DINO
Emerging Properties in Self-Supervised Vision Transformers
DINO摇摆到了动量式更新,果然【加动量】还是比【只用梯度停止】香。DINO的名字来自于Self-distillation with no labels中的蒸馏和No标签。
DINO的训练步骤
其实以前的对比学习方案也可以理解为知识蒸馏,DINO里更具体得描述了知识蒸馏的含义。
下图展示了一个样本通过数据增强得到一对views \((x_1,x_2)\) 。注意DINO后面还会使用更复杂的裁剪和对比方案,但这里简单起见先不考虑那些。模型将输入图像的两种不同的随机变换 \(x_1\) 和 \(x_2\) 分别传递给学生和教师网络。这两个网络具有相同的架构,但参数不同。教师网络的输出以batch内计算的平均值,进行中心化(减去均值)。每个网络输出一个 \(K\) 维特征,该特征在特征维度上用温度softmax(使用温度参数的softmax,后面再解释)进行归一化。然后用交叉熵损失来衡量它们的相似性。对教师模型使用梯度停止(sg),仅传播学生模型的梯度。教师模型的参数用学生模型的参数的指数移动平均值(EMA)更新。
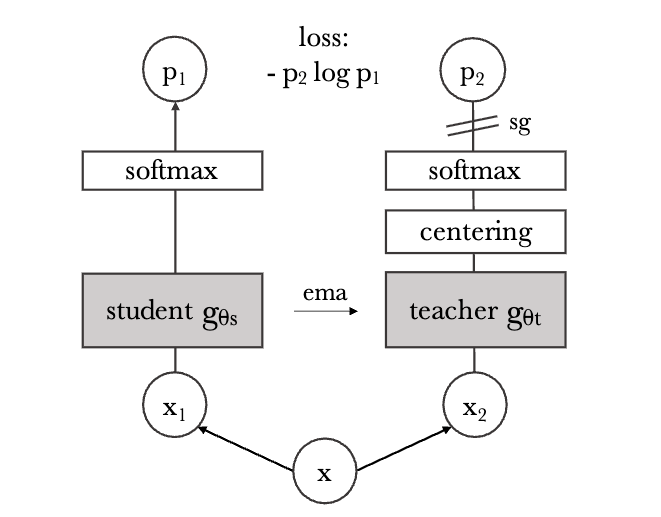
把ViT的class token [CLS]( \(K\) 维)的输出接上一个projection head \(h\) ,作为网络输出的特征。
伪代码:
# gs, gt: student and teacher networks
# C: center (K)
# tps, tpt: student and teacher temperatures
# l, m: network and center momentum rates
gt.params = gs.params
for x in loader: # load a minibatch x with n samples
x1, x2 = augment(x), augment(x) # random views
s1, s2 = gs(x1), gs(x2) # student output n-by-K
t1, t2 = gt(x1), gt(x2) # teacher output n-by-K
loss = H(t1, s2)/2 + H(t2, s1)/2
loss.backward() # back-propagate
# student, teacher and center updates
update(gs) # SGD
gt.params = l*gt.params + (1-l)*gs.params
C = m*C + (1-m)*cat([t1, t2]).mean(dim=0)
def H(t, s):
t = t.detach() # stop gradient
t = softmax((t - C) / tpt, dim=1) # center + sharpen
s = softmax(s / tps, dim=1)
return -(t * log(s)).sum(dim=1).mean()我们再展示一下流程。在一个batch内,输入\(N\)张图像 \(x_0,x_1,...,x_{N-1}\) ,通过数据增强得到:\((x_0^{1},x_{0}^{2}),(x_1^{1},x_{1}^{2}),...,(x_{N-1}^{1},x_{N-1}^{2})\)
然后分别得到学生模型和教师模型的输出:
之后,计算两组loss:
注意,DINO虽然一次会使用比较大的batch size(默认1024),但是并不是使用负样本概念,仅仅只是作为训练的batch size(与MoCo-V3的本质不同)。我们还是只看first部分,理论上,我们是希望 \(s_{0}^1\) 尽可能与 \(t_0^2\) 相近; \(s_{1}^1\) 尽可能与 \(t_1^2\) 相近;以此类推。因此比较适合MSE Loss。
提一句与之前模型的区别和联系。之前讲过的BYOL和SimSaim都是计算MSE Loss,不再涉及batch内的负样本互计算。而MoCo-V3是计算余弦线性相似性,然后用交叉熵计算Loss(严谨点,叫InfoNCE Loss),这是因为加入了负样本。
但DINO却换了一种方案,计算交叉熵Loss。当然,DINO的实验里对比了使用MSE Loss和交叉熵Loss(CE Loss)的区别,发现交叉熵Loss训练效果更好(交叉熵Loss里使用了后面会提到的锐化技术,但MSE Loss里没有使用锐化)。
我们得到了 \(N\times K\) 维的 \(s\) 和 \(t\) ,然后做softmax。dim=1 就是在每个样本的特征维度( \(K\) )上分别做 softmax,每一行都独立 softmax。例如,对于 \(s_{0}^1\) 和 \(t_0^2\) 这两个 \(K\) 维向量,计算softmax以后,再计算交叉熵。
温度参数与中心化、锐化
有温度参数( \(\tau_s\) )的softmax如下,这里的温度参数大于0,用于控制softmax的形状:
代码中锐化的方法是:
t = softmax((t - C) / tpt, dim=1)实验时作者发现,tpt( \(\tau_t\) )可以设置为递增(0.04->0.07),但一开始不要太大(要低于0.06),不然会导致坍塌(见附录D)。
虽然DINO框架可以通过多种归一化来稳定,但也可以仅通过对动量教师的输出进行中心化和锐化来避免模型崩溃。中心化防止某一维度主导,但鼓励均匀分布(造成崩溃);而锐化则具有相反的效果。应用这两种操作平衡了它们的效果,足以在存在动量教师的情况下避免崩溃。
其实这里的“均匀”不是softmax意义上的输出概率分布均匀,而是指不同样本的输出向量在整个输出空间的分布均匀。论文说的“均匀”指的是“整个batch的向量分布”,即不要所有样本都指向同一个或少数几个类别、模式,否则就“坍塌”了。Centering会让所有输出的均值为0,防止所有输出都集中在某一点,间接起到“鼓励分散”的作用。但极端情况下,这种操作确实可能让网络学会分布“均匀”的输出(如全1向量、或均匀分布),但这并不代表softmax每一行都是均匀分布,而是指输出特征在空间上分散。DINO的“坍塌”不是softmax均匀分布,而是所有样本输出的特征向量非常接近(没有信息量)。
所以代码中,中心化是在维度0上进行的,得到的C是一个 \(K\) 维向量:
C = m*C + (1-m)*cat([t1, t2]).mean(dim=0)此外,选择这种避免崩溃的方法在稳定性与对batch的依赖之间进行了权衡:中心化操作仅依赖于一阶batch统计,并可以解释为对教师添加一个偏置项 \(c\) : \(g_t(x) = g_t(x) + c\) 。中心c使用指数移动平均更新,这使得该方法能够很好地适应不同的batch大小。
裁剪
一张图裁剪出的不同正样本对叫做不同的views。
这里的裁剪其实就是借鉴的SwAV(2020年6月)里的裁剪方法。首先,使用多裁剪策略构建图像的不同views,构成集合 \(V\) 。此集合包含两个全局views \(x_g^1\) 和 \(x_g^2\) 以及几个分辨率较小的局部视图 \(x_l\) 。所有views都能输入到学生模型,但只有全局views能传递到教师模型,因此鼓励“从局部到全局”的交流学习。损失函数:
默认使用分辨率为 \(224^2\) 的2个全局views,能够覆盖原始图像的大面积(例如大于50%);以及分辨率为 \(96^2\) 的几个局部views,仅覆盖原始图像中的小面积(例如小于50%)。
方法与特点总结
DINO的方法有以下特点:
- 无标签自蒸馏:用学生网络学习教师网络的输出(教师网络本身由学生的动量式更新得到),训练中不使用任何人工标签。
- 多裁剪策略:从一张图片生成多种不同视角的裁剪,包括两个大(全局)裁剪和若干较小(局部)裁剪。这跟SwAV是相同的方案。
- 局部-全局对齐:所有裁剪(local+global)输入学生网络,只有全局裁剪输入教师网络,鼓励学生能用局部看到的内容去预测全局的语义表征。
- 损失函数:用交叉熵损失函数,使学生与教师在不同视角下的预测分布一致。
- 教师权重更新:教师网络不是固定的,而是在训练过程中,由学生网络的参数做指数滑动平均(EMA,动量编码器)而成。
- 居中和锐化:通过对教师输出做居中和锐化,防止所有输出趋于均匀分布(即信息崩溃)。
本质和SimSaim没有太大区别,但是这里用学生模型去引导教师模型的更新(动量式更新),DINO这里也不再用负样本了。训练目标是“让同一张图片的不同视角在特征分布上保持一致”,而不用再去区分正样本和负样本。DINO 的目标是让学生网络所有视角的输出分布去匹配教师网络“全局视角”输出分布。
计算损失时,学生的所有输出(包括全局与局部)都被用来和教师的全局输出做一致性匹配。也就是说,每个学生“全局裁剪”都要和所有教师全局裁剪输出做一致性损失。每个学生“局部裁剪”也和教师全局裁剪做一致性损失。学生全局裁剪和教师全局裁剪对齐,有利于模型学到完整场景中的语义一致性。局部裁剪和全局裁剪对齐,让模型学会从局部推断全局、提升细粒度语义能力。这样做可以让“不同尺度、不同区域的学生输入”都学会对齐到全局语义,提升表征迁移能力和鲁棒性。
最有趣的是DINO将最后一层的CLS token进行了可视化,发现不需要任何标签,网络已经自己学到应该注意的部分:

ViT输入的第一个token是CLS token,代表整图的全局语义。取最后一层每个头的CLS token(第一个token)对其他所有token的注意力分布(即attention矩阵第0行,去掉CLS token对自己本身的注意力)。reshape成patch布局(如14x14或16x16),然后resize还原成与原图同尺寸的图,显示为热力图。也就是说,该图显示的内容相当于是“训练中网络注意到了什么信息,才能将不同图像区分开的”。
