团队微调LLaMA 7B所用的52K英文指令数据): raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json...
Large Model
2026-04-15
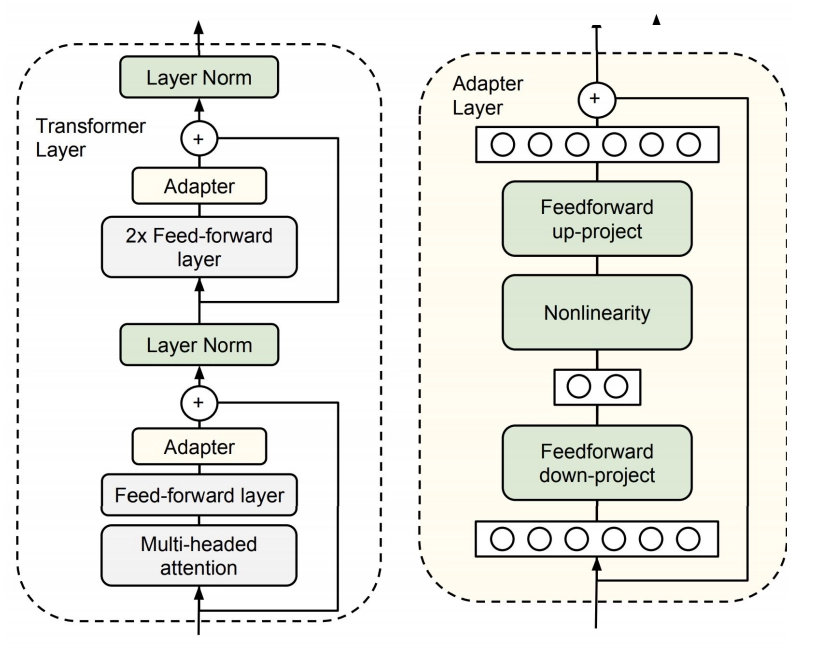
Adapter tuning Adapter Tuning试图在Transformer Layer的Self-Attetion+FFN之后插入一个先降维再升维的MLP(以及一层残差和LayerNormalization)来学习模型微调的知识。 在预训练模型每一层(或某些层)中添加Adapter模块(如上图左侧结构所示),微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。每个Adapter模块由两个前馈子层组成,第一个前馈子层将Transformer块的输出作为输入,将原始输入维度 \(d\) 投影到 \(m\) ,通过控制 \(m\) 的大小来限制Adapter模块的参数量,通常情况下 \(m\ll d\) 。在输出阶段,通过第二个前馈子层还原输入维度,将 \(m\) 重新投影到 \(d\)...
Large Model
2026-04-15
LLaMA 论文名称 :LLaMA: Open and Efficient Foundation Language Models 论文地址: https://arxiv.org/pdf/2302.13971.pdf 代码链接: https://github.com/facebookresearch/llama 模型参数量级的积累,或者训练数据的增加,哪个对性能提升帮助更大? 以 GPT-3 为代表的大语言模型 (Large language models, LLMs) 在海量文本集合上训练,展示出了惊人的涌现能力以及零样本迁移和少样本学习能力。GPT-3 把模型的量级缩放到了 175B,也使得后面的研究工作继续去放大语言模型的量级。大家好像有一个共识,就是: 模型参数量级的增加就会带来同样的性能提升。 但是事实确实如此吗? 最近的 "Training Compute-Optimal Large Language Models" 这篇论文提出一种 缩放定律 (Scaling Law): 训练大语言模型时,在计算成本达到最优情况下,模型大小和训练数据 (token)...
背景 RLHF 通常包括三个阶段: 有监督微调(SFT) RLHF首先通过在高质量数据上进行监督学习来微调预训练的语言模型,得到模型 \(\pi_{SFT}\) 。 奖励建模阶段 (Reward Model) 在第二阶段,SFT模型根据提示 \(x\) 生成答案对 \((y_1, y_2) \sim \pi_{SFT}(y|x)\) 。这些答案对呈现给人类标注者,他们表达对一个答案的偏好,表示为 \(y_w \succ y_l|x\) ,其中 \(y_w\) 和 \(y_l\) 分别表示在 \((y_1, y_2)\) 中更受偏好和不受偏好的答案。 这些偏好被假定由某个潜在的奖励模型 \(r^*(y, x)\) 生成,我们无法直接访问该模型。一种流行的建模偏好的方法是Bradley-Terry(BT)模型,该模型规定人类偏好分布 \(p^*\) 可以写为: \[p^*(y_1 \succ y_2|x) = \frac{\exp(r^*(x, y_1))}{\exp(r^*(x, y_1)) + \exp(r^*(x, y_2))}
\] 假设我们有一个从 \(p^*\)...
Large Model
2026-04-15

