线性结构与技巧 基础容器 数组 (Array) 链表 (Linked List) 字符串 (String) KMP算法 核心技巧 双指针 滑动窗口 二分查找 栈与队列 栈 & 队列 (Stack & Queue) 单调队列 树与图论 树与堆 (Tree & Heap) 树的遍历 二叉树 堆(大顶堆&小顶堆) 优先队列 图 (Graph) 搜索(BFS/DFS) 最小生成树 核心算法思想 动态规划 (DP) 基础 DP 背包问题 排序 基础排序算法 排序算法 数据处理 哈希表 Math

236. 二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百 度百科中最近公共祖先的定义为:“对于有根树 \(T\) 的两个节点 \(p\) 、 \(q\) ,最近公共祖先表示为一个节点 \(x\) ,满足 \(x\) 是 \(p\) 、 \(q \) 的祖先且 \(x\) 的深度尽可能大( 一个节点也可以是它自己的祖先 )。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root = [1,2], p = 1, q = 2
输出:1 提示: 树中节点数目在范围 [2, 10 5 ] 内。 -10 9 <= Node.val <= 10 9 所有 Node.val...
二叉树结构 class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None 递归 时间复杂度: \(O(n)\) , \(n\) 为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度: \(O(h)\) , \(h\) 为树的高度。最坏情况下需要空间 \(O(n)\) ,平均情况为 \(O(logn)\) 递归1: 二叉树遍历最易理解和实现版本 class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
# 前序递归
return [root.val] + self.preorderTraversal(root.left) + self.preorderTraversal(root.right)
...

48. 旋转图像 题目 给定一个 \(n × n\) 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。 请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]] 示例 2: 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]] 提示: n == matrix.length == matrix[i].length 1 <= n <= 20 -1000 <= matrix[i][j] <= 1000 题解 这是一个经典的矩阵操作问题。要在原地(In-place)将图像顺时针旋转 90 度,我们可以利用矩阵的几何性质。 最直观且易于实现的方法是将...
Computer Vision
2026-04-15

空洞卷积 Dilated/Atrous Convolution 或者是 Convolution with holes 从字面上就很好理解,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyper-parameter 称之为 dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)。 一个简单的例子 一维情况下空洞卷积的公式如下 \[y[i]=\sum_{k=1}^Kx[i+r\cdot k]w[k]\] 不过光理解他的工作原理还是远远不够的,要充分理解这个概念我们得重新审视卷积本身,并去了解他背后的设计直觉。以下主要讨论 dilated convolution 在语义分割 (semantic segmentation) 的应用。 重新思考卷积: Rethinking Convolution...
Computer Vision
2026-04-15

上图是Yolo v4中,对各种detector部件的总结:包含Input、backbone、neck、head、... Backbone 轻量级网络系列 Neck 例如:SPP 、 ASPP 、 RFB、 SAM 用来增加感受野 特征融合,主要是指不同输出层直接的特征融合,主要包括FPN、PAN、SFAM、ASFF和BiFPN。 结构 Path Aggregation Blcok Deformable Convolution系列 One stage Yolo系列 Focal Loss & RetinaNet Two-Stage Faster R-CNN R-FCN Anchor Free Anchor-Free Transformer DETR Problems 目标检测中的多尺度问题 NMS及其改进 IoU loss系列 目标检测中mAP计算
Large Model
2026-04-15

CLIP算法原理 CLIP 不预先定义图像和文本标签类别,直接利用从互联网爬取的 400 million 个image-text pair 进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉分类。简单的说,CLIP 无需利用 ImageNet 的数据和标签进行训练,就可以达到 ResNet50 在 ImageNet数据集上有监督训练的结果,所以叫做 Zero-shot。 CLIP(contrastive language-image pre-training)主要的贡献就是 利用无监督的文本信息,作为监督信号来学习视觉特征 。 CLIP 作者先是回顾了并总结了和上述相关的两条表征学习路线: 构建image和text的联系,比如利用已有的image-text pair数据集,从text中学习image的表征; 获取更多的数据(不要求高质量,也不要求full...