iBOT
ibot: Image bert pre-training with online tokenizer
论文地址:[2111.07832] iBOT: Image BERT Pre-Training with Online Tokenizer
字节跳动的作品。为什么讲这篇论文呢,因为它用到了DINO的思想和技术,同时DINOv2也借鉴了这篇论文,可以说是承前启后了。这篇论文是2021年11月15号提交到arxiv上的,相比之下,何恺明的MAE在11月11号就提交到了arxiv上,真是争分夺秒地你追我赶啊。之后的11月18日,微软亚洲研究院推出了SimMIM,也是类BERT的预训练方案。iBOT是这三种预训练方案中最复杂的,但因为DINO v2完全基于iBOT架构,所以我们重点介绍iBOT。
该论文提出了一种自监督框架iBOT,它能够使用在线tokenizer进行遮蔽预测。具体而言,将教师网络作为在线tokenizer,同时对class token进行自蒸馏以获取视觉语义。在线tokenizer可以与MIM(masked image modeling)目标共同学习,免去了需要预先训练tokenizer的多阶段训练流程。
iBOT就像个大杂烩,理解难度和技术要点太多——但这批大杂烩,后来又被搞到了DINO-V2上。
Masked image modeling (MIM)
论文第二节总结得挺不错,因此我打算也写一写相关概念。
把一个图像 \(x\) 打成一堆patch: \(x=\{{x_i}\}_{i=1}^{N}\) ;之后采样一个随机mask: \(m=\{ m_{i} \}_{i=1}^N\) 。mask的比率称为prediction ratio,表示为 \(r\) 。 \(m_i\) 的值可以为0或者1,为1就表示被遮住,用 \(e_{[MASK]}\) 替代原token。这个\(e_{[MASK]}\) 也是可以被学习得到的(完全可以理解为token字典里的一个词)
被Mask破坏的图像就可以记作:
对于MIM的目标(约等号表示,假设每个masked token都是可以被分开重建出来的):
在2021年一篇论文BEiT中,认为 \(q_{\theta}\) 可以被建模为类别分布(强行基于变分自编码器进行了解释),认为就是最小化:
这里的 \(P\) 就是在求分布,其实实现时就是加个softmax。 \(P_\phi\) 其实指的是某种我们认为很规范的编码结果,例如使用VQ-VAE的聚类编码结果(简单理解为是某种我们期望的编码即可)。
是不是看起来跟DINO非常像?其实就是很像。把 \(P_{\theta}\) 当成学生模型, \(P_\phi\) 当成教师模型,可不就是DINO嘛!
DINO中解释过,为什么不用MSE而是交叉熵形式。要是强行解释就是用学生网络输出的分布去逼近教师网络输出的分布;要是不解释那就是经过测试,对于对比学习这种领域,MSE Loss效果不如交叉熵。此外,iBOT的目标是比较教师模型和学生模型对patch学习到的特征,而不是恢复像素这个任务。
顺便提一句(不理解也没关系),BEiT采用的是离散标号的形式,预测当前masked patch跟哪个默认的patch字典内的token更接近(把可能的patch制作成一个字典);而iBOT采用的是类似DINO的计算Loss的方案。
iBOT的架构
下图是iBOT的训练脉络:
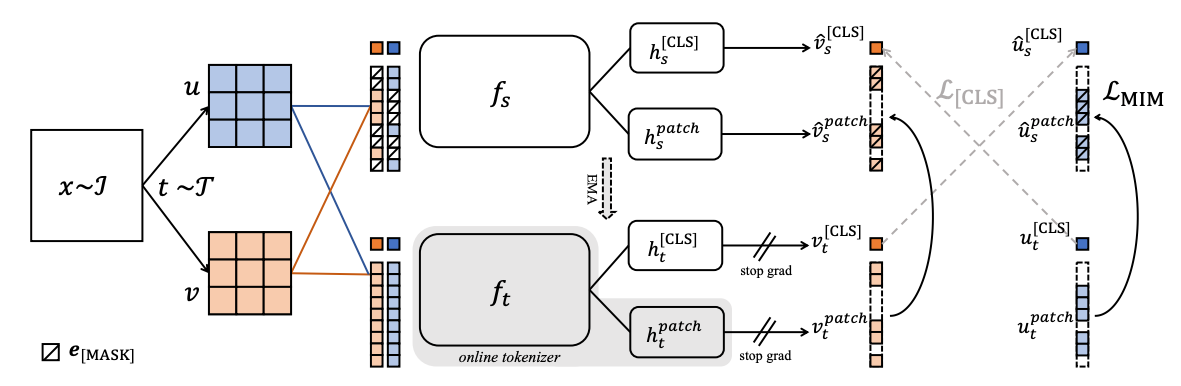
首先,将一张图增强得到两个不同的view \(u\) 和 \(v\) ,然后这两个view各自拆成patch,之后,输入给学生模型的是包含MASK的,而教师模型则不包含MASK。教师模型的参数靠学生模型平滑过去,教师模型不参与训练。之后,分别计算CLS的Loss( \(\mathcal{L}_{[CLS]}\) )和预测Loss( \(\mathcal{L}_{[MIM]}\) )。
[CLS] token采用自蒸馏损失,鼓励跨view的[CLS]互相匹配,提取语义级表征。
被掩码的patch token采用MIM(masked image modeling)损失,用教师网络输出的token分布监督学生网络重建掩码位置。
另外就是之前提到的,计算都是用信息损失的方法,而不是MSE Loss:
iBOT不是简单地还原图像的像素值,而是要让学生网络输出的 patch token 表达与教师网络输出的patch token 分布相匹配,本质上是“分布拟合”而非“数值回归”。iBOT 关注的是高层视觉语义(如图像块所属的隐含类别),而非仅仅是像素还原。KL散度/交叉熵可以促进教师网络中的语义信息充分传递给学生网络,使得自监督的表征更具有泛化能力。注意教师模型输出的token还会使用温度参数缩放,这个DINO也是一致的。
剩下的内容就不过多赘述了,有兴趣可以看看原文的实验。
现在我们把重心放在DINO-V2上。
DINO-V2
DINOv2: Learning Robust Visual Features without Supervision
论文地址:[2304.07193] DINOv2: Learning Robust Visual Features without Supervision
V2的技术贡献主要是在加速训练和稳定大规模训练上。在数据方面,提出了一种自动管线来构建一个专用的、多样化的、经过精心策划的图像数据集(增加数据分布多样性,避免其中几类数据特别多,有些类别特别少,导致训练的特征不好),而不是像其他自监督研究中通常所做的那样构建未固化的数据。在模型方面,使用1B参数训练ViT模型,并将其提取为一系列较小的模型,这些模型在图像和像素级别的大多数基准测试中都超过了最好的通用工具OpenCLIP(CLIP的开源可训练版本)。
通俗来说,这篇论文的大部分技术贡献旨在在模型和数据规模扩大时稳定和加速自监督判别学习。这些改进使DINO v2方法比类似的自监督判别方法快约2倍,并且需要的内存少3倍,从而能够利用更长的训练时间和更大的batch size。
数据搜集
首先,搜集到12亿张零散的图像。在处理未经人工挑选的图像时,一个主要的困难是重新平衡概念并避免对少数主导模式的过拟合(比如有些模式的图像特别多,例如风景图,而有些图像也别少,比如女装大佬图,图像分布不均衡会导致模型学习学不好)。
区别于以往自监督方法常用的“未筛选大数据集”,DINOv2设计了一套自动化pipeline,融合数据去重、相似性检索和多样性平衡,从未整理的图像集中挖掘与精选数据相似但又多样的图像。最终形成了LVD-142M等大规模、高质量的自监督训练集。
在这项工作中,一种简单的聚类方法合理地解决了这个问题(使得图像在各个类别上更均衡)。相似性驱动的数据筛选与聚类:结合自监督ViT预训练特征,利用k-means聚类及最近邻检索,实现无需人工标注的海量图像精选。图像去重技术:应用高效的副本检测,消除冗余,提升数据多样性。
他们用了一种叫copy detection pipeline的方法,具体参考了Pizzi等人2022年的工作。这种方法会自动检测哪些图片内容高度相似,然后把这些近似重复的图片都去掉。他们还特别把和各种测试集或验证集中内容相似的图片也排除出训练集,防止模型在评测时“见过原题”。
方法流程:
- 使用自监督模型生成embedding:用ViT-H/16模型(在ImageNet-22k大数据集上无监督预训练过),把每张图片转化成一个高维“向量”(embedding)。这个向量可以理解为图片的“内容特征”表示。
- 把原始图片的embedding做了一次聚类(k-means),把相似的图片聚成一组。然后用余弦相似度找相似图片:对于每张“高质量图片”(query,例如ImageNet这种人工选择过的图像),在未挑选的原始图片中,通过比较“向量”之间的余弦相似度,找出内容最相近的N张图片(通常是4张),注意检索时只在对应图片的组里找。
- 大数据集和小数据集策略:如果要检索的数据量大,每个query检索N个最近邻(如4张)。如果数据量小,则直接从聚类中抽取M张图片。如果N太大,可能多张query图片检索到同一张原始图片,这样会造成训练集数据分布不均。他们发现N=4在避免碰撞和检索质量之间效果最好。
预训练方案
DINO-v1的对比学习方案,比较的是对整图的特征预测,对教师和学生模型输出的[CLS] token进行对比:
这里的 \(p_s\) 是学生模型的[CLS] token再经过一个线性层投射 \(h_s\) ,然后再作用一次softmax,得到的结果。 \(p_t\) 是对应教师模型的结果,不过 \(p_t\) 在进行softmax时,会进行中心化和锐化(参考DINO-V1)。
iBOT的对比学习方案,比较的是对patch的特征预测(其实iBOT也比较了CLS token):
DINO-v2把这两个Loss都使用了,然后DINO-v2也采用了和iBOT相同的方案,仅对学生模型的输入图像进行Mask。[CLS]token的投射头和patch的投射头都是将学生模型的指数移动平均到教师模型。
使用了KoLeo regularizer正则化,可以让一个batch内的特征分布更均匀。每次用KoLeo正则时,只用当前batch里所有样本的特征表示,计算它们两两之间的最近邻距离。例如,你的batch size=256,那么你有256个图片,每个图片经过网络后得到一个向量(比如128维)。此时,KoLeo正则会计算这256个向量之间的最近邻距离,然后用这些距离估算特征分布的“熵”。目标就是最大化这个熵,也就是让特征尽量分布开、覆盖整个空间,而不是都集中在某个角落。
那么有人可能会问了,DINO-v1中使用了更有效的裁剪方案,裁剪出两个大图和多个小图。而且只有大图被输入到了教师模型,大图和小图都被输入到了学生模型。DINO-v2里,用到了patch预测,那怎么计算小图的patch预测Loss呢?
