引言与背景
价值函数方法是强化学习中的核心技术,它解决了传统表格方法在处理大型状态或动作空间时的效率问题。本文探讨了从表格表示向函数表示的转变,这是强化学习算法发展的重要里程碑。
在强化学习的发展路径中,价值函数方法位于从基于模型到无模型、从表格表示到函数表示的演进过程中。它结合了时序差分学习的思想,并通过函数近似技术来处理复杂环境。
价值表示:从表格到函数
表格与函数表示的对比
传统的表格方法将状态值存储在一个表格中:
状态 | \(s_1\) | \(s_2\) | \(\cdots\) | \(s_n\) |
|---|---|---|---|---|
估计值 | \(\hat{v}(s_1)\) | \(\hat{v}(s_2)\) | \(\cdots\) | \(\hat{v}(s_n)\) |
而函数近似方法则使用参数化函数来表示这些值,例如:
其中 \(\phi(s)\in\mathbb{R}^2\) 称作是状态 \(s\) 的特征向量,\(w\) 是参数向量。
两种不同的表现形式的区别主要体现在以下几个方面:
- 值的检索方式
表格方法:直接从表中读取对应条目
函数方法:将状态输入函数并计算函数值(如计算 \(\phi^T(s)w\) 或通过神经网络前向传播)
优劣势:函数的方式只需存储低维参数向量而非完整值表,从基本角度来看,当我们使用低维向量来表示高维数据集时,肯定会丢失一些信息。因此,函数逼近方法通过牺牲精度来提高存储效率。 - 值的更新方式
表格方法:直接重写表中对应条目
函数方法:更新参数向量 \(w\) 来间接改变值
优劣势:它的泛化能力比表格法强。原因如下:使用表格方法时,如果在一个episode中访问了相应的 state,我们可以更新一个值。无法更新未访问的状态的值。但是,当使用函数近似方法时,我们需要更新 \(w\) 以更新状态的值。\(w\) 的更新也会影响其他一些状态的值,即使尚未访问这些状态。因此,一个状态的经验样本可以泛化以帮助估计其他一些状态的值。下图给出了一个具体的示例来帮助我们理解: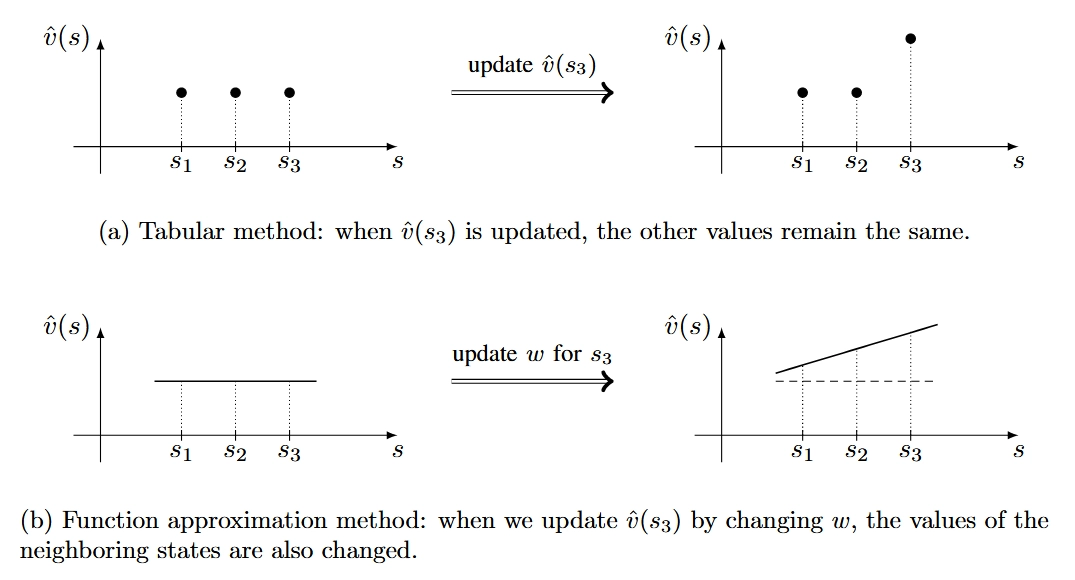
函数复杂度与近似能力
函数的复杂度决定了其近似的能力:
- 一阶线性函数:\(\hat{v}(s, w) = as + b = [s, 1]^T[a, b]^T= \phi^T(s)w\)
- 二阶多项式:\(\hat{v}(s, w) = as^2 + bs + c = [s^2, s, 1]^T[a, b, c]^T= \phi^T(s)w\)
随着函数阶数增加,近似精度提高,但参数向量维度也增加,需要更多存储和计算资源。
值得注意的是,上面两个例子中的 \(\hat{v}(s, w)\) 对于 \(w\) 来说是线性的(尽管对于 \(s\) 可能是非线性的)。这种类型的方法称为线性函数逼近(linear function approximation),这是最简单的函数逼近方法。
那么还有一个问题是如何求解最优参数向量呢,当我们已知真实状态值 \(\{v_\pi(s_i)\}_{i=1}^n\),寻找最优参数向量 \(w\) 就转化为一个标准的最小二乘问题。我们需要优化以下目标函数:
这个目标函数衡量的是函数近似值与真实值之间的平方误差总和。我们希望找到一个参数向量 \(w\),使得这个误差最小化。
上述目标函数可以用矩阵形式更简洁地表示:
其中:
- \(\Phi = \begin{bmatrix} \phi^T(s_1) \\ \vdots \\ \phi^T(s_n) \end{bmatrix} \in \mathbb{R}^{n \times d}\) 是特征矩阵,每一行是一个状态的特征向量
- \(v_\pi = \begin{bmatrix} v_\pi(s_1) \\ \vdots \\ v_\pi(s_n) \end{bmatrix} \in \mathbb{R}^n\) 是真实状态值向量