论文地址: https://arxiv.org/pdf/2107.11291 代码地址: https://github.com/Jeff-sjtu/res-loglikelihood-regression 前言 一般来说, 我们可以把姿态估计任务分成两个流派:Heatmap-based和Regression-based。 其主要区别在于监督信息的不同,Heatmap-based方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或soft-argmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression-based方法则非常简单粗暴,直接监督模型学习坐标值,计算坐标值的L1或L2...
Computer Vision
2026-04-15

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zero-shot 和 few-shot能力,结合prompt engineering和fine tuning等技术可以将基座模型应用在各种下游任务中并实现惊人的效果。 SAM就是想构建一个这样的图像分割基座模型,即使是一个未见过的数据集,模型也能自动或半自动(基于prompt)地完成下游的分割任务。为了实现这个目标,SAM定义了一种可提示化的分割任务(promptable...
Large Model
2026-04-15

BLIP 论文名称 :BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (ICML 2022) 论文地址: https://arxiv.org/pdf/2201.12086.pdf 代码地址: https://github.com/salesforce/BLIP 官方解读博客: https://blog.salesforceairesearch.com/blip-bootstrapping-language-image-pretraining/ 背景和动机 视觉语言训练 (Vision-Language Pre-training, VLP) 最近在各种多模态下游任务上取得了巨大的成功。然而,现有方法有两个主要限制: 模型层面: 大多数现有的预训练模型仅在基于理解的任务或者基于生成的任务方面表现出色,很少有可以兼顾的模型。比如,基于编码器的模型,像 CLIP,ALBEF 不能直接转移到文本生成任务...
Computer Vision
2026-04-15
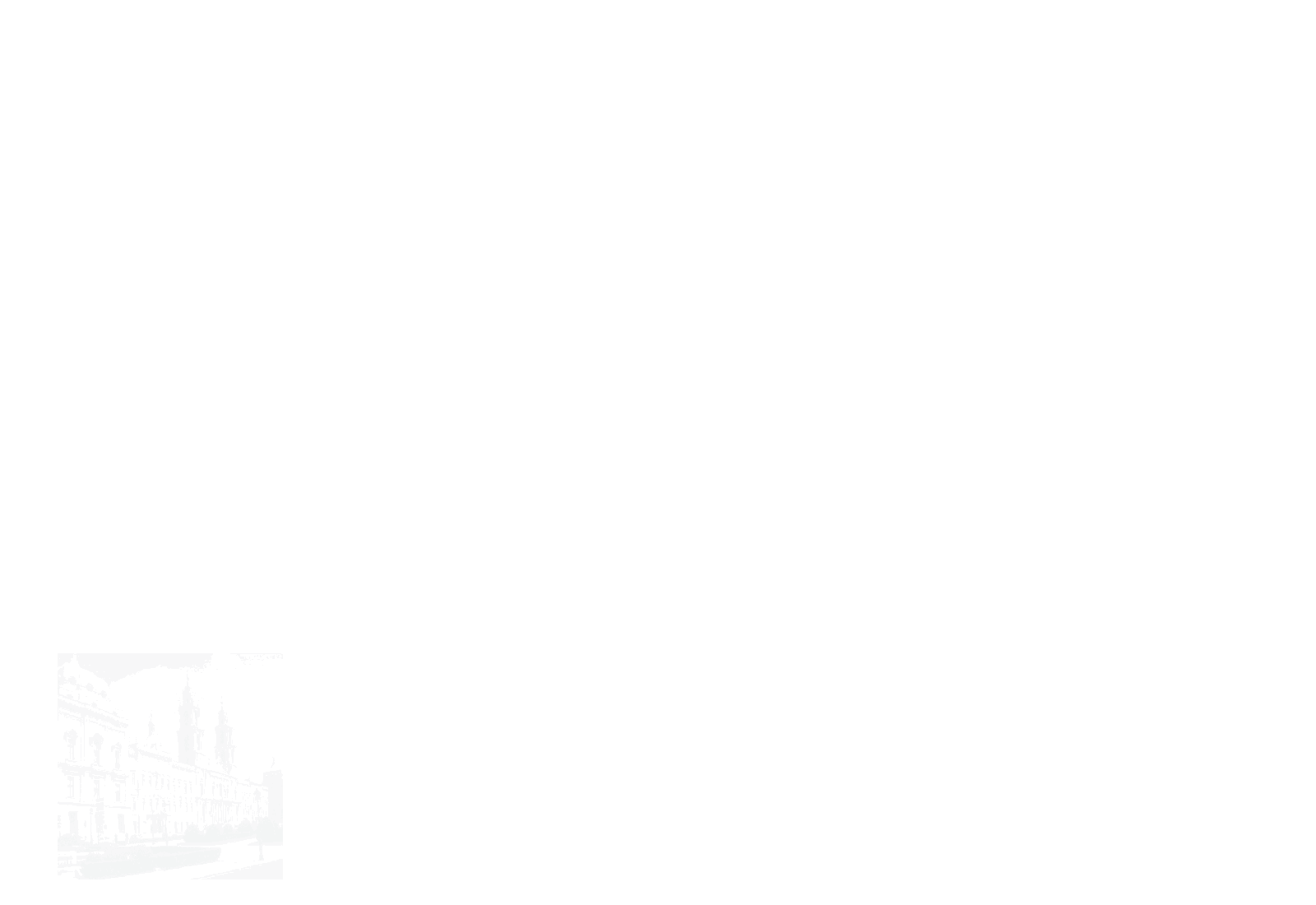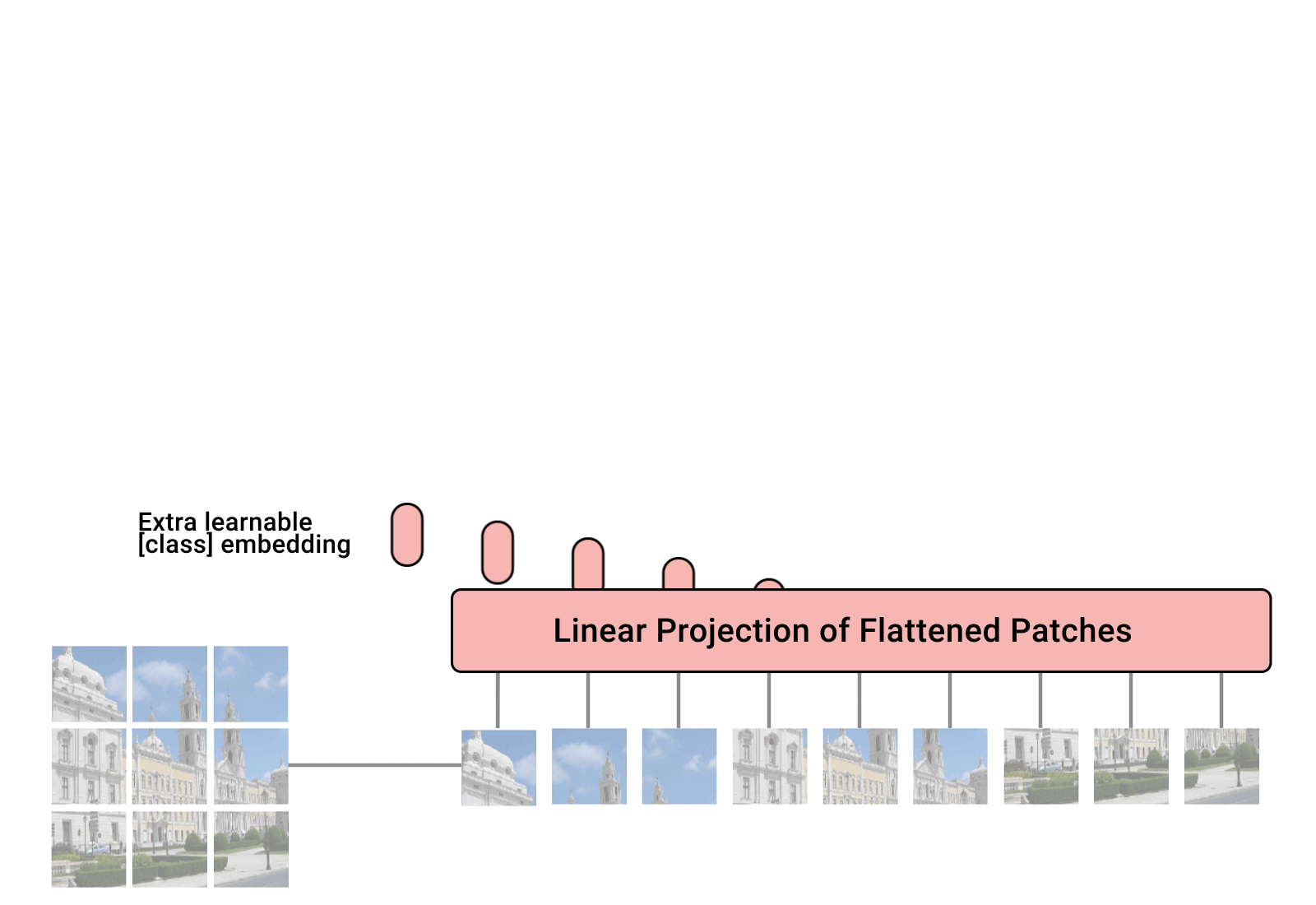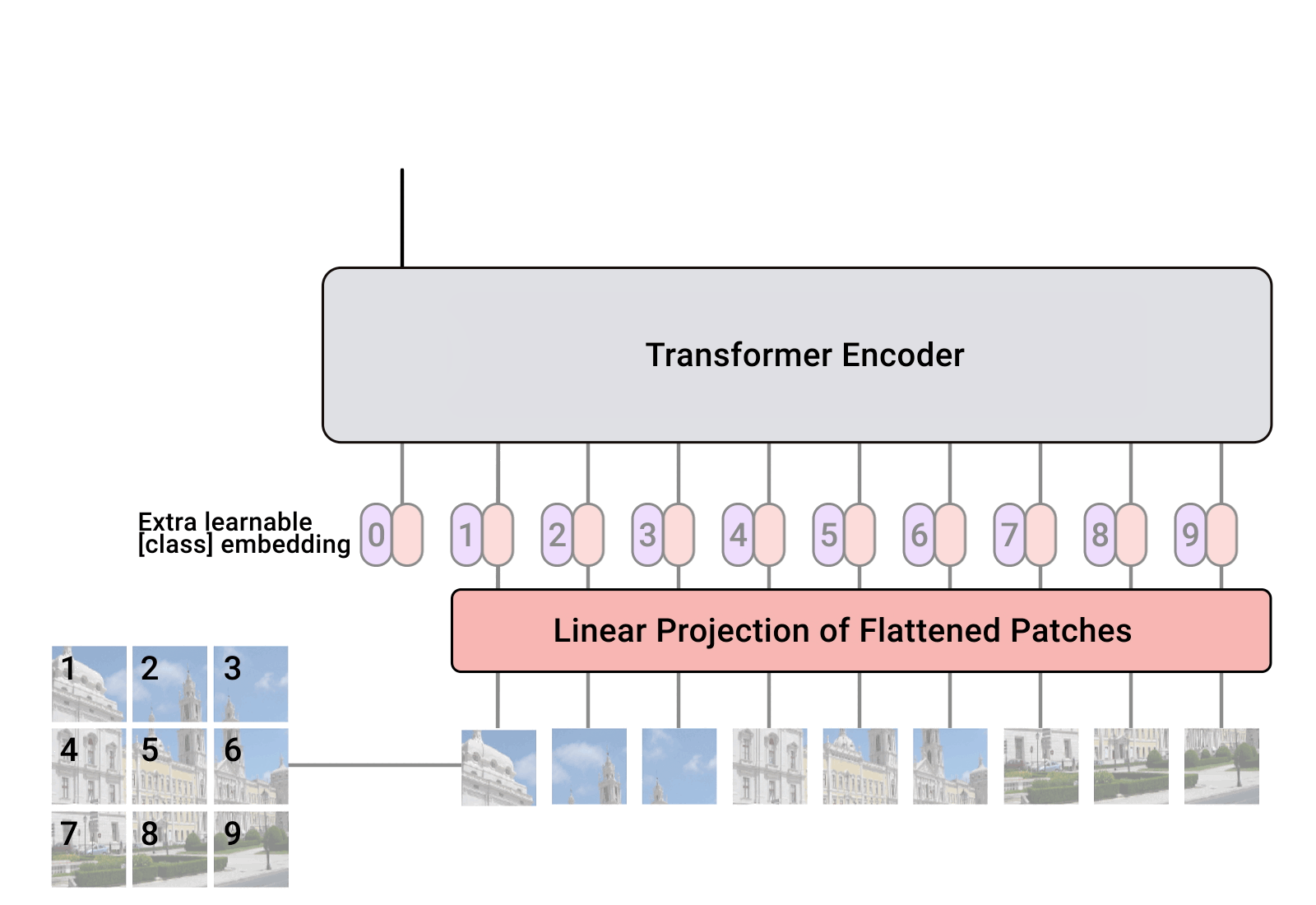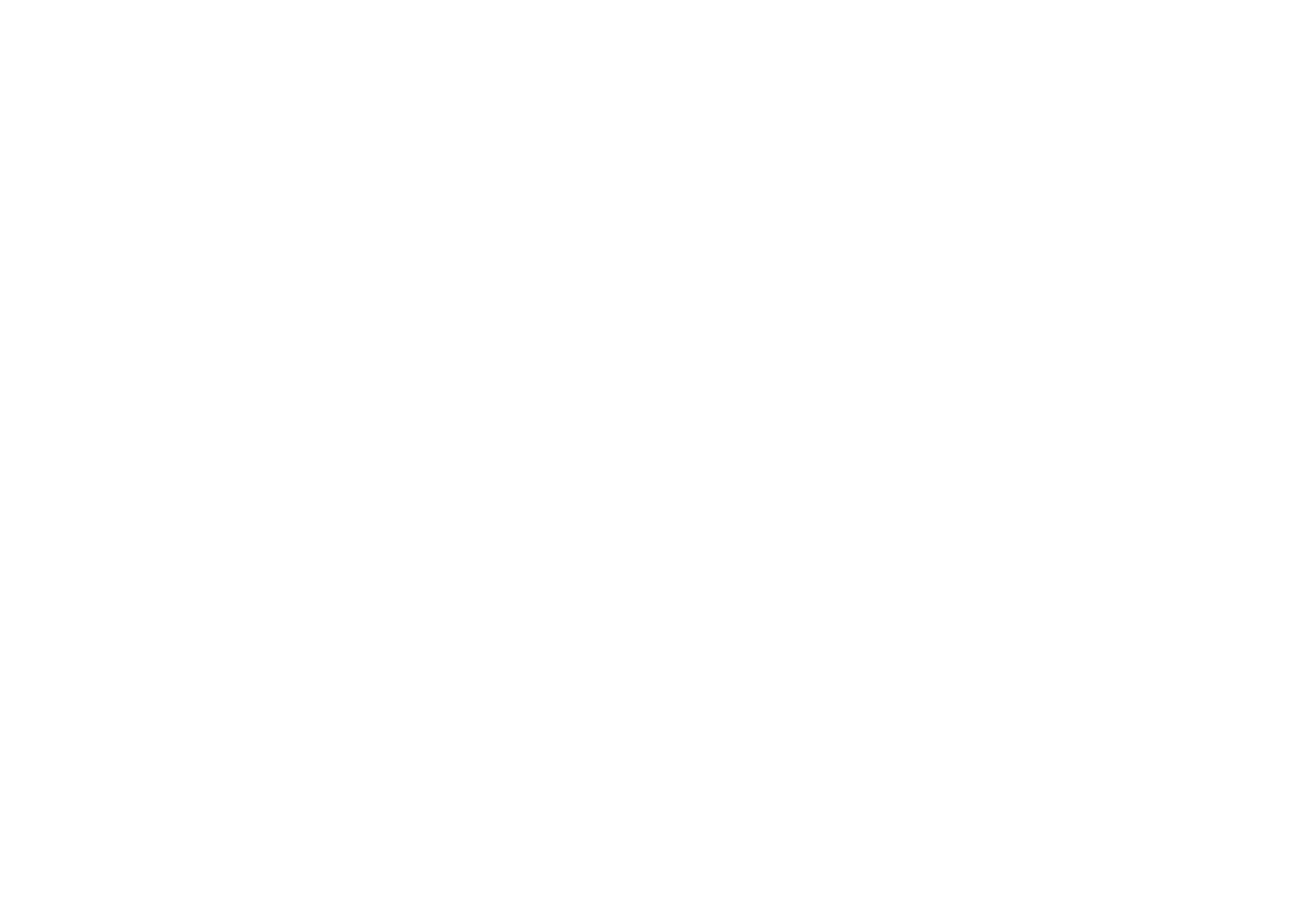