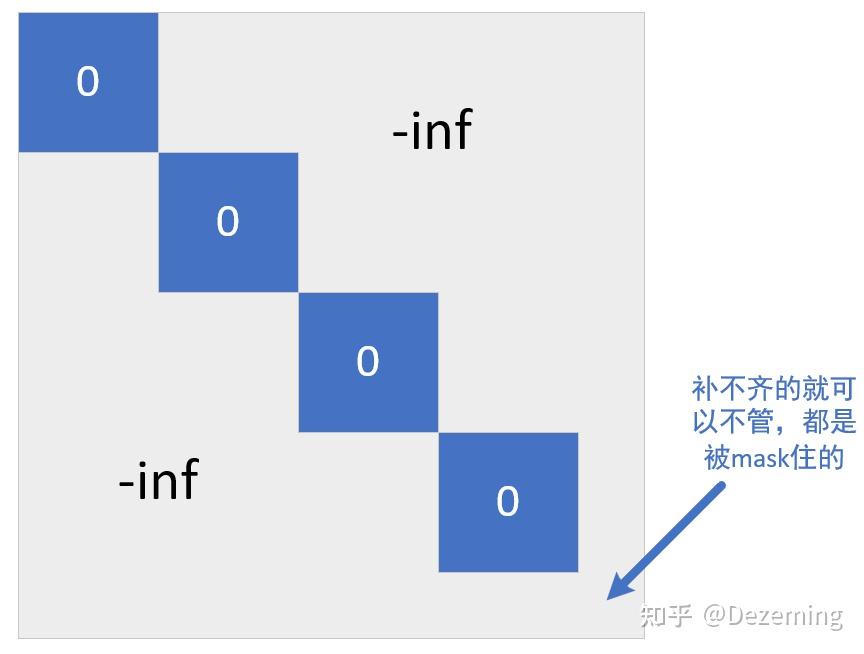
DINO-v2也会把小图输入到教师模型,而且处理了一个问题:batch内序列长度不一致。例如224x224的大图,得到196个小patch(16像素x16像素);96x96的小图,得到36个patch。DINO-v2选择将多个小图拼在一起,然后对注意力进行mask,使得小图之间互相不计算注意力。mask就是这个样子的(画个草图):
与iBOT的区别
下图很详细的展示了DINO-V2跟iBOT的区别:
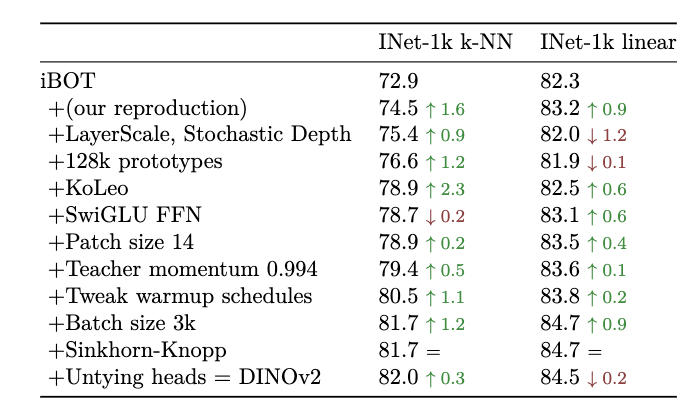
什么是Untying heads呢,就是iBOT认为预测CLS和预测patch的head要共享参数(使用同一个线性层)。DINO-v2发现数据量上去以后,用不同的head更好。所以就把CLS预测头和patch预测头解开(Untying)了。
我们可以看到,其实DINOv2就是数据增强,并加了一大堆trick的iBOT。SwiGLU FFN的意思是对Transformer模块的FFN层做SwiGLU激活(原版是ReLU激活)。FFN是作用在每个token上的(而非像自注意力矩阵那样作用于token之间),每个token使用相同的线性变换参数。之所以使用FFN主要是Transformer里其他的可训练参数太少了,增加个映射可以提高可训练参数量。
DINO-v2的内容就这么多,现在开始看最后一篇:VitNeedReg。
Vision Transformers Need Registers
值得一提的是,DINO系列和本文都是Meta的工作,属于是自己挖坑自己填了。
论文地址:[2309.16588] Vision Transformers Need Registers
这篇论文的发现和探索方法都很有意思,很值得读一读(而且读起来很简单)。
前面提到过,DINO将注意力进行了可视化。但是DINO-v2中发现里面有些乱七八糟的伪影(但是DINO-v1却没有),分布在本不该重点关注的区域:
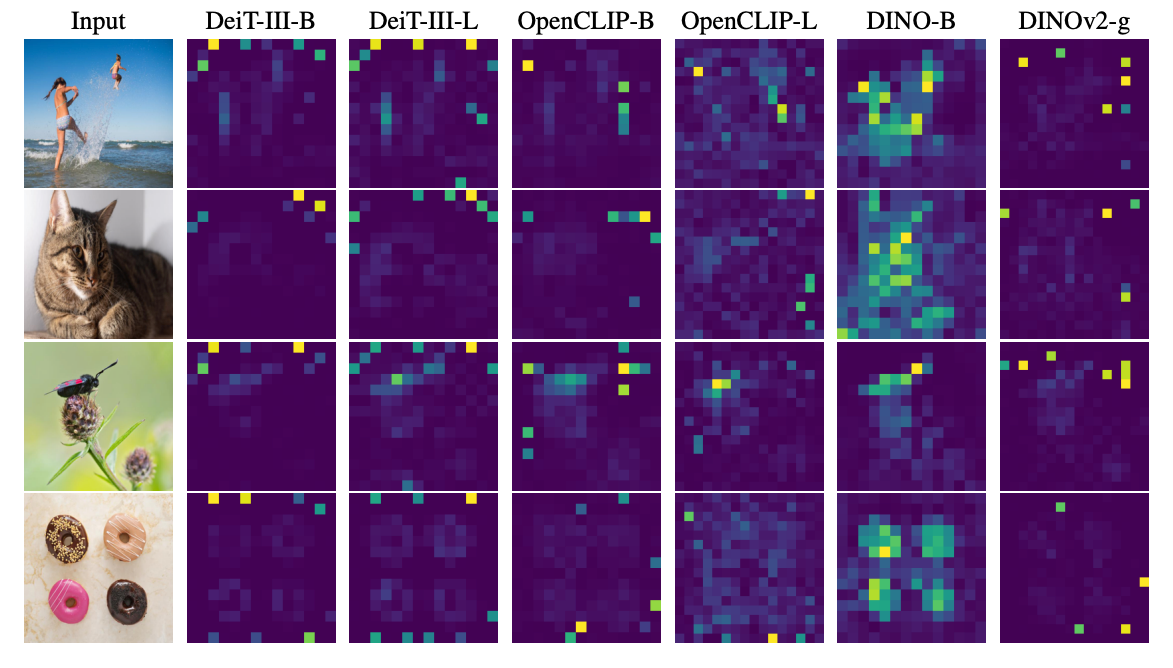
使用了文章提出的register以后,得到的特征就更符合理想的注意力分布了:
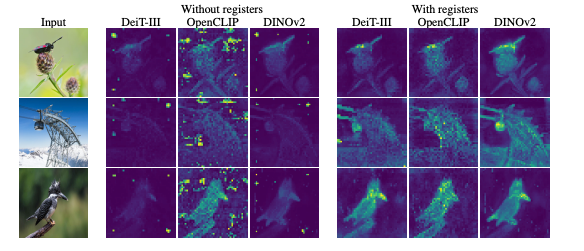
特征更规范有什么好处呢?当然是对下游任务所使用的特征更准确和有效了。
问题的发现与概览
DINOv2得到的特征成功地用于单目深度估计(DepthAnything系列就是基于DINOv2特征)和语义分割。尽管在密集任务上表现强劲,但作者们观察到DINO-v2与LOST(一种前景目标定位技术)非常不兼容。当用于提取特征时,它的性能比较差,在这种情况下只能跟有监督训练得到的网络作为骨干差不多。这表明DINO-v2的特征提取与DINO-v1不同。
作者发现,DINO-v2的特征图存在一些伪影,但这些伪影在DINO-v1中并不存在。这些可以通过直接的方法定性观察到。同样令人惊讶的是,将相同的观察结果应用于有监督的ViT会暴露出类似的伪影。这表明DINO实际上是一个例外,而DINOv2模型与ViT的baseline模型非常一致。
本文着手更好地理解这一现象,并开发检测这些伪影的方法。观察到在模型的输出处,这些伪影token的范数大约比其他区域高10倍,并且只对应于整个序列的一小部分(约2%)。本文还表明,这些token出现在ViT的中间层周围,并且只有在对足够大的ViT进行足够长的训练后才会出现。特别是,作者们发现这些异常token出现在与其邻域相似的patch中,这意味着实际上该patch传达的信息很少。
本文使用简单的线性模型来评估异常token,以了解它们所包含的信息。观察到,与非异常值token相比,它们在图像中的原始位置或patch中的原始像素的信息较少。这一观察表明,该模型在推理过程中丢弃了这些补丁中包含的局部信息。另一方面,在异常patch上学习图像分类器的准确性明显高于在其他patch上学习,这表明它们包含有关图像的全局信息。
由此,本文提出了以下解释:模型学习识别包含很少有用信息的patch,并回收相应的token来聚合全局图像信息,同时丢弃其空间信息(丢弃这些token的位置信息)。这种解释与Transformer模型中的一种内部机制是一致的,该机制允许在一组受限的token内执行计算。
为了检验这一假设,作者们将额外的token(称之为寄存器)附加到token序列中,这些额外的token与输入图像无关。训练了几个有和没有这种修改的模型,并观察到,有额外token的模型中,异常token完全从序列中消失了。因此,在密集的预测任务中,模型的性能会提高,得到的特征图也会明显更平滑。这些平滑的特征图使上述LOST等目标定位方法能够使用DINO-v2这种新模型。
实现原理
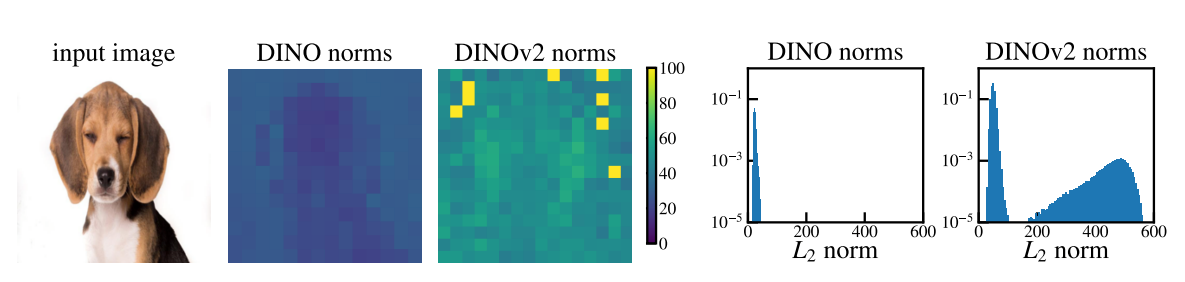
目标是希望找到一种定量的方法来表征出现在局部特征中的伪影。作者们观察到,“伪影”patch和其他patch之间的一个重要区别是它们在模型输出端的token embedding的范数。通过比较给定参考图像的DINO和DINOv2模型的局部特征范数,清楚地看到,伪影patch的范数远高于其他patch的范数。下图(右)中在较小数据集上的特征范数分布,这显然是双峰的,因此可以选择一个简单的标准(截断值):范数高于150的token将被视为“高范数”token,将研究它们相对于常规token的性质。这个手工选择的截断值可能因模型而异。
异常值出现在大型模型的训练过程中。对DINOv2训练过程中出现这些异常patch的条件进行了一些额外的观察,该分析如下图所示。
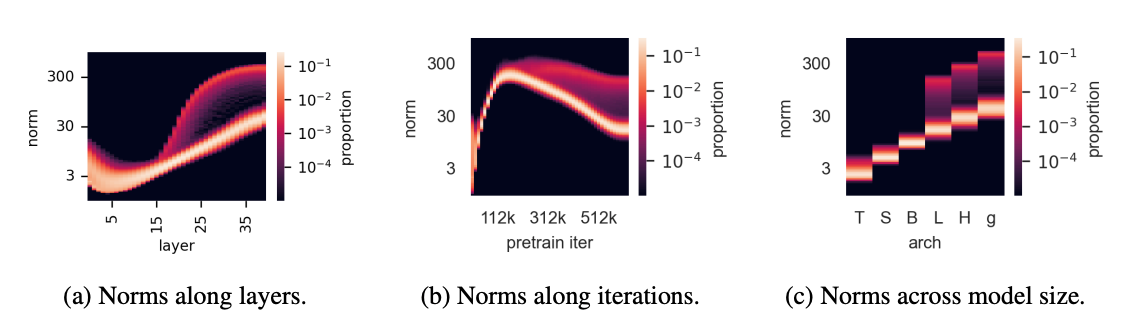