- \(d\) 是特征向量的维度(在例子中是2)
这个最小二乘问题的最优解有一个闭式解:
在实际的强化学习算法中,我们通常无法直接计算这个闭式解,因为我们不知道真实值 \(v_\pi\)。相反,我们使用时序差分学习等方法来迭代地近似这个解,这将在后续中详细介绍。
基于函数近似的时序差分(TD)
目标函数
基于函数近似的TD learning旨在最小化以下目标函数:
其中期望是相对于随机变量 \(S \in \mathcal{S}\) 计算的。
这个目标函数可以基于不同的状态分布来定义:
- 均匀分布:
将所有状态都视为同样重要的情况可能是不合理的。
- 稳态分布:\(J(w) = \sum_{s \in \mathcal{S}}d_\pi(s)(v_\pi(s) - \hat{v}(s, w))^2\)
其中 \(d_\pi(s)\)是策略 \(\pi\) 下马尔可夫过程的稳态分布,表示长期运行后agent位于状态 \(s\) 的概率。
稳态分布描述了马尔可夫决策过程的长期行为。幸运的是,我们不需要计算 \(d_\pi(s)\) 的特定值即可最大程度地最小化此目标函数,将在下一个小节展开。
马尔可夫决策过程的稳态分布
分析稳态分布的关键工具是给定策略 \(\pi\) 下的概率转移矩阵 \(P_\pi \in \mathbb{R}^{n \times n}\)。如果状态被索引为 \(s_1, \ldots, s_n\),则 \([P_\pi]_{ij}\) **定义为智能体从状态 \(s_i\) 移动到状态 \(s_j\) 的概率。
- \(P_\pi^k\) 的解释 (\(k = 1, 2, 3, ...\))
首先,有必要理解 \(P_\pi^k\) 中元素的含义。智能体从状态 \(s_i\) 恰好使用 \(k\) 步转移到状态 \(s_j\) 的概率表示为:
其中 \(t_0\) 和 \(t_k\) 分别是初始和第 \(k\) 个时间步。
根据 \(P_\pi\) 的定义,我们有:
这意味着 \([P_\pi]_{ij}\) 是使用单步从 \(s_i\) 转移到 \(s_j\) 的概率。
接下来,考虑 \(P_\pi^2\)。可以验证:
由于 \([P_\pi]_{iq}[P\pi]_{qj}\) 是从 \(s_i\) 转移到 \(s_q\) 然后从 \(s_q\) 转移到 \(s_j\) 的联合概率,我们知道 \([P_\pi^2]_{ij}\) 是恰好使用两步从 \(s_i\) 转移到 \(s_j\) 的概率。即:
类似地,我们可以得出:
这意味着 \([P_\pi^k]_{ij}\) 是恰好使用 \(k\) 步从 \(s_i\) 转移到 \(s_j\) 的概率。
- 稳态分布的定义
设 \(d_0 \in \mathbb{R}^n\) 是表示初始时间步状态概率分布的向量。例如,如果 \(s\) 总是被选为起始状态,则 \(d_0(s) = 1\) 而 \(d_0\) 的其他元素为\(0\)。设 \(d_k \in \mathbb{R}^n\) 是从 \(d_0\) 开始经过恰好 \(k\) 步后得到的概率分布向量。那么,我们有:
这个等式表明,智能体在第 \(k\) 步访问状态 \(s_i\) 的概率等于智能体从 \(\{s_j\}_{j=1}^n\) 恰好使用 \(k\) 步转移到 \(s_i\) 的概率之和。(2)的矩阵-向量形式为:
当我们考虑马尔可夫过程的长期行为时,在某些条件下有:
其中 \(1_n = [1, \ldots, 1]^T \in \mathbb{R}^n\),\(1_n d_\pi^T\) 是一个常数矩阵,其所有行都等于 \(d_\pi^T\)。(4)成立的条件将在后面讨论。
其中最后一个等式成立是因为 \(d_0^T 1_n = 1\)。