概述 在计算机视觉领域(CV),对视觉特征的理解CNN是长期处于主导地位的。而在NLP领域,Transformer框架的巨大成功,也激发了不少研究者探索将Transformer用于计算机视觉任务。ViT(Vision Transformer)的出现标志着在CV领域Transformer架构迈出了重要的一步。尤其在当前结合LLM的多模态探索上(MM-LLM),都是以LLM大语言模型为骨干架构的模型,多种模态的信息需要先做token化处理,再输入到LLM模型。ViT天然具有序列化特征的建模能力,自然在MM-LLM探索中大放异彩~ ViT在多模态模型中的角色类似于自然语言建模中的Tokenizer组件,对图像进行视觉特征编码,产出图像的序列特征。只不过ViT的编码过程本身也是采用了Transformer的模型结构。 本文主要结合几篇paper和源码讲讲ViT和针对ViT的一些优化方法~ ViT(Vision Transformer)...
Large Model
2026-04-15

总览 由于是“图文多模态”,还是要从“图”和“文”的表征方法讲起,然后讲清楚图文表征的融合方法。这里只讲两件事情: 视觉表征 :分为两个部分问题,一是如何合理建模视觉输入特征,二是如何通过预训练手段进行充分学习表征,这两点是基于视觉完成具体算法任务的基础; 视觉与自然语言的对齐(Visul Language Alignment)或融合 :目的是将视觉和自然语言建模到同一表征空间并进行融合,实现自然语言和视觉语义的互通,这点同样离不开预训练这一过程。模态对齐是处理多模态问题的基础,也是现在流行的多模态大模型技术前提。 对于视觉表征,从发展上可以分为卷积神经网络(CNN)和Vision Transformer(VIT)两大脉络,二者分别都有各自的表征、预训练以及多模态对齐的发展过程。而对于VIT线,另有多模态大模型如火如荼的发展,可谓日新月异。 CNN:视觉理解的一代先驱 点击展开 卷积视觉表征模型和预训练...