首先,这些高范数patch看起来好像将自己与第15层周围的其他patch区分开来(上图a)。其次,当观察DINOv2训练过程中的规范分布时,发现这些异常值仅在训练三分之一后出现(上图b)。最后,当更仔细地分析不同大小的模型(Tiny、Small、Base、Large、Huge和giant)时,发现只有三个最大的模型表现出异常值(上图c)。
高规范token出现在patch信息冗余的地方。为了验证这一点,作者们测量了高范数token与其4个邻域之间的余弦相似性,用于计算的特征就在patch embedding之后(在ViT的开始处)。下图a中展示了密度图。观察到,高范数token出现在与邻域非常相似的patch上。这表明这些patch抵消了冗余信息,模型可以在不损害图像表示质量的情况下丢弃它们的信息,这与它们通常出现在均匀背景区域的定性观察结果相匹配。高范数token几乎不包含局部信息。
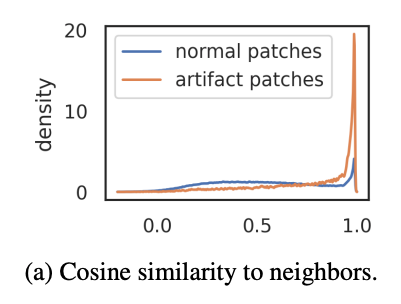
为了更好地理解这些token的性质,建议探索不同类型信息的patch embedding。为此,我们考虑两个不同的任务:位置预测和像素重建。对于每个任务,在patch embedding的基础上训练一个线性模型,并测量该模型的性能。比较了高范数token和其他token的性能,看看高范数token是否包含与“正常”token不同的信息。
- 位置预测。训练一个线性模型来预测图像中每个patch token的位置,并测量其准确性。注意这个位置信息是以绝对位置embedding的形式注入到第一个ViT层之前的token中的。观察到,高范数token的准确性远低于其他token(下图b),这表明它们在图像中的位置信息较少。
- 像素重建。训练一个线性模型来从patch embedding中预测图像的像素值,并测量该模型的准确性。再次观察到,高范数token的精度远低于其他token(下图b)。这表明高范数token比其他token包含更少的信息来重建图像。
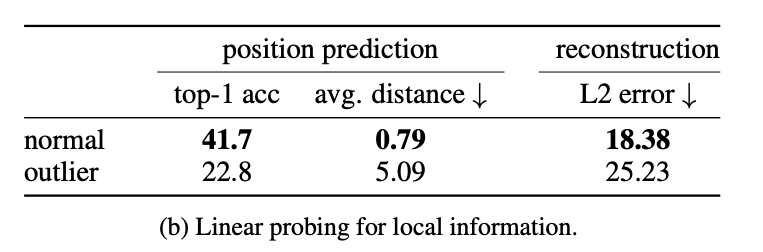
伪影区域保存着全局信息吗?为了评估高范数token中收集了多少全局信息,在标准的图像表示学习基准上对其进行评估。对于分类数据集中的每个图像,输入到DINOv2-g中,得到patch embedding。从输出中随机选择一个token embedding(既可能有异常范数,也可能有正常范数)。然后将此token视为其图像表示。然后,训练一个逻辑回归分类器,根据该token embedding预测图像类别,并测量准确性。观察到,高范数token的准确性比其他token高得多。这表明异常token比其他patch token包含更多的全局信息。

解决方案
简单来说,就是添加一些额外的token,网络输出时丢掉,这些token用于存放一些额外的信息。
在进行了上述观察之后,做出了以下假设:经过充分训练的大模型学会了识别冗余token,并将其用作存储、处理和检索全局信息的地方。此外,作者们假设,虽然这种行为本身并不坏,但发生在patch token上是不可取的。事实上,它导致模型丢弃了局部patch信息,可能会导致密集预测任务的性能下降。
因此,作者们提出了一个简单的解决方案:明确地向序列中添加新的token,模型可以学习将其用作寄存器。作者们在patch embedding之后添加这些token,这些token的值是可学习的,类似于[CLS]标记。在ViT结束时,这些token被丢弃,[CLS] token和patch token像往常一样用作图像表示。该机制其实首次在2020年的Memory Transformers中被提出,改进了NLP中的翻译任务。有趣的是,这里表明这种机制为ViT提供了自然的理由,解决了原本存在的可解释性和性能问题。
当前还无法完全确定训练的哪些方面导致了不同模型中伪影的出现。预训练的方案似乎发挥了作用,因为OpenCLIP和DeiT III在大小B和L上都表现出异常值。然而,本文发现模型大小和训练迭代次数也起着重要作用。
然后又做了一堆实验来验证。
总而言之,如果要自己去训练视觉大模型,就无脑加上这种方案吧~
CAPI
又是iBOT和DINO-v2大杂烩系列,MIM+蒸馏,而且也用了SwAV里的聚类思想,概念和技术越堆越多。文章发表在了很新的刚成立的期刊TMLR上:
[2502.08769v3] Cluster and Predict Latent Patches for Improved Masked Image Modeling
个体判别、MIM和聚类等都可以当做预训练方案。后面有时间的话,就把SwAV和CAPI拿出来讲一篇文章。
CAPI之前存在什么问题?简单来说,就是MAE和SimMIM这些基于掩码图像建模(MIM)的方法,虽然对设备和训练技巧的要求更低,但预测的特征效果不如基于对比学习的方法(例如DINOv2)。这篇文章希望能够训练一个更好的特征表示,希望不输于对比学习方案。
现有的MIM方法在表示质量上仍落后于其他自监督学习方法(如对比学习)。主要问题包括:
- 目标表示的局限性:传统的MIM方法通常直接预测像素值(如MAE)或依赖预训练编码器的潜在空间(如BeiT),前者过于低层次,后者需要额外的预训练模型。
- 训练不稳定性:基于在线潜在表示的MIM方法(如iBOT)虽然表现较好,但训练过程不稳定,需要额外的对比损失(如DINO)来稳定优化。
- 架构效率不足:现有方法在预测被掩码内容时,架构设计复杂且计算开销大(如融合编码器-解码器设计);测试中,MAE的解码器确实需要比较强大才行。
CAPI通过以下设计解决了上述问题:
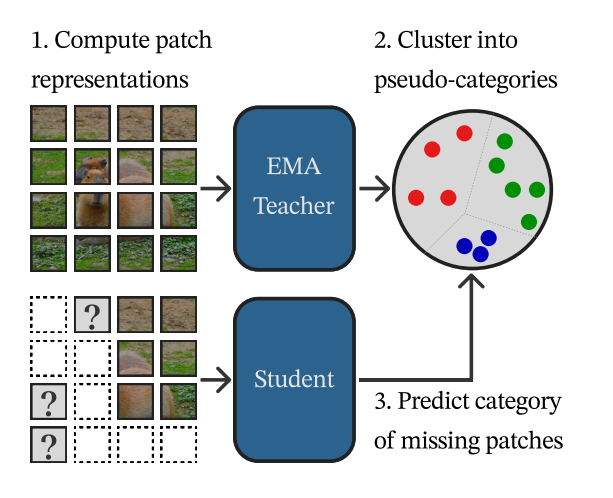
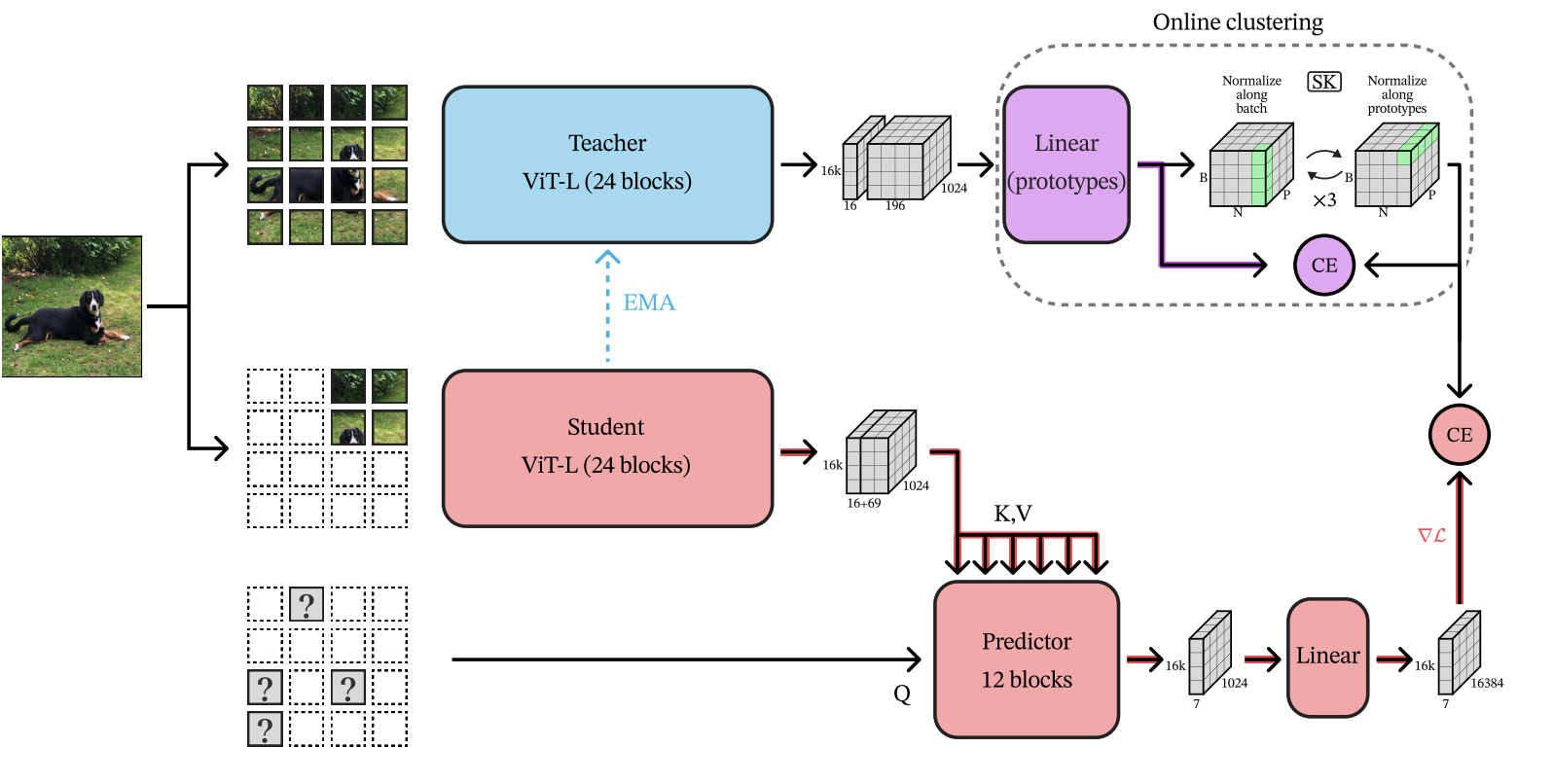