(5)意味着状态分布 \(d_k\) 收敛到一个常数值 \(d_\pi\),这被称为极限分布。极限分布取决于系统模型和策略 \(\pi\),有趣的是,它与初始分布 \(d_0\) 无关。也就是说,无论智能体从哪个状态开始,智能体在足够长时间后的概率分布都可以由极限分布描述。
\(d_\pi\) 的值可以通过以下方式计算。对 \(d_k^T = d_{k-1}^T P_\pi\) 两边取极限得到 \(\lim_{k \rightarrow \infty} d_k^T = \lim_{k \rightarrow \infty} d_{k-1}^T P_\pi\),因此:
因此,\(d_\pi\) 是与特征值1相关的 \(P_\pi\) 的左特征向量。(6)的解称为稳态分布。它满足 \(\sum_{s \in \mathcal{S}} d_\pi(s) = 1\) 和 \(d_\pi(s) > 0\)(对于所有 \(s \in \mathcal{S}\))。\(d_\pi(s) > 0\)(而不是 \(d_\pi(s) \geq 0\))的原因将在后面解释。
- 稳态分布唯一性的条件
(6)的解 \(d_\pi\) 通常称为稳态分布,而(5)中的分布 \(d_\pi\) 通常称为极限分布。注意,(5)暗示(6),但反之不一定成立。
具有唯一稳态(或极限)分布的一般马尔可夫过程类是不可约(或正则)马尔可夫过程。下面给出一些必要的定义:
- 如果存在有限整数 \(k\) 使得 \([P_\pi^k]_{ij} > 0\),则称状态 \(s_j\) 可从状态 \(s_i\) 访问,这意味着智能体从 \(s_i\) 开始可能在有限次转移后到达 \(s_j\)。
- 如果两个状态 \(s_i\) 和 \(s_j\) 互相可访问,则称这两个状态是互通的。
- 如果所有状态都互通,则称马尔可夫过程是不可约的。换句话说,智能体从任意状态开始都可能在有限步内到达任何其他状态。数学上,这表示对于任何 \(s_i\) 和 \(s_j\),存在 \(k \geq 1\) 使得 \([P_\pi^k]_{ij} > 0\)(\(k\) 的值可能因不同的 \(i\), \(j\) 而异)。
- 如果存在 \(k \geq 1\) 使得对所有 \(i\), \(j\) 都有 \([P_\pi^k]_{ij} > 0\),则称马尔可夫过程是正则的。等价地,存在 \(k \geq 1\) 使得 \(P_\pi^k > 0\) ,其中 \(>\) 是按元素比较。因此,每个状态都可能从任何其他状态在至多 \(k\) 步内到达。正则马尔可夫过程也是不可约的,但反之不一定成立。然而,如果马尔可夫过程是不可约的且存在 \(i\) 使得 \([P_\pi]_{ii} > 0\),则它也是正则的。此外,如果 \(P_\pi^k > 0\),则对于任何 \(k' \geq k\) 都有 \(P_\pi^{k'} > 0\),因为 \(P_\pi \geq 0\)。从(5)可知,对于每个 \(s\) 都有 \(d_\pi(s) > 0\)。
- 可能导致唯一稳态分布的策略
一旦给定策略,马尔可夫决策过程就变成了马尔可夫过程,其长期行为由给定策略和系统模型共同决定。那么,一个重要问题是:什么样的策略可以导致正则马尔可夫过程?一般来说,答案是探索性策略,如 \(\epsilon\)-贪婪策略。这是因为探索性策略在任何状态下采取任何动作的概率都是正的。因此,当系统模型允许时,状态可以互相通信。
- 稳态分布示例
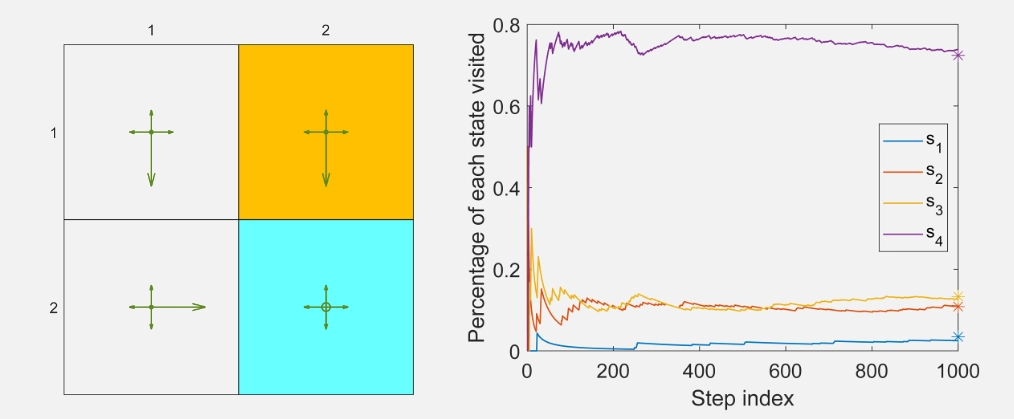
上图展示了一个稳态分布的例子。该例中的策略是 $\epsilon$-贪婪策略,$\epsilon = 0.5$。状态索引为 $s_1, s_2, s_3, s_4$,分别对应网格中的左上、右上、左下和右下单元格。
我们比较两种计算稳态分布的方法:
- 第一种方法是解(6)得到 \(d_\pi\) 的理论值。