简介 24年12月,研究团队开发了 DeepSeek-V3,这是一个基于 MoE 架构的大模型,总参数量达到 671B,其中每个 token 会激活 37B 个参数。 基于提升性能和降低成本的双重目标,在架构设计方面,DeepSeek-V3 采用了 MLA 来确保推理效率,并使用 DeepSeekMoE 来实现经济高效的训练。这两种架构在 DeepSeek-V2 中已经得到验证,证实了它们能够在保持模型性能的同时实现高效的训练和推理。 除了延续这些基础架构外,研究团队还引入了两项创新策略来进一步提升模型性能。 首先,DeepSeek-V3 首创了 无辅助损失的负载均衡 策略(auxiliary-loss-free strategy for load balancing),有效降低了负载均衡对模型性能的负面影响。另外,DeepSeek-V3 采用了 多 token 预测训练目标, 这种方法在评估基准测试中展现出了显著的性能提升。 为了提高训练效率,该研究采用了 FP8 混合精度训练技术...
Large Model
2026-04-15

简介 后训练(post-training)已成为完整训练流程中的重要组成部分。相比于预训练,后训练需要的计算资源相对较少,但能够: 提高推理任务的准确性 使模型与社会价值观保持一致 适应用户偏好 OpenAI 的 o1 系列模型首次引入了通过增加思维链(Chain-of-Thought)推理过程长度来实现推理时间,扩展这种方法在数学、编程和科学推理等各种推理任务上取得了显著改进 研究界已探索多种方法来提高模型的推理能力:比如 基于过程的奖励模型 (Process-based Reward Models) 强化学习 (Reinforcement Learning), 代表工作:InstructGPT, 以及 搜索算法( 蒙特卡洛树搜索(Monte Carlo Tree Search)、束搜索(Beam Search))。然而,这些方法尚未达到与 OpenAI o1 系列模型相当的通用推理性能。 DeepSeek-R1-Zero 本文首先探索使用纯强化学习(RL)来提高语言模型的推理能力,重点关注: 探索 LLM 在没有任何监督数据的情况下,通过纯 RL 过程的自我进化来发展推理能力...
Computer Vision
2026-04-15

上图是Yolo v4中,对各种detector部件的总结:包含Input、backbone、neck、head、... Backbone 轻量级网络系列 Neck 例如:SPP 、 ASPP 、 RFB、 SAM 用来增加感受野 特征融合,主要是指不同输出层直接的特征融合,主要包括FPN、PAN、SFAM、ASFF和BiFPN。 结构 Path Aggregation Blcok Deformable Convolution系列 One stage Yolo系列 Focal Loss & RetinaNet Two-Stage Faster R-CNN R-FCN Anchor Free Anchor-Free Transformer DETR Problems 目标检测中的多尺度问题 NMS及其改进 IoU loss系列 目标检测中mAP计算
Large Model
2026-04-15

https://www.deepseek.com/ DeepSeek LLM 代码地址: https://github.com/deepseek-ai/DeepSeek-LLM 背景 量化巨头幻方探索AGI(通用人工智能)新组织“深度求索”在成立半年后,发布的第一代大模型,免费商用,完全开源。作为一家隐形的AI巨头,幻方拥有1万枚英伟达A100芯片,有手撸的HAI-LLM训练框架HAI-LLM:高效且轻量的大模型训练工具。 概述 DeepSeek LLMs,这是一系列在2万亿标记的英语和中文大型数据集上从头开始训练的开源模型 在本文中,深入解释了超参数选择、Scaling Laws以及做过的各种微调尝试。校准了先前工作中的Scaling Laws,并提出了新的最优模型/数据扩展-缩放分配策略。此外,还提出了一种方法,使用给定的计算预算来预测近似的batch-size和learning-rate。进一步得出结论,Scaling Laws与数据质量有关,这可能是不同工作中不同扩展行为的原因。在Scaling Laws的指导下,使用最佳超参数进行预训练,并进行全面评估。...
Large Model
2026-04-15

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...

论文地址: https://arxiv.org/pdf/2107.11291 代码地址: https://github.com/Jeff-sjtu/res-loglikelihood-regression 前言 一般来说, 我们可以把姿态估计任务分成两个流派:Heatmap-based和Regression-based。 其主要区别在于监督信息的不同,Heatmap-based方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或soft-argmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression-based方法则非常简单粗暴,直接监督模型学习坐标值,计算坐标值的L1或L2...
Computer Vision
2026-04-15

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zero-shot 和 few-shot能力,结合prompt engineering和fine tuning等技术可以将基座模型应用在各种下游任务中并实现惊人的效果。 SAM就是想构建一个这样的图像分割基座模型,即使是一个未见过的数据集,模型也能自动或半自动(基于prompt)地完成下游的分割任务。为了实现这个目标,SAM定义了一种可提示化的分割任务(promptable...