输入完整图像到教师模型(EMA编码器),提取所有图像块的潜在特征,对这些特征进行在线聚类(使用可学习的聚类中心,计算每个块属于每个中心的概率,因此叫软分配,软聚类)。学生模型预测掩码,输入掩码后的图像(部分块被随机丢弃)到学生模型(在线编码器+预测器)。 对每个被掩码的位置,预测其对应的聚类分配概率。既然是聚类分配概率,自然就可以用交叉熵了。
虽说表面上是“用MIM”战胜对比学习,但引入的聚类感觉并没有比DINO引入的对比损失简单多少吖!根据我的理解,这种方式已经不是所谓的MIM了。
详细点介绍改进方案:
- 聚类引导的目标表示,使用教师模型(EMA更新的在线模型)的潜在表示作为目标,并通过在线聚类将其转换为软分配(soft assignments)。模型可能仅通过位置编码(如图像块的坐标)预测聚类分配,而忽略内容信息。例如,所有左上角的块被分配给聚类A,右下角的块给聚类B,导致特征无意义。聚类过程采用Sinkhorn-Knopp算法平衡原型分配(每个聚类被分配的样本量接近均匀),避免空簇问题,同时消除位置信息对目标的干扰(解决“位置崩溃”问题)。这种设计使目标更具语义性,且无需依赖预训练模型。
- 轻量化的预测架构,提出一种基于交叉注意力的预测器,仅处理掩码标记([MSK]),通过交叉注意力访问可见标记的上下文。相比传统架构(如MAE的编码器-解码器),这种设计更高效,且支持独立预测每个掩码位置。
- 纯MIM损失函数:采用基于聚类的交叉熵损失,直接优化掩码位置的聚类分配预测,避免了iBOT中因目标与预测来源不同导致的分布不匹配问题。损失函数稳定,无需依赖额外的对比损失或数据增强。
不多讲了,有兴趣自己看看原文吧~
DINO v3
项目地址:DINOv3: Self-supervised learning for vision at unprecedented scale
论文地址:DINOv3 | Research - AI at Meta
一句话介绍DINO v3的技术:
DINO v3跟DINO v2的架构和预训练策略几乎完全一样:MIM(来自于iBOT的特征预测型MIM)+自蒸馏(来自于DINO v1)+多分辨率裁剪数据增强(来自于SwAV)+寄存器token(VitNeedReg)。并且加了一些额外的技术,使得能够有效训练超大模型,且训练得到的密集特征更有效。
概览
传统深度学习依赖大量人工标注数据,而自监督学习通过从数据本身生成监督信号(如图像块的关系、时序连续性等),彻底摆脱了这一限制。不局限于特定任务或领域,同一算法可处理多样数据(如自然图像、航拍图像等),为通用视觉表征学习铺平道路。模型和数据集规模可自由扩展,无需标注成本,适合大规模训练。
DINOv3的核心创新在于:
- 数据与模型规模的协同优化,通过精心设计的数据清洗、多样化和增强策略,确保大规模数据的质量。优化模型结构(ViT)以适应超大规模训练,平衡计算效率与表征能力。
- Gram锚定(Gram Anchoring),在长周期训练中,密集特征图(dense feature maps)易出现退化(如信息丢失或过度平滑)。通过Gram矩阵(捕捉特征间高阶统计量)锚定特征分布,稳定训练并提升特征质量。这一方法首次系统性解决了该长期存在的问题。
- 后处理策略(Post-hoc Strategies)。多分辨率适配支持灵活调整输入图像分辨率,适应不同计算需求。提供不同规模的模型变体(如小型到巨型),适配多样部署场景。
- ViT骨干也进行了改进,使用了axial RoPE位置编码,并且进行了位置编码正则化来避免位置伪影。
DINOv3的性能优势:
- 通用视觉基础模型:在无需微调的情况下,超越以往自监督/弱监督模型(如DINOv2、MoCo等)和领域专用模型(如ImageNet预训练模型)的性能。
- 密集特征质量:生成的高质量密集特征可直接用于分割、检测等任务,显著优于先前方法。
- 开源模型套件:提供不同规模的预训练模型(如Small到Large),推动社区在资源受限或高性能场景中的应用。
现有自监督方法的问题
自监督学习(SSL)的初衷是通过无约束的海量数据(无需标注)训练任意大规模的高性能模型,但实际规模化应用中存在多重障碍。
但存在模型不稳定与坍塌(Collapse)的情况。尽管DINO v2通过对比损失设计和正则化等方法缓解了部分问题,但进一步扩大规模时仍会出现新问题。例如,模型可能退化为输出常数特征(所有输入映射到相同点),完全丢失有用信息。
规模化过程中的三大具体问题:
- 无标注数据集的效用性问题,如何从无标注数据集中筛选“有用”数据?互联网爬取的原始数据包含噪声(模糊图像、重复内容、无关文本等),直接训练会降低模型效率。
- 训练调度的不确定性,余弦退火调度(Cosine Schedule)需预设总训练步数(优化终点),但在超大规模数据集(如数十亿图像)上难以提前确定最优步数(数据量过大时可能需动态调整),固定调度可能导致欠拟合或过拟合。
- 长周期训练中的特征退化,当模型参数量超过ViT-Large(3亿参数)且训练时间延长时,早期阶段特征质量提升,但后续相似度图(Patch Similarity Maps)显示特征逐渐退化(如过度平滑或丢失局部细节)。图像块之间的相似度趋于一致,失去判别性。根本原因在于优化目标与特征密度间的矛盾(如过度依赖全局一致性而忽略局部差异),大规模模型的优化轨迹具有复杂性(梯度噪声累积、损失曲面平坦化)。
这些问题导致单纯扩大DINOv2的规模(数据量、参数量)无法持续提升性能,甚至可能有害。
ViT的密集特征天生具有全局感受野,而CNN的密集特征受限于局部感受野。简单来说,你的ViT输出的图像特征是密集特征,以用于下游任务。但有可能学习到的每个patch的特征不是很有“独特性”,即所有patch的特征区分度很小,就不利于后续下游任务。
余弦退火调度是一种用于深度学习优化的学习率调整策略,其核心思想是让学习率随着训练过程按余弦函数的形式从初始值平滑衰减到接近零。这种调度方式在训练大规模模型时表现优异,尤其在自监督学习Transformer模型中广泛应用。