- 第二种方法是数值估计 \(d_\pi\):从任意初始状态开始,按照给定策略生成足够长的轨迹。然后,\(d_\pi\) 可以通过轨迹中每个状态被访问的次数与轨迹总长度之比来估计。轨迹越长,估计结果越准确。
理论计算结果显示:\(d_\pi = [0.0345, 0.1084, 0.1330, 0.7241]^T\)。
数值估计结果:选择 \(s_1\) 作为起始状态,按照策略运行1,000步。过程中每个状态的访问比例如图所示。可以看出,这些比例在数百步后收敛到 \(d_\pi\) 的理论值。
优化算法
为了最小化(1)中的目标函数 \(J(w)\),可以使用梯度下降算法:
使用随机梯度下降,得到:
由于真实值 \(v_\pi(s_t)\) 未知,可以使用以下替代:
- 蒙特卡洛方法:使用回报 \(g_t\) 作为 \(v_\pi(s_t)\) 的近似
- 时序差分方法:使用 \(r_{t+1} + \gamma\hat{v}(s_{t+1}, w_t)\) ,即 TD target 作为 \(v_\pi(s_t)\) 的近似
因此,TD学习更新规则为:
在线性情况下(\(\hat{v}(s, w) = \phi^T(s)w\)),此时更新规则简化为:
函数近似下的TD learning 算法伪代码如下:

- 线性函数近似
线性函数近似使用特征向量 \(\phi(s) \in \mathbb{R}^m\) 来表示状态:
其中 \(\phi(s)\) 和 \(w\) 的长度等于 \(m\),通常远小于状态数量。
值得注意的是,表格TD学习是TD-线性算法的特例。当特征向量选为 \(\phi(s) = e_s \in \mathbb{R}^n\)(其中 \(e_s\) 是对应于 \(s\) 的单位向量)时,TD-线性算法退化为表格TD算法。
- 特征向量类型
- 多项式特征:
- 一阶:\(\phi(s) = [1, x, y]^T \in \mathbb{R}^3\)
- 二阶:\(\phi(s) = [1, x, y, x^2, y^2, xy]^T \in \mathbb{R}^6\)
- 三阶:\(\phi(s) = [1, x, y, x^2, y^2, xy, x^3, y^3, x^2y, xy^2]^T \in \mathbb{R}^{10}\)
- 傅里叶基函数:
- \(\phi(s) = [...\cos\pi(c_1x + c_2y)...] \in \mathbb{R}^{(q+1)^2}\)
- 其中 \(c_1, c_2 \in \{0,1,...,q\}\),\(q\) 是用户指定的整数
特征向量维度越高,近似能力越强,但计算复杂度也越高。
理论分析
收敛性分析
TD算法的收敛性可以通过分析以下确定性算法来研究:
(10)可以看作是(11)的 SGD实现,这个式子初看起来比较复杂,实际非常简单,我们可以做一些简化,
其中 \(\Phi\) 是包含所有特征向量的矩阵,\(D\) 是对角阵,其对角线是稳态分布。这两个矩阵将经常使用。
(11)可以重写为:
其中:
- \(A = \Phi^T D(I - \gamma P_\pi)\Phi \in \mathbb{R}^{m \times m}\)
- \(b = \Phi^T Dr_\pi \in \mathbb{R}^m\)
证明可以参考Mathematical Foundations of Reinforcement Learning中的Box 8.3
此时,(11)可以写为
这是一个简单的确定性过程,其收敛性分析如下。
首先,\(w_t\) 的收敛值是什么?假设当 \(t \rightarrow \infty\) 时,\(w_t\) 收敛到一个常数值 \(w^*\),那么根据 (12):
这表明 \(b - Aw^* = 0\),因此:
关于这个收敛值,有几点重要的说明:
- 矩阵A的可逆性
问题:\(A\) 是否可逆?
