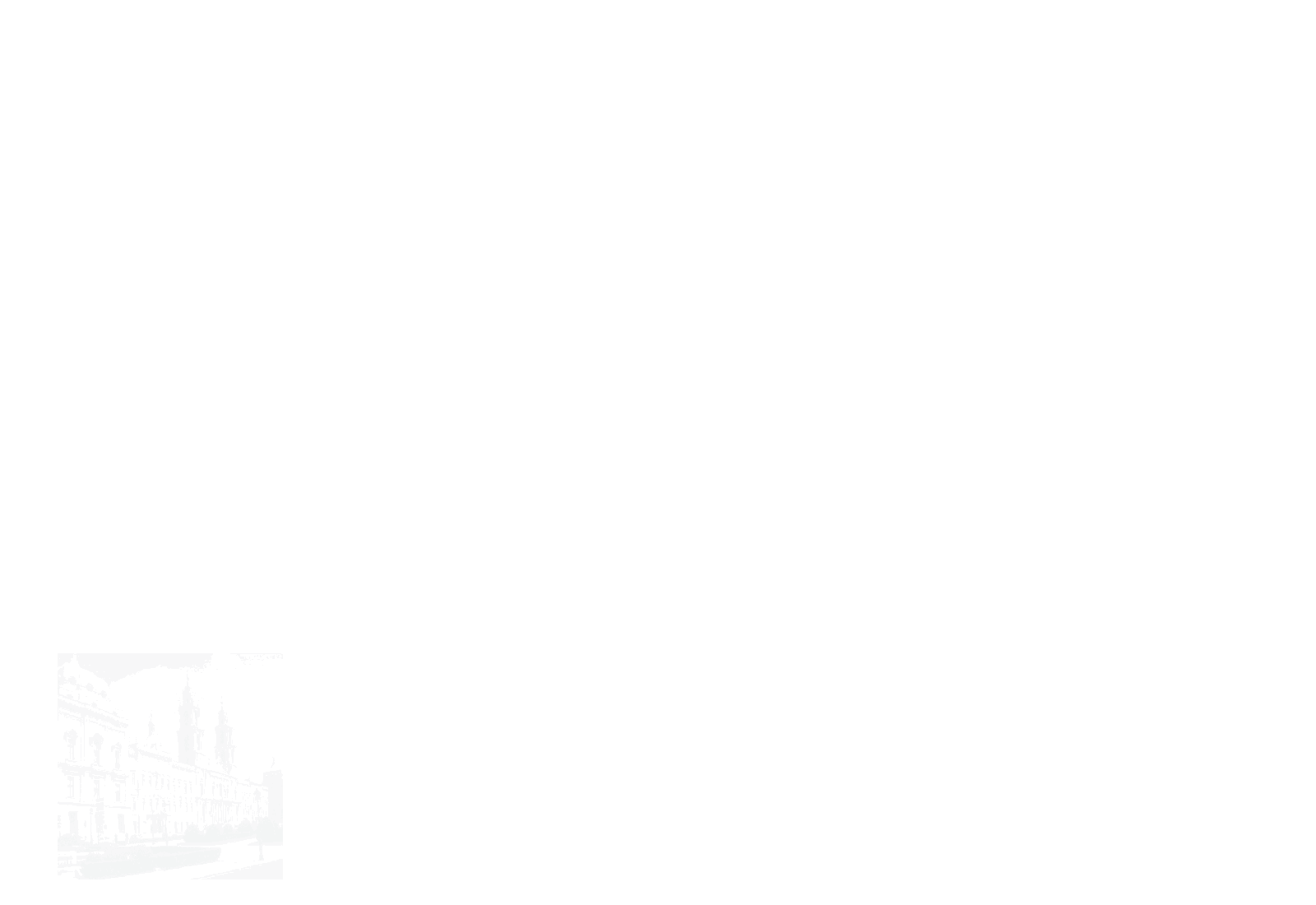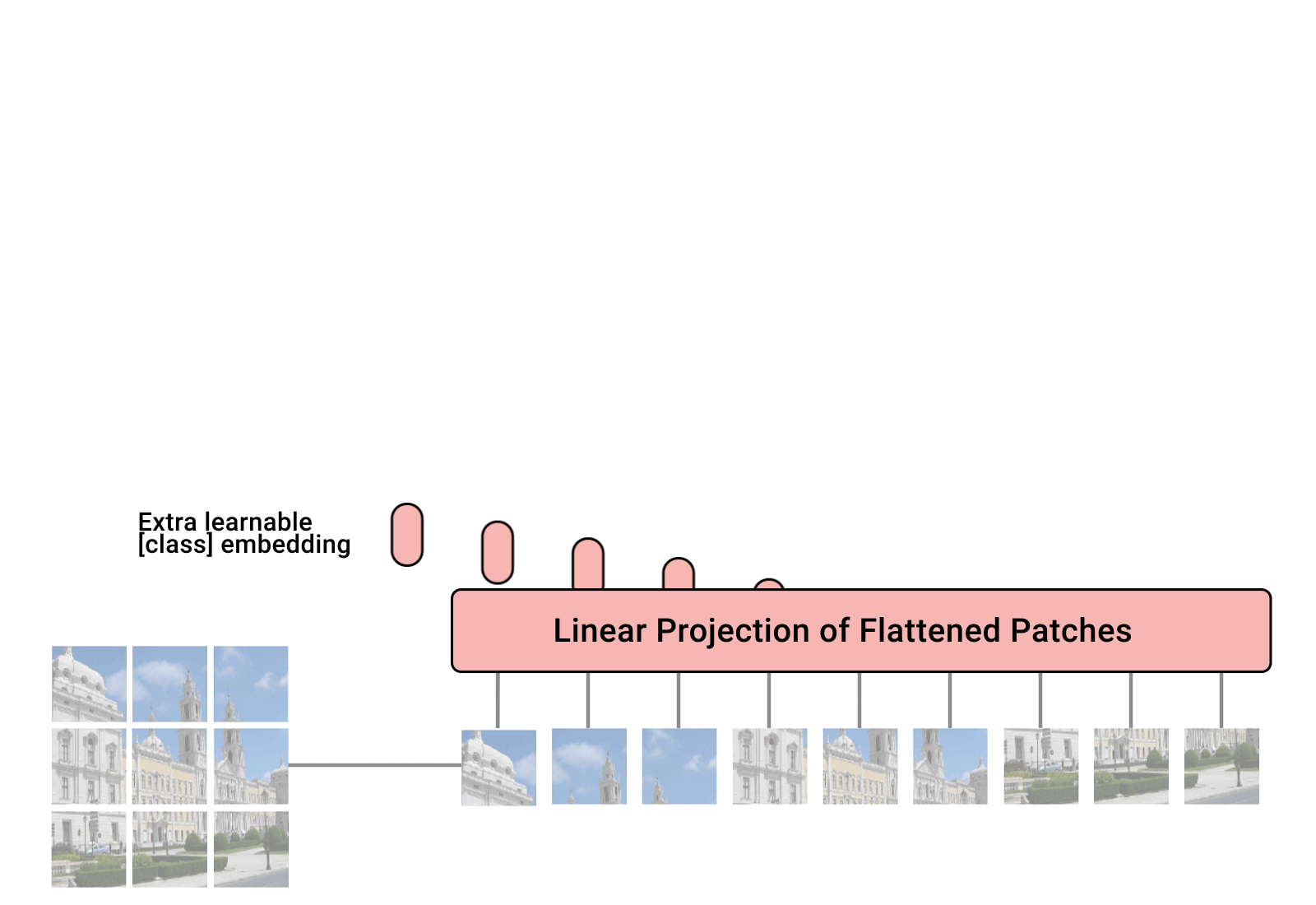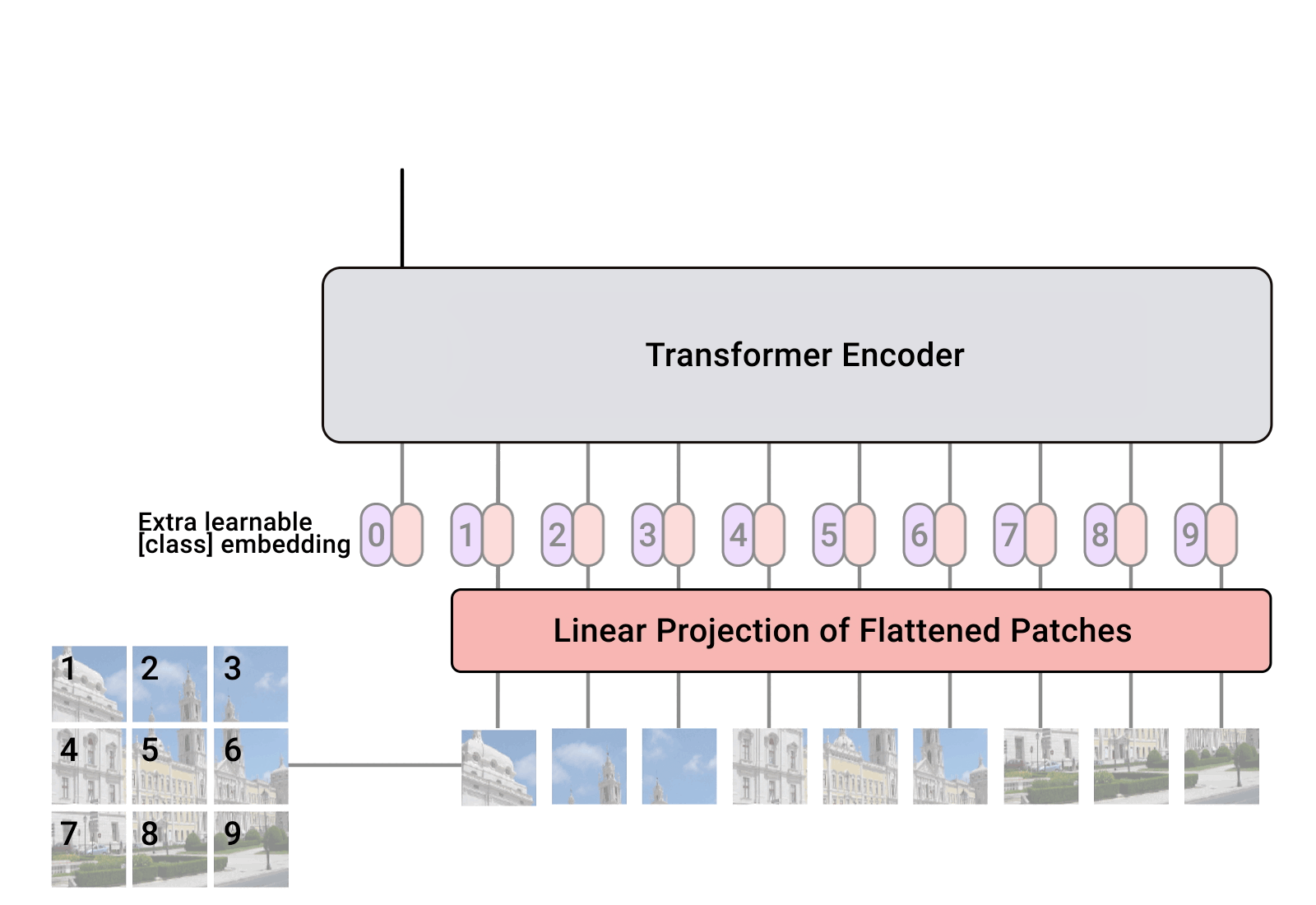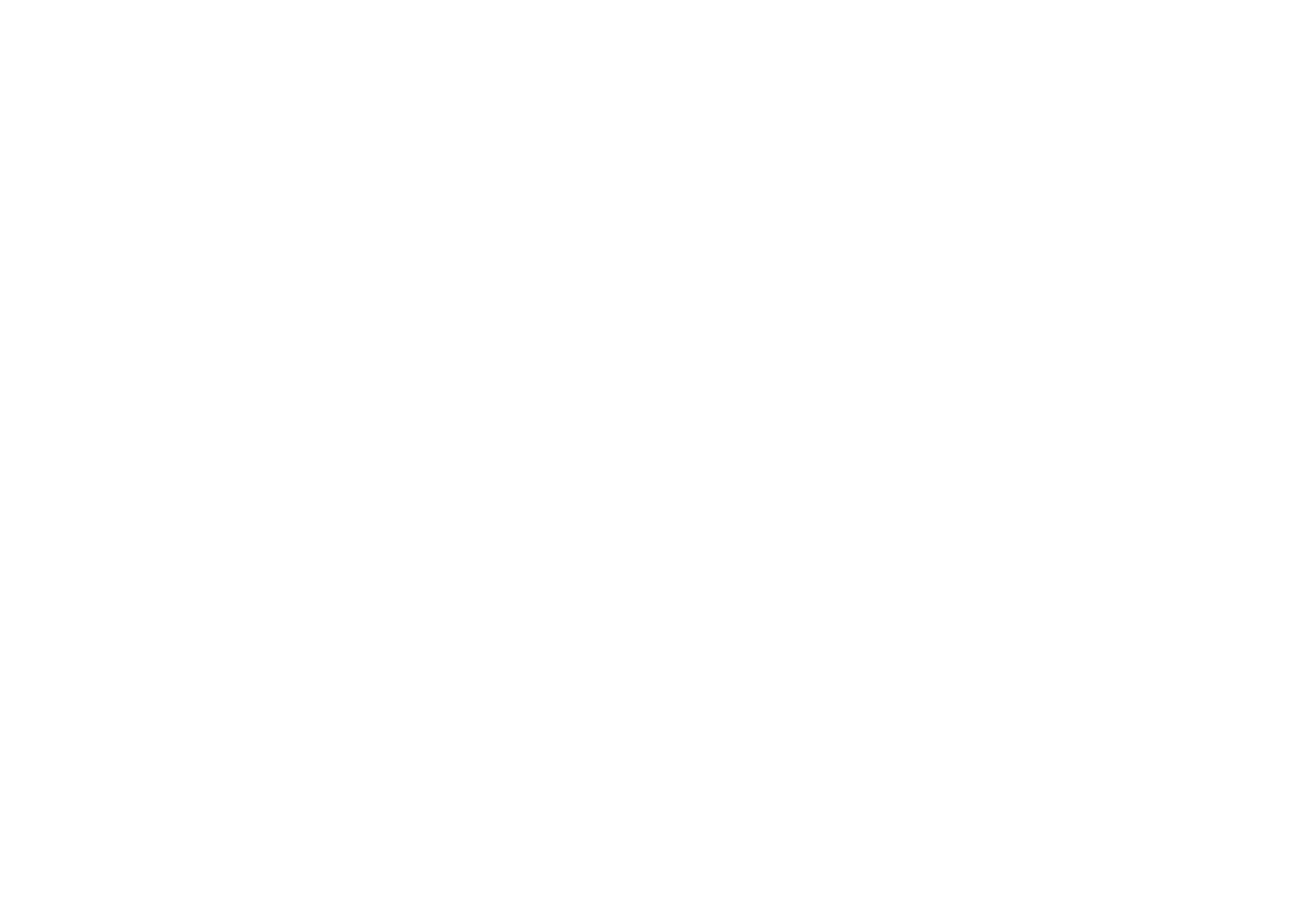Large Model
2026-04-15

BLIP 论文名称 :BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (ICML 2022) 论文地址: https://arxiv.org/pdf/2201.12086.pdf 代码地址: https://github.com/salesforce/BLIP 官方解读博客: https://blog.salesforceairesearch.com/blip-bootstrapping-language-image-pretraining/ 背景和动机 视觉语言训练 (Vision-Language Pre-training, VLP) 最近在各种多模态下游任务上取得了巨大的成功。然而,现有方法有两个主要限制: 模型层面: 大多数现有的预训练模型仅在基于理解的任务或者基于生成的任务方面表现出色,很少有可以兼顾的模型。比如,基于编码器的模型,像 CLIP,ALBEF 不能直接转移到文本生成任务...