相似性图(Patch Similarity Maps)就是通过计算图像所有局部块(patch)特征之间的相似性(如余弦相似度),生成一个对称矩阵(或热力图),反映模型对图像内部结构的理解程度。
DINO v3的目标
- 强大多用途的基础模型
两大核心优势:模型规模与数据量的协同扩展,通过同时增大模型参数量和训练数据量(无标注、跨领域数据),实现通用表征能力的突破。冻结模型下的卓越性能,模型在不微调(frozen)的情况下,直接提取的特征即可达到与任务专用模型(如针对分类、分割单独训练的模型)相媲美的性能。节省计算资源(单次前向传播解决多任务),尤其适合边缘设备部署。无需元数据的训练流程,不依赖人工标注或结构化元数据(如标签、文本描述),仅需原始图像即可预训练,适用于科学领域(如遥感、医学)的稀缺数据场景。
跨领域泛化能力,下图显示,DINOv3对航拍图像提取的特征经PCA降维后,能清晰分离道路、房屋和植被,证明其特征具有高语义判别性和跨领域适应性。

- 密集特征质量的突破:Gram锚定技术
密集特征的矛盾优化目标:高层语义任务(如分类)需要全局抽象特征,而几何任务(如深度估计、3D匹配)依赖局部细节特征。大规模训练时,模型倾向于优先优化全局表征,导致密集特征退化(如过度平滑或信息丢失)。
Gram锚定通过约束特征Gram矩阵(高阶统计量)保持局部特征的多样性,避免崩溃。即使在高分辨率下(如细粒度分割),密集特征仍保持清晰(见下图,同语义特征相似性非常好)。支持“开箱即用”的密集预测任务(如无需复杂后处理)。

- 模型家族设计与蒸馏策略
超大规模模型训练,成功训练7B参数的DINOv3模型,验证了自监督学习在极大规模(比v2直接大了两个数量级)下的可行性。Gram锚定的关键作用:防止大模型长周期训练时的特征退化,使扩展真正带来性能提升。
蒸馏轻量化,7B模型计算成本高,难以直接部署到低级的消费级设备。因此,将大模型知识蒸馏到小模型(ViT Small, Base, and Large, as well as ConvNeXt-based architectures)。较小的模型,例如ViT-Large,在多数任务上接近7B教师模型的性能。提供多种尺寸的模型变体,适应不同资源限制(如移动端 vs. 云端)。
大尺度训练
数据规模
数据规模是大基础模型成功的关键,但单纯增加数据量并不自动提升模型性能。关键在于数据筛选策略,需平衡多样性(覆盖广泛的视觉概念)与实用性(与下游任务的相关性)。
DINOv3的数据构建方法:从约170亿张Instagram公开图片(已通过平台内容审核)中,通过三种互补策略构建数据集:
- 自动聚类均衡数据,基于DINOv2图像特征,使用分层k-means聚类,共5层(例如,最上层只区分动植物等;越往下区分越细,比如区分猫和狗)。确保数据覆盖所有视觉概念,避免长尾偏差(Long-Tail Bias,例如,你搜集的数据里猫狗非常多,但考拉和鸭嘴兽非常少,导致模型会疯狂学习猫狗的特征,但对考拉和鸭嘴兽几乎一无所知)。 最终筛选出16.89亿张图片,均衡覆盖各类别。
- 任务导向的检索数据,从海量数据中检索与种子数据集(如常见下游任务图片)相似的图像(比如卫星数据、医学影像等)。 这样能够增强模型在实用场景中的表现。
- 公开CV数据集,包含ImageNet-1k/22k、Mapillary街景序列等。 用于直接优化模型在标准基准上的性能。
简单概括,聚类法保证多样性与通用性, 检索法聚焦实用性与任务相关性。
由于DINOv3的预训练数据由多个不同来源的组件组成,需要设计策略如何混合这些数据以优化模型学习。类比一下,就是如何学好语文?广泛阅读+五年高考三年模拟做题(5/3真题)专精。
策略 | 原理 | 优缺点 |
|---|---|---|
同质批次(Homogeneous Batch) | 每个batch的样本全部来自单一数据组件(如仅ImageNet1k)。 | 优点:模型专注学习高质量数据特征; |
异质批次(Heterogeneous Batch) | 每个batch按比例混合所有数据组件(如90% LVD-1689M + 10% ImageNet1k)。 | 优点:增强泛化能力; |
DINOv3的混合采样方案受Charton & Kempe (2024)启发,研究发现,少量高质量数据的同质批次(如纯ImageNet1k)能显著提升模型性能。因此,采用了混合版本:90%的批次为异质混合(LVD-1689M + 检索数据 + 其他)+10%的批次为同质纯ImageNet1k。
类比:同质批次 ≈ 学生专注刷5/3真题(高质量定向训练);异质批次 ≈ 平时广泛阅读(提升综合素质)。
文中采用了数据消融实验设计用于验证数据筛选方法(聚类、检索、混合)的实际效果,消融实验 ≈ 控制变量对比“只刷题”“只阅读”“混合学习”的效果。表格如下:
数据集 | 构建方法 | 代表假设 |
|---|---|---|
原始数据池 | 未筛选的17B(170亿张)图片 | “数据越多越好”(朴素假设) |
仅聚类数据(LVD) | 分层k-means均衡采样 | “多样性优先” |
仅检索数据 | 任务相关相似性筛选 | “实用性优先” |
完整混合(DINOv3) | 聚类+检索+ImageNet混合采样 | “多样性+实用性平衡” |
缩短至20万次迭代(原计划100万次),加速验证。评估多个下游任务(分类、分割等)的平均性能。
得到的结论是,单一方法具有局限性。仅聚类数据在开放域任务(如物体检测)表现好,但在特定任务(如细粒度分类)较差;仅检索数据则相反,擅长特定任务,泛化能力弱。混合策略在所有任务上达到最佳平衡,验证了“多样性+实用性”联合设计的必要性。
大规模训练
25年(最近)一个工作,训练了7B参数的DINO v2,发现全局任务效果很好,但密集预测任务不太理想。关键是需要想办法让局部patch特征有区分度。