答案:是的。实际上,\(A\) 不仅可逆,而且是正定的。也就是说,对于任何具有适当维度的非零向量 \(x\),都有 \(x^T Ax > 0\)。证明参考 Mathematical Foundations of Reinforcement Learning中box 8.4。 - \(w^* = A^{-1}b\) 的解释
\(w^* = A^{-1}b\) 实际上是最小化投影贝尔曼误差的最优解。详细内容将在后文中介绍。
- 表格方法是个特例
一个有趣的结果是,当 \(w\) 的维度等于 \(n = |S|\) 且 \(\phi(s) = [0, \ldots, 1, \ldots, 0]^T\)(其中对应于 \(s\) 的条目为\(1\))时,我们有:
这个等式表明,要学习的参数向量实际上就是真实的状态值。这个结论与表格TD算法是TD-线性算法的特例这一事实一致
(14)的证明如下:在这种情况下,可以验证 \(\Phi = I\),因此:
因此:
其次,我们证明 (13) 中的 \(w_t\) 当 \(t \rightarrow \infty\) 时收敛到 \(w^* = A^{-1}b\)。由于 (13) 是一个简单的确定性过程,可以通过多种方式证明。我们提供两种证明:
- 证明1:收敛误差分析
定义收敛误差为 \(\delta_t = w_t - w^*\)。我们只需要证明 \(\delta_t\) 收敛到零。
将 \(w_t = \delta_t + w^*\)代入 (13)得:
由此得出:
考虑简单情况,其中对所有 $t$ 都有 \(\alpha_t = \alpha\)。则:
当 \(\alpha > 0\) 足够小时,我们有 \(\|I - \alpha A\|_2 < 1\),因此当 \(t \rightarrow \infty\) 时 \(\delta_t \rightarrow 0\)。\(\|I - \alpha A\|_2 < 1\) 成立的原因是 \(A\) 是正定的,因此对于任何 \(x\) 都有 \(x^T(I - \alpha A)x < 1\)。
- 证明2:Robbins-Monro算法
考虑 \(g(w) = b - Aw\)。由于 \(w^*\) 是 \(g(w) = 0\) 的根,因此这实际上是一个寻根问题。 (13)中的算法实际上是一个Robbins-Monro (RM)算法。
虽然原始的RM算法是为随机过程设计的,但它也可以应用于确定性情况。RM算法的收敛性可以说明 \(w_{t+1} = w_t + \alpha_t(b - Aw_t)\) 的收敛性。即,当 \(\sum_t \alpha_t = \infty\) 且 \(\sum_t \alpha_t^2 < \infty\) 时,\(w_t\) 收敛到 \(w^*\)。
这种收敛性分析表明,TD-线性算法在适当条件下会收敛到最优参数值,这个参数值不仅能够最小化投影贝尔曼误差,而且在特殊情况下(表格表示)恰好等于真实状态值。
TD Learning与投影贝尔曼误差(projected Bellman error)
我们之前已经证明TD-线性算法收敛到 \(w^* = A^{-1}b\),接下来我们将证明 \(w^*\) 是最小化投影贝尔曼误差的最优解。为此,我们回顾三种目标函数。
- 状态值误差
第一个目标函数是:
这已在(1)中介绍过。根据期望的定义,\(J_E(w)\) 可以用矩阵-向量形式重新表示为:
其中 \(v_\pi\) 是真实状态值向量,\(\hat{v}(w)\) 是近似值。这里,\(\|\cdot\|^2_D\) 是加权范数:\(\|x\|^2_D = x^T D x = \|D^{1/2}x\|^2_2\),其中 \(D\) 已经在(12)中给出。
这是讨论函数近似时能想到的最简单的目标函数。然而,它依赖于未知的真实状态值。为了获得可实现的算法,我们必须考虑其他目标函数,如贝尔曼误差和投影贝尔曼误差。
- 贝尔曼误差
第二个目标函数是贝尔曼误差。特别地,由于 \(v_\pi\) 满足贝尔曼方程 \(v_\pi = r_\pi + \gamma P_\pi v_\pi\),预期估计值 \(\hat{v}(w)\) 也应尽可能满足这个方程。因此,贝尔曼误差为:
