引言与背景
策略梯度方法是强化学习中的一种重要方法,它标志着从基于价值的方法向基于策略的方法的重要转变。之前我们主要讨论了基于价值的方法(value-based),而策略梯度方法则直接优化策略函数(policy-based),这是一个重要的进步。
当策略用函数表示时,策略梯度方法的核心思想是通过优化某些标量指标来获得最优策略。与传统的表格表示策略不同,策略梯度方法使用参数化函数 来表示策略,其中 是参数向量。这种表示方法也可以写成其他形式,如 、 或 。
策略梯度方法具有多种优势:
- 更高效地处理大型状态/动作空间
- 具有更强的泛化能力
- 样本使用效率更高
策略表示:从表格到函数
当策略的表示从表格转变为函数时,存在以下几个关键区别:
- 最优策略的定义:
- 策略更新方式:
- 获取动作概率:
下面两张图展示了表格和函数表示策略的区别

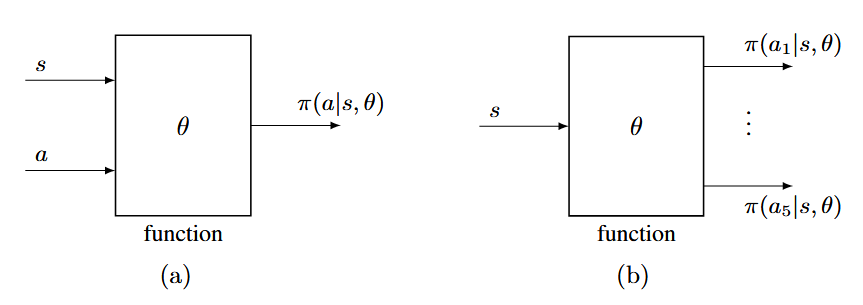
策略函数可以有不同的结构形式(如上图所示):
- 输入状态和动作 ,输出选择该动作的概率
- 输入状态 ,输出所有动作的概率分布
策略梯度法的基本思想总结如下。假设 是一个标量度量。可以通过基于梯度的算法优化此指标来获得最佳策略:
定义最优策略的指标
策略梯度方法使用两类主要指标来定义最优策略
平均状态值
平均状态值定义为:
其中 是状态 的权重,满足 且 ,因此可以将 解释为状态 的概率分布。
状态分布 的选择有两种情况:
- 独立于策略 ** 的分布**:
- 依赖于策略 ** 的分布**:
我们的最终目标是找到一个最优策略(或等效的最优 )来最大化 。
平均状态值有两个重要的等价表达式:
- 收集奖励的期望:
- 向量内积形式:
平均奖励
第二个指标称为 average one-step reward 或者简单称为 平均奖励(average reward),定义为:
其中 是稳定态分布,
是即时奖励的期望,
平均奖励也有两个等价表达式:
- 单步奖励的长期平均:假设agent根据策略 收集了奖励 ,一种在论文中很常见的指标是:
- 向量内积形式:
两个指标之间的关系
指标的等价性
在折扣情况下(),两个主要指标 * 和 * 是等价的,它们之间存在以下关系:
这个等式表明这两个指标可以同时最大化。也就是说,最大化平均状态值 * 的策略也会最大化平均奖励 *,反之亦然。这个等式的证明在后面的引理给出。
指标的不同表达式
下表总结了 * 和 * 这两个指标的不同但等价的表达式:
这些不同的表达式提供了对这些指标的不同理解视角:
- 表达式1展示了指标作为状态值或即时奖励的加权平均
- 表达式2将指标表示为期望形式
- 表达式3将指标与长期累积奖励联系起来
这里还有几点值得说明的是:
- 我们有时使用 * 特指状态分布为稳态分布 * 的情况,而使用 指代状态分布 独立于策略 的情况。这种区分在推导梯度时很重要,因为不同的状态分布会导致不同的梯度表达式。
- 所有这些指标都是策略 的函数。由于策略 由参数 参数化,因此这些指标都是 的函数。换句话说,不同的 值会生成不同的指标值。因此,我们可以搜索最优的 值来最大化这些指标。这就是策略梯度方法的基本思想。
- 策略梯度方法的核心是将策略性能指标表示为参数 的函数,然后通过优化 来最大化这些指标。这些指标虽然表达形式不同,但在本质上是等价的,都衡量了策略的长期性能。
策略梯度定理
策略梯度定理是本文最重要的理论结果,它给出了目标函数 的梯度:
策略梯度定理: 的梯度为
关于策略梯度定理的几点重要说明:
- 该定理是一个总结所有情况(定理1,2,3)的统一的结论,包含处理不同指标和折扣/非折扣情况的不同场景。
- 为什么 (8)式 可以转换成 (9)式,证明如下:根据期望的定义,(8)式可以重写为:
- 策略 必须对所有 为正,以确保 有效。这可以通过使用 softmax 函数实现:
- 由于 ,策略是随机的,因此具有探索性。策略不直接告诉采取哪个动作,而是根据策略的概率分布生成动作。
🧾 ****
蒙特卡罗策略梯度(REINFORCE)
有了策略梯度定理,我们可以使用梯度上升算法来最大化目标函数 :
其中 是学习率。
由于真实梯度未知,我们可以用随机梯度替代:
其中 是 的近似值。如果 通过蒙特卡罗估计获得,该算法称为REINFORCE或蒙特卡罗策略梯度。

这个算法非常重要,因为许多其他策略梯度算法都可以通过扩展它来获得。接下来,我们更仔细地解释这个算法。
由于 ,我们可以将(13)式 重写为:
令 ,上式可以简洁地写为:
从这个重写的形式中,可以得出两个重要解释:
- 策略概率的调整
- 探索与利用的平衡
采样问题
由于(13)使用样本来近似(12)中的真实梯度,理解样本应该如何获取非常重要:
- 状态S的采样
- 动作A的采样
然而,在实践中,由于样本使用效率低,这些理想的采样方式通常不被严格遵循。算法9.1提供了一种更高效的实现方式,先生成一个完整episode,然后使用episode中的每个样本多次更新 。