这里采用的损失函数包含了DINO v2的Loss \(\mathcal{L}_{DINO}\) 以及iBOT的Loss \(\mathcal{L}_{iBOT}\) 。但是把DINO的中心化步骤替换为了SwAV中的Sinkhorn-Knopp算法。这是是一种用于矩阵标准化(Matrix Scaling)的迭代方法,使得矩阵每行和每列的元素值的和都是 1。
意义是在自监督学习中,对齐不同视图的特征(例如让同一图像的两个裁剪视图的特征矩阵行/列和一致)。
Backbone网络(主干网络)提取通用特征,每个任务有独立的头部(Head),例如分类Head、分割Head、深度估计Head,每个Head接收Backbone的特征,并针对任务进行特征微调,再计算损失。对Backbone输出的局部裁剪(Local Crops,小图像块)和全局裁剪(Global Crops,大图像块)特征,分别应用独立的Layer Normalization。这是因为局部裁剪和全局裁剪的统计分布不同,独立归一化能更好保留各自特性。
然后使用了一个Koleo正则化项 \(\mathcal{L}_{Koleo}\) 。在自监督学习中,特征向量容易聚集在嵌入空间的狭窄区域(即"特征坍塌"),导致不同样本的特征难以区分;模型无法充分利用表示空间的容量。Koleo类似同名法国火车票品牌"Koleo",该正则化器强制特征在空间中像火车站点一样均匀分布。本质在于最小化特征向量间的互相关强度,使批量内样本的特征方向尽可能正交。
具体实现中,对batch中每对特征向量计算相似度(如余弦相似度),然后惩罚高相似度对,鼓励特征分散。对于分布式实现,采用小batch分组策略。单batch大小为16个样本(即使总batch_size很大);各GPU计算16样本的 \(\mathcal{L}_{Koleo}\) 后,梯度聚合。Sablayrolles等人已经证明小batch迭代仍能渐进实现全局均匀分布。
总损失:
Gram正则化
我常常想,如果DINO v2有一个特点,就是我在一张图选中一个patch的feature,例如一个细胞器;这个feature可以在本图上跟其他细胞器的feature几乎一致;但是否能够与其他图其对应的细胞器patch feature一致呢?这个特征究竟是基于每个图像得到的特征,只在一个图像上有一致性,还是能够在所有图像上都具有一致性?毕竟细胞图像好几万乘好几万大小的分辨率,编码器也不能一次就吃进去。
训练中的Patch一致性损失
长时间训练大规模视觉模型(如ViT-g和ViT-7B)时观察到的现象:全局指标(如分类准确率)持续提升,但密集预测任务(如分割)性能却显著下降。密集任务(如分割)依赖细粒度的patch特征,而分类任务依赖全局聚合特征(CLS token),两者表现出现分歧。在ImageNet-1k上训练的线性分类器(使用CLS token)的Top-1准确率随训练持续单调上升。在Pascal VOC上训练的线性分割头(基于patch特征)的mIoU在约200k次迭代后开始下降,ViT-7B的最终性能甚至低于早期水平。
通过patch特征相似性可视化(下图)发现早期200k迭代时,目标patch(红色标记)与其他patch的余弦相似性图看起来非常平滑且呈现局部化(集中在羊/花朵周围),表明patch特征具有空间一致性。后期600k+迭代后相似性图退化,大量不相关patch与参考patch的相似性异常升高。说明模型逐渐丢失patch级别的表征一致性,导致密集任务性能下降。
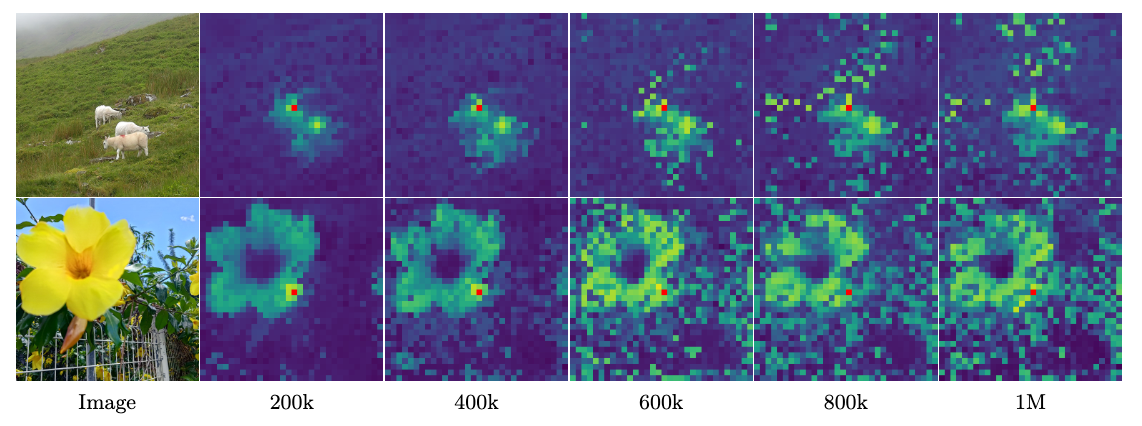
我猜测可能的原因是对比学习的目标造成的。例如特征过度全局化,长期训练可能使模型偏向捕获全局语义(利于分类),但牺牲局部细节(对分割关键)。优化目标冲突,对比学习任务的损失主导优化方向,导致patch特征退化。过拟合或表征坍缩,高维特征空间在长期训练中可能坍塌,失去局部判别性。
这里描述的现象可以概括为:在长时间训练视觉Transformer模型时,虽然全局表征(如CLS token)持续优化,但局部patch特征却逐渐失去区分度,导致密集预测任务性能下降。具体表现为三个关键发现:
- 与VitNeedReg (2024)的差异:此前工作观察到某些patch会出现异常高范数(high-norm outliers),但通过引入register tokens避免了这一问题——所有patch的范数保持稳定。
- 新出现的异常模式:尽管patch范数正常,但CLS token与patch特征的余弦相似度会随训练持续上升。这说明模型逐渐将patch特征向CLS token的全局表征方向对齐,而patch之间的局部区分度(locality)随之降低。可视化结果如下图显示,早期200k步patch特征具有空间局部性,而后期1M步相似度分布变得弥散。
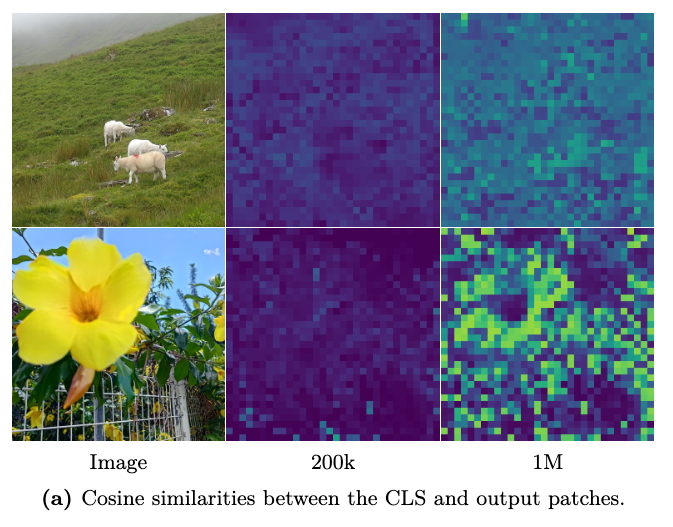
这一现象本质上揭示了视觉表征学习中全局与局部特征的优化存在竞争关系。长期训练可能使优化过程过度偏向全局表征,需要通过设计专门的损失函数来实现二者的平衡。由此,作者提出新的正则化目标,通过显式约束,保持patch特征的局部一致性(提升密集任务性能),同时不损害CLS token的全局表征能力(维持分类性能)。
Gram Anchoring Objective
Gram矩阵(即图像中所有patch特征两两点积构成的矩阵)广泛应用于早期风格迁移技术
作者提出了一种新的损失函数,旨在解决模型训练过程中patch特征一致性退化的问题,但巧妙的是,它并不直接约束特征本身,而是通过Gram矩阵来间接调控。
具体来说,该方法让学生模型(当前训练中的模型)的Gram矩阵向Gram教师(教师模型早期某个检查点)的Gram矩阵对齐。这里的Gram教师并非固定不变,而是选择教师网络在训练早期的一个状态,因为此时模型的patch特征通常具有更好的局部一致性和密集任务性能(注意教师模型是学生模型的指数移动平均得到的)。
如何通过Gram矩阵对齐来调整网络呢?