这里,\(\mathcal{T}_\pi(\cdot)\) 是贝尔曼算子。具体来说,对于任何向量 \(x \in \mathbb{R}^n\),贝尔曼算子定义为:
最小化贝尔曼误差是一个标准的最小二乘问题,其解决方案细节在此省略。
- 投影贝尔曼误差
值得注意的是,由于函数近似器的近似能力有限,\(J_{BE}(w)\) 可能无法最小化到零。相比之下,可以最小化到零的目标函数是投影贝尔曼误差:
其中 \(M \in \mathbb{R}^{n \times n}\) 是正交投影矩阵,它在几何上将任何向量投影到所有可能近似的空间上。
实际上,TD学习算法(9)旨在最小化投影贝尔曼误差 \(J_{PBE}\),而非 \(J_E\) 或 \(J_{BE}\)。原因如下:
为简单起见,考虑线性情况,其中 \(\hat{v}(w) = \Phi w\)。这里,\(\Phi\) 在(12)中定义。\(\Phi\) 的值域是所有可能线性近似的集合。那么:
是将任何向量几何投影到 \(\Phi\) 值域上的投影矩阵。
由于 \(\hat{v}(w)\) 在 \(\Phi\) 的值域中,我们总能找到一个 \(w\) 值使 \(J_{PBE}(w)\) 最小化到零。可以证明,最小化 \(J_{PBE}(w)\) 的解是 \(w^* = A^{-1}b\)。即:
证明 \(w^ = A^{-1}b\) 最小化投影贝尔曼误差
我们接下来证明 \(w^* = A^{-1}b\) 是最小化投影贝尔曼误差 \(J_{PBE}(w)\) 的最优解。
由于 \(J_{PBE}(w) = 0 \Leftrightarrow \hat{v}(w) - M\mathcal{T}_\pi(\hat{v}(w)) = 0\),我们只需要研究以下方程的根:
在线性情况下,将 \(\hat{v}(w) = \Phi w\) 和 \(M\) 的表达式代入上述方程得到:
由于 \(\Phi\) 具有满列秩,我们有 \(\Phi x = \Phi y \Leftrightarrow x = y\)(对于任意 \(x, y\))。因此,(16)意味着:
这个等式可以通过以下步骤进行变换:
其中 \(A, b\) 在(15)中给出. 因此,\(w^* = A^{-1}b\) 是最小化 \(J_{PBE}(w)\) 的最优解。
由于TD算法旨在最小化 \(J_{PBE}\) 而非 \(J_E\),自然要问估计值 \(\hat{v}(w)\) 与真实状态值 \(v_\pi\) 的接近程度。在线性情况下,最小化投影贝尔曼误差的估计值是 \(\hat{v}(w^*) = \Phi w^*\)。它与真实状态值 \(v_\pi\) 的偏差满足:
这个不等式的证明在Mathematical Foundations of Reinforcement Learning中的Box 8.6中给出。
(17)表明 \(\Phi w^*\) 与 \(v_\pi\) 之间的差距上界是 \(J_E(w)\) 的最小值。然而,这个界限较松,特别是当 \(\gamma\) 接近1时。因此,它主要具有理论价值。
最小二乘时序差分(LSTD)
接下来我们介绍一种称为最小二乘时序差分(LSTD)的算法。与TD-线性算法一样,LSTD旨在最小化投影贝尔曼误差。然而,它比TD-线性算法有一些优势。
回顾最小化投影贝尔曼误差的最优参数是 \(w^* = A^{-1}b\),其中 \(A = \Phi^T D(I - \gamma P_\pi)\Phi\) 和 \(b = \Phi^T Dr_\pi\)。实际上,\(A\) 和 \(b\) 也可以写为(参考Mathematical Foundations of Reinforcement LearningBox 8.1):
上面两个等式表明 \(A\) 和 \(b\) 是 \(s_t\), \(s_{t+1}\), \(r_{t+1}\) 的期望。LSTD的思想很简单:如果我们可以使用随机样本直接获得 \(A\) 和 \(b\) 的估计值(分别记为 \(\hat{A}\) 和 \(\hat{b}\)),那么最优参数可以直接估计为 \(w^* \approx \hat{A}^{-1}\hat{b}\)。
具体来说,假设 \((s_0, r_1, s_1, \ldots, s_t, r_{t+1}, s_{t+1}, \ldots)\) 是通过遵循给定策略 \(\pi\) 获得的轨迹。设 \(\hat{A}_t\) 和 \(\hat{b}_t\) 分别是时间 \(t\) 时 \(A\) 和 \(b\) 的估计值。它们计算为样本的平均值:
然后,估计的参数为:
读者可能会疑惑 (18) 右侧是否缺少系数 \(1/t\)。实际上,为简单起见,它被省略了,因为省略时 \(w_t\) 的值保持不变。由于 \(\hat{A}_t\) 可能不可逆(特别是当 \(t\) 较小时),通常对 \(\hat{A}_t\) 添加一个小常数矩阵 \(\sigma I\),其中 \(I\) 是单位矩阵,\(\sigma\) 是一个小正数。
LSTD的优缺点
LSTD的优势在于它更有效地利用经验样本,比TD方法收敛更快。这是因为该算法是基于最优解表达式的知识专门设计的。我们对问题理解得越好,就能设计出越好的算法。
LSTD的缺点如下:
- 它只能估计状态值。相比之下,TD算法可以扩展到估计动作值,如下一节所示。此外,虽然TD算法允许非线性近似器,但LSTD不允许。这是因为该算法是基于 \(w^*\) 的表达式专门设计的。
- LSTD的计算成本高于TD,因为LSTD在每个更新步骤中更新一个 \(m \times m\) 矩阵,而TD更新一个 \(m\) 维向量。更重要的是,在每一步中,LSTD需要计算 \(\hat{A}_t\) 的逆,其计算复杂度为 \(O(m^3)\)。
递归实现
解决计算复杂度问题的常用方法是直接更新 \(\hat{A}_t\) 的逆,而不是更新 \(\hat{A}_t\)。具体来说,\(\hat{A}_{t+1}\)可以递归计算如下:
上面的表达式将 \(\hat{A}_{t+1}\) 分解为两个矩阵的和。其逆可以计算为:
因此,我们可以直接存储和更新 \(\hat{A}_t^{-1}\) 以避免计算矩阵逆。这种递归算法不需要步长。然而,它需要设置 \(\hat{A}_0^{-1}\) 的初始值。这种递归算法的初始值可以选为 \(\hat{A}_0^{-1} = \sigma I\),其中 \(\sigma\) 是一个正数。
基于函数近似的动作值学习
Sarsa算法
将TD学函数近似拓展到动作值估计,得到基于函数近似的Sarsa算法:
在线性情况下,\(\hat{q}(s, a, w) = \phi^T(s, a)w\),其中 \(\phi(s, a)\) 是状态-动作对的特征向量。
Sarsa算法结合策略改进步骤可以学习最优策略:
- 值估计:更新 \(w\) 以估计当前策略的动作值
- 策略改进:基于更新后的动作值,使用 \(\epsilon\)-贪婪策略选择动作

Q-learning算法
基于函数近似的Q-learning更新规则为:
与Sarsa的区别在于使用 \(\max_{a\in A(s_{t+1})}\hat{q}(s_{t+1}, a, w_t)\) 替代 \(\hat{q}(s_{t+1}, a_{t+1}, w_t)\)。
Q-learning可以以在线或离线方式实现,适用于各种函数近似器,包括线性函数和神经网络。这里给出了on-policy版本的伪代码

Deep Q-Learning(DQN)
Q-learning 或 deep Q-network (DQN) 是最早和最成功的深度强化学习算法之一。值得注意的是,神经网络不必很深。对于简单的任务,例如我们的 grid world 示例,具有一个或两个隐藏层的浅层网络可能就足够了。 DQN可以看作是 (20) 中算法的扩展。但是,它的数学公式和实现技术大不相同,值得特别关注。
目标函数
从数学角度看,深度Q-Learning旨在最小化以下目标函数:
其中 \((S, A, R, S')\) 是随机变量,分别表示状态、动作、即时奖励和下一个状态。这个目标函数可以视为贝尔曼最优性方程的平方误差。
这是因为贝尔曼最优性方程为:
因此,当 \(\hat{q}(S, A, w)\) 能够准确近似最优动作值时,\(R + \gamma \max_{a\in A(S')}\hat{q}(S', a, w) - \hat{q}(S, A, w)\) 在期望意义上应该等于零。
梯度下降优化