假如图像特征是 \(d\) 维,有 \(P\) 个patch,那么图像特征维度就是 \(P\times d\) 。设学生模型得到的特征记作 \(\mathbf{X}_{S}\) ,教师模型得到的特征记作 \(\mathbf{X}_{G}\) ,由此得到损失:
在1M次迭代以后,开始启动这个损失。注意, \(\mathbf{X}_{G}\) 每10k次才更新一次,此时跟当前的教师模型保持一致;然后继续保持不变,直到再训练10K次再更新。
总损失函数:
利用高分辨特征
最近的研究表明,通过对patch特征进行加权平均可以抑制异常patch的干扰,从而增强局部表征的一致性(Wysoczańska等人于2024年的研究,相当于对patch特征进行去噪滤波)。与此同时,向主干网络输入更高分辨率的图像能够生成更精细的特征图。本文巧妙地结合了这两个发现来为Gram教师模型生成高质量特征。
具体实现分为两个步骤:
- 高分辨率输入,首先将图像分辨率提升至常规尺寸的2倍(如512×512)输入Gram教师模型,获取更丰富的细节特征;
- 特征图下采样,对输出的高分辨率特征图进行双三次插值2倍下采样,既保持特征平滑性,又使其尺寸与学生模型输出匹配。
下图对比了三种情况下的Gram矩阵:常规分辨率(256)特征细节有限;高分辨率(512)特征展现更优的patch一致性;下采样高分辨率特征:保留高分辨率的优势,同时特征更平滑。
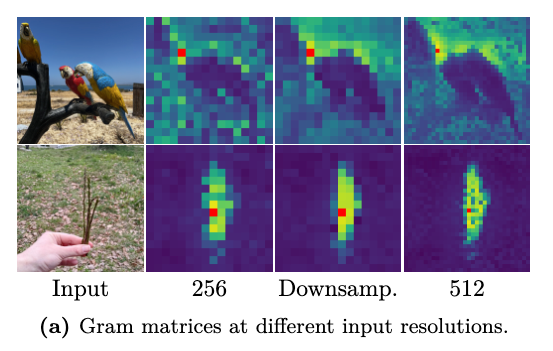
值得注意的是,由于采用了Su等(2024)提出的旋转位置编码(RoPE),本文提出的模型无需调整即可灵活处理任意分辨率的输入——这种特性就像给模型装了个"智能缩放镜",既能捕捉微观细节,又能自动适应不同尺度的需求。
Post-Training
不同分辨率的适应性
在实际应用中,许多任务需要处理更高分辨率的图像(如512×512像素或更大),以捕捉更精细的空间细节,而推理时输入的图像尺寸往往也不固定。为了解决这个问题,在训练中引入了一个高分辨率适应阶段:通过混合不同尺寸的全局和局部图像块(比如全局裁剪尺寸从{512, 768}中采样,局部裁剪尺寸从{112, 168, 224, 336}中采样)进行小batch训练,并额外迭代1万次。这个阶段的核心是加入了Gram锚定技术——以7B参数的教师模型作为Gram教师,强制模型在不同分辨率下保持特征空间关系的一致性。实验证明,如果没有这个关键设计,模型在密集预测任务上的性能会大幅下降。
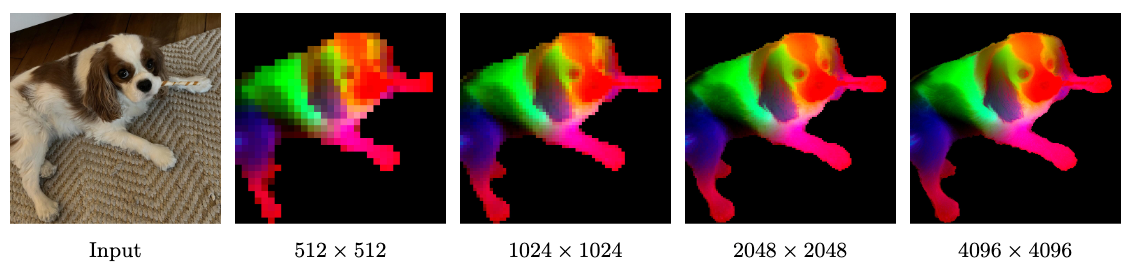
经过这个简短但针对性的高分辨率适应后,模型整体质量显著提升,能够泛化到各种输入尺寸。模型能有效利用更大尺寸图像提供的丰富空间信息。有趣的是,适应后的模型甚至能稳定处理远超训练分辨率(768像素)的4K级图像,展现出强大的泛化能力:
模型蒸馏
通过知识蒸馏将ViT-7B大模型压缩成更小的视觉Transformer变体。
具体做法是直接固定ViT-7B作为教师模型来指导学生模型训练(不再使用滑动平均权重),并沿用第一阶段的训练目标。由于小模型没有出现大模型那种patch特征一致性问题,因此不需要引入Gram锚定技术。通过这种方式,蒸馏得到的小模型既能继承大模型的强大表征能力,又大幅降低了计算开销。
最终得到一系列覆盖不同算力需求的模型:标准版的ViT-S(2100万参数)、ViT-B(8600万)、ViT-L(3亿),以及两个定制版ViT-S+(2900万)和ViT-H+(8亿)——后者性能已接近自蒸馏的7B教师模型。实验表明,经过100万次主训练和25万次学习率退火后,这些小模型仅用少量计算就能达到前沿性能。最后还会对它们进行前述高分辨率适应训练(但不使用Gram锚定),使它们具备处理多尺度图像的能力。
为了降低教师模型推理带来的高昂计算成本,设计了一个并行蒸馏方案,可以同时训练多个学生模型,并让所有参与训练的GPU节点共享同一个教师模型的推理结果。
具体来说,在单教师单学生的标准蒸馏中,每块GPU需要承担 \(B/N\) 大小的数据切片对应的教师推理(成本 \(B/N \times C_{T}\) )和学生训练(成本 \(B/N×C_{S}\) )。而多学生蒸馏方案是这样运作的:首先将每个学生 \(Si\) 分配到 \(N_{Si}\) 块GPU上进行训练,所有 \(NT=\Sigma_{N_{Si}}\) 块GPU组成全局推理组。每一步迭代时,先在全局组上运行教师推理(每块GPU成本降至 \(B/N_T \times C_T\) ),然后通过All-Gather集合通信同步输入数据和推理结果,最后各学生组独立进行训练(每块GPU成本 \(B/N_{Si}\times C_{Si}\) )。
这种设计带来两个关键优势:
- 增加学生数量会降低每块GPU的单步计算量,从而提升整体蒸馏速度;
- 由于教师推理成本被固定分摊,新增学生仅带来其训练部分的额外计算。
实际实现时只需精心设置GPU进程组,并调整数据加载器和教师推理流程以保持跨组同步。为了让各学生组迭代速度均衡,会动态调整各学生分配的GPU数量。通过这种流水线,高效地一次性从7B教师模型蒸馏出了整个轻量级模型家族。
文本对齐
简单来说,DINOv3 并没有像原始 CLIP 那样从头开始训练视觉和文本编码器,而是利用了 LiT (Locked-image Tuning) 的思路:冻结已经训练好的强大视觉模型(DINOv3),只训练文本端来“对齐”它。
- 原始 CLIP 的局限性:
CLIP虽然在 Zero-shot 分类上很强,但它主要学习的是全局对齐。
这意味着 CLIP 擅长判断“这张图里有一只猫”,但不擅长捕捉“细粒度(Fine-grained)”或“局部(Localized)”的对应关系(比如猫的耳朵在哪里)。
- 自监督视觉模型的潜力:
DINOv3 作为一个自监督视觉模型,已经学习到了非常好的视觉特征。与其像 CLIP 那样重新训练一个视觉编码器,不如直接利用 DINOv3 现成的特征。这不仅节省计算成本,还能继承 DINOv3 在局部特征上的优势。
核心方法:LiT 范式与特征融合
DINOv3 采用了 Jose et al. (2025) 提出的策略,具体包含以下几个关键技术点:
- 训练范式:LiT (Locked-image Tuning)
- Vision Encoder:冻结(Frozen)。直接使用预训练好的 DINOv3 骨干网络。
- Text Encoder:从头训练(From Scratch)。
- Adapter:为了让冻结的视觉特征能更好地适应图文对齐任务,他们在冻结的骨干网络之上添加了 2 层 Transformer Layers*作为可学习的适配器。
- 特征聚合策略 (The "Secret Sauce")
通常的 CLIP 模型只使用 [CLS]token 作为图像的特征表示:
DINOv3 的做法是:将 [CLS]token 与 Patch tokens 的平均池化(Mean-pooled)进行拼接(Concatenation):
- \(\boldsymbol{x}_{\text{[CLS]}}\):负责捕捉全局语义(Global Semantics),例如“这是一张公园的照片”。
- \(\frac{1}{N} \sum \boldsymbol{x}_{\text{patch}}\):负责聚合局部细节(Local Visual Features),保留了更多的空间和纹理信息。
这种设计直接解决了传统 CLIP 在稠密预测任务(Dense Prediction Tasks)上的短板。
- 全局+局部双重对齐:通过拼接两种特征,文本编码器被迫同时学习图像的整体概念和局部细节。
- 无需额外技巧:很多以前的方法为了做开放词汇分割(Open-vocabulary Segmentation),需要设计复杂的掩码(Masking)或注意力机制。DINOv3 证明,只要把 Patch 特征和 CLS 特征结合起来去对齐文本,模型就能自然地获得极强的稠密预测能力。
- 高效性:因为视觉骨干是冻结的,训练开销主要在文本端和那两层 Transformer 上,比从头训练 CLIP 快得多。