为了最小化(21)中的目标函数,我们可以使用梯度下降算法。为此,我们需要计算 \(J\) 关于 \(w\) 的梯度。
需要注意的是,参数 \(w\) 不仅出现在 \(\hat{q}(S, A, w)\) 中,还出现在 \(y \stackrel{.}{=} R + \gamma \max_{a\in A(S')}\hat{q}(S', a, w)\) 中。因此,计算梯度并不简单。
为了简化计算,我们假设 \(y\) 中的 \(w\) 值是固定的(在短时间内),这样计算梯度就变得容易得多。具体来说,我们引入两个网络:一个是表示 \(\hat{q}(s, a, w)\) 的主网络,另一个是目标网络 \(\hat{q}(s, a, w_T)\)。在这种情况下,目标函数变为:
其中 \(w_T\) 是目标网络的参数。当 \(w_T\) 固定时,\(J\) 的梯度为:
这里为了简洁,省略了一些常数系数。
关键技术
要使用(22)中的梯度来最小化目标函数,我们需要注意以下几个技术要点:
双网络架构
第一个技术是使用两个网络:主网络和目标网络,如前面计算梯度时提到的。实现细节如下:
- 设 \(w\) 和 \(w_T\) 分别表示主网络和目标网络的参数。它们最初被设置为相同的值。
- 在每次迭代中,我们从回放缓冲区(稍后会解释)中抽取一个小批量样本 \(\{(s, a, r, s')\}\)。
- 主网络的输入是 \(s\) 和 \(a\)。输出 \(y = \hat{q}(s, a, w)\) 是估计的 \(q\) 值。
- 输出的目标值是 \(y_T \stackrel{.}{=} r + \gamma \max_{a\in A(s')}\hat{q}(s', a, w_T)\)。
- 主网络通过最小化样本 \(\{(s, a, y_T)\}\) 上的TD误差(也称为损失函数)\(\sum(y - y_T)^2\) 来更新。
更新主网络中的 \(w\) 不是显式使用(22)中的梯度,而是依赖于现有的神经网络训练软件工具。因此,我们需要一个小批量样本来训练网络,而不是基于(22)使用单个样本更新主网络。这是深度强化学习算法与非深度强化学习算法的一个显著区别。
主网络在每次迭代中都会更新。相比之下,目标网络每隔一定数量的迭代才会被设置为与主网络相同,以满足计算(22)中梯度时 \(w_T\) 固定的假设。
经验回放(experience replay)
第二个技术是经验回放。也就是说,在收集了一些经验样本后,我们不按照收集的顺序使用这些样本。相反,我们将它们存储在一个称为回放缓冲区的数据集中。
具体来说,设 \((s, a, r, s')\) 为一个经验样本,\(B \stackrel{.}{=} \{(s, a, r, s')\}\) 为回放缓冲区。每次更新主网络时,我们可以从回放缓冲区中抽取一个小批量经验样本。样本的抽取,或称为经验回放,应遵循均匀分布。
为什么深度Q学习中需要经验回放,为什么回放必须遵循均匀分布?答案在于(21)式中的目标函数。具体来说,为了很好地定义目标函数,我们必须指定 \(S\), \(A\), \(R\), \(S'\) 的概率分布。一旦给定 \((S, A)\),系统模型就确定了 \(R\) 和 \(S'\) 的分布。描述状态-动作对 \((S, A)\) 分布的最简单方法是假设它服从均匀分布。
然而,在实践中,状态-动作样本可能不是均匀分布的,因为它们是根据行为策略作为样本序列生成的。为了满足均匀分布的假设,有必要打破序列中样本之间的相关性。为此,我们可以使用经验回放技术,从回放缓冲区中均匀抽取样本。这就是为什么经验回放是必要的,以及为什么经验回放必须遵循均匀分布的数学原因。
随机抽样的一个好处是每个经验样本可能被多次使用,这可以提高数据效率。这在我们只有有限数量的数据时尤为重要。
深度Q学习的实现过程总结在下面伪代码中。这种实现是离线策略的。如果需要,也可以将其调整为在线策略。

性能与特点
深度Q学习相比传统方法具有显著优势:
- 数据效率高:相同数量的经验样本可以获得更好的策略
- 泛化能力强:能够处理未见过的状态
- 适用于复杂环境:可以处理高维状态空间
然而,当经验样本不足时,即使损失函数收敛到零,状态值估计误差也可能无法收敛,表明网络可以拟合给定样本但样本不足以准确估计最